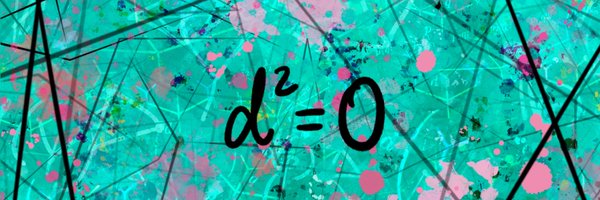

Tai-Danae Bradley
@math3ma
Followers
20K
Following
2K
Media
308
Statuses
2K
Ps. 148 • mathematician at SandboxAQ • blogger at Math3ma • visiting prof at TMU + Math3ma Institute: @math3ma_inst
Joined August 2014

Not too long ago, my collaborators and I wrote a preprint on the problem of uploading classical data onto a quantum computer, from a more mathematical (& category theoretical) perspective. I finally got around to blogging about the ideas. New series is up!

math3ma.com
Over the past couple of years, I've been learning a little about the world of quantum machine learning (QML) and the sorts of things people are thinking about there. I recently gave an high-level...
1
7
48
RT @QuantaMagazine: The mathematician Tai-Danae Bradley is using category theory to try to understand how words come together to make meani….

quantamagazine.org
The mathematician Tai-Danae Bradley is using category theory to try to understand both human and AI-generated language.
0
70
0
10 years ago today, I launched the Math3ma blog. At the time, I wasn’t sure the site would resonate with anyone, but I’ve been amazed by all that’s happened over the past decade! To celebrate, here’s a new post on category theory and language models 🥳

math3ma.com
It's hard for me to believe, but Math3ma is TEN YEARS old today. My first entry was published on February 1, 2015 and is entitled "A Math Blog? Say What?" As evident from that post, I was very unsure...
8
24
155
We wrote our preprint to (hopefully) be self-contained, so you don't really need to know about category theory to follow it. But hopefully this thread is a little helpful, too. 19/19.
3
0
11
Oh, and so far, there are 100+ papers on magnitude, which is pretty neat. Tom Leinster is keeping track on his website — check out more here! . And here: 18/

1
0
8
Prop. 4 is our result on mag. homology: it says the magnitude function (a sum of Tsallis entropies) of the enriched cat. of texts is a weighted sum of Euler characteristics. I think this is a nice little connection bw information theory and algebraic topology! cf our Rmk 3. 17/

1
1
10
Now, magnitude is a numerical invariant, but there's also a more algebraic invariant called magnitude homology. Leinster and Shulman also wrote about this in their 2020 paper I mentioned above. So we include some remarks on the magnitude homology of our setting, as well. 16/.
1
0
7
Now, if you introduce a parameter t (say, to scale your metric space) you get a magnitude *function*. We find the magnitude function of the enriched cat associated to an LLM is a sum of Tsallis entropies over inputs to the model, plus a number, which I won't get into here. 15/

1
1
8
So, we apply his combinatorial method to our generalized metric space of texts to see what we get. That's what our preprint is about: . 14/.
1
0
8
But one thing we didn't do in 2021 was compute the magnitude of this enriched category. That's what the new preprint is about. In 2024, Juan Pablo introduced a combinatorial way to compute magnitude, which is different from the usual construction: 13/

1
1
10
There's lots more you can do with this categorical framework of language, btw, e.g. finding sth like meaning representations for texts and combing them in ways akin to logical operations. I recently gave an introductory talk at IPAM at UCLA on this: 12/.
1
0
11
This idea was introduced in a 2021 paper I coauthored with John Terilla and Yiannis Vlassopoulos, but we didn't construct the π explicitly from an LLM at that time:. “An Enriched Category Theory of Language” arXiv version: 11/

1
0
8
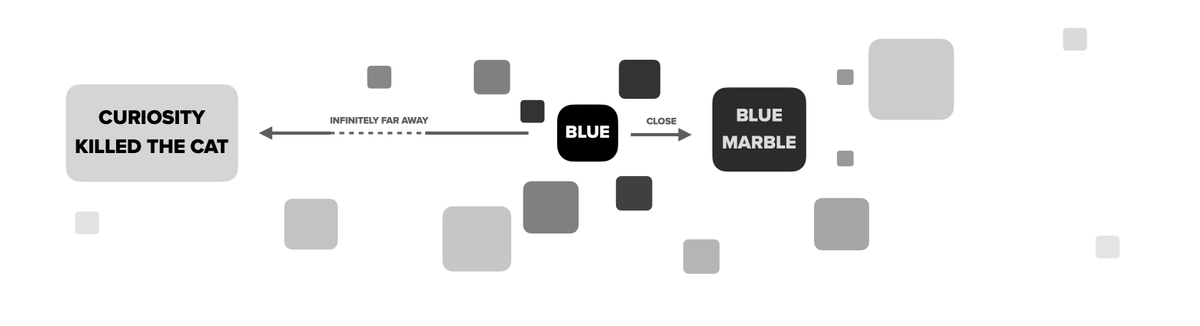
From this perspective, likely continuations of an input string x are close to it, and strings that aren't continuations of x are infinitely far away. This is the sense in which language is a generalized metric space. 10/
1
1
10
. where, loosely speaking, think of π(y|x) as like the “conditional probability” of generating y given the input x. We define it much more precisely, using probabilities generated from an LLM, in Definition 2 in the preprint: 9/
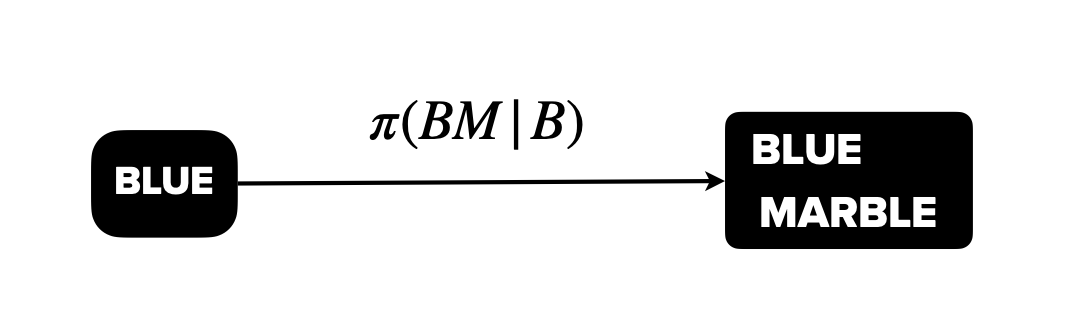
1
0
9
So, what does this have to do with LLMs? There's an easy way to get a generalized metric space from an LLM. The points are strings (say, up to a fixed length) x, y,. of symbols fr a finite set (eg tokens). The distance bw two strings is defined to be. d(x,y) = -ln(π(y|x)). 8/.
1
1
9
(There's a lot of interesting history behind this, connecting ideas from posets and topology and category theory. For more, see this paper by Leinster and Meckes: and Ch. 6.4 of Leinster's great book, "Entropy and Diversity" ). 7/

1
0
14
In 2017 Tom Leinster and Mike Shulman gave a more general def'n of magnitude for enriched categories that subsumes the metric space version: In short, they express the mag. of an enriched cat. in terms of sth like an Euler characteristic, cf Thm 7.14. 6/

1
1
9
John Baez also has a really nice intro to categories enriched over [0,∞], where he calls them “Cost-enriched categories,” thinking of the distance from here to there as a kind of *cost*. Here’s the first in a series of articles by Baez on this: 5/.
1
0
10
As you'll see there, "a category enriched over [0,∞]" is like a poset where the ≤ are decorated by distances bw points. Except, you don't require symmetry or positivity. This is called a *generalized* metric space. So, enriched categories in this context are pretty simple. 4/

1
0
8