
Mannat Singh
@mannat_singh
Followers
396
Following
5K
Media
19
Statuses
65
Research Engineer, GenAI, @Meta.
Manhattan, NY
Joined December 2010
Great work led by Qihao Liu during his internship with our team @xi_yin_, @Andrew__Brown__, and @YuilleAlan . And props to Qihao for a github release ( with a complete reproduction + releasing models trained on public datasets.
github.com
[CVPR2025] PyTorch-based reimplementation of CrossFlow, as proposed in 'Flowing from Words to Pixels: A Noise-Free Framework for Cross-Modality Evolution' - qihao067/CrossFlow
0
0
18
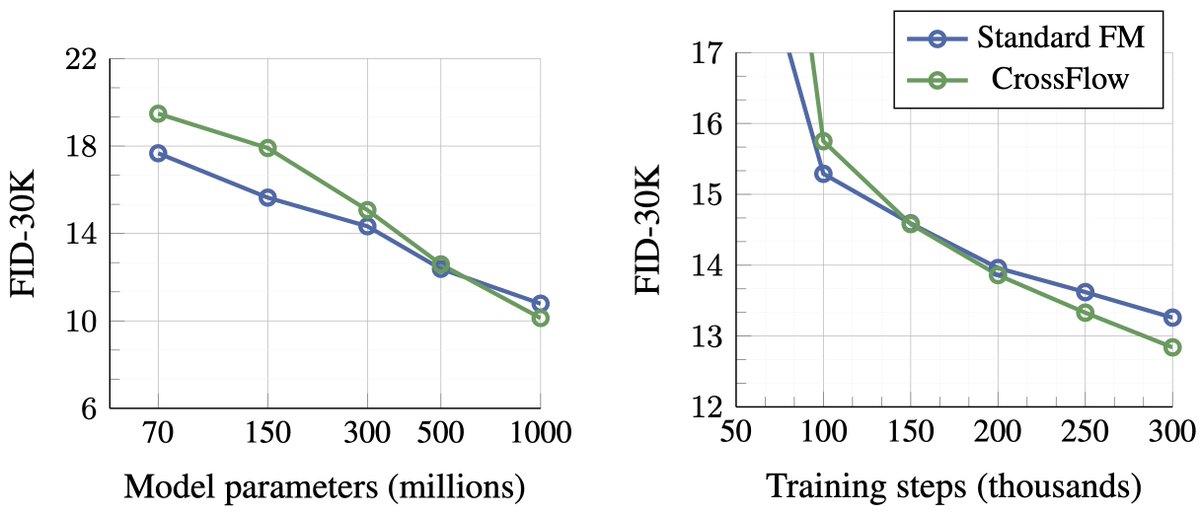
In fact, we find that this simple design scales *even better* than conventional FM with both model size and training steps. Lots of other details, like enabling CFG, the importance of a Variational Encoders in the paper (.
1
0
11
All this is accomplished by a simple modeling pipeline: we show that the input distribution needs to be regularized, and apply a Variational Encoder to the text embeddings. This latent is then evolved via FM to an image latent via a vanilla transformer with *no cross-attention*.

1
0
8
This is cool, but does it work well? Yes! .We show that our approach works well and is par with / outperforms SOTA on a variety of tasks, specifically:.1. Text-to-image.2. Image-to-depth.3. Image-to-text.4. Image super-res




1
0
11
This enables some cool applications, like latent arithmetic:. 1. latent("A white dog wearing a black hat") . latent("Sunglasses") .-latent("A hat").--> An image of a dog with sunglasses without the hat. 2. Interpolate between two text latents --> the image changes smoothly!




1
0
12
Flow matching can transform one distribution to another. So why do text-to-image models map noise to images instead of directly mapping text to images? .Wouldn't it be cool to directly connect modalities together? CrossFlow accomplishes exactly that!

2
44
325
RT @AIatMeta: As detailed in the Meta Movie Gen technical report, today we’re open sourcing Movie Gen Bench: two new media generation bench….
0
223
0
Finally @_rohitgirdhar_ and I can talk about our detour into Llama 3 video understanding. You need to understand videos (and caption them 💬) to generate good quality videos! 🐨
0
0
4
Check out Movie Gen 🎥 Our latest media generation models for video generation, editing, and personalization, with audio generation!.16 second 1080p videos generated through a simple Llama-style 30B transformer. Demo + detailed 92 page technical report 📝⬇️.

🎥 Today we’re premiering Meta Movie Gen: the most advanced media foundation models to-date. Developed by AI research teams at Meta, Movie Gen delivers state-of-the-art results across a range of capabilities. We’re excited for the potential of this line of research to usher in
1
1
16
Llama 3.1 is out! Through adapters we've made it multimodal, supporting images, videos, speech!. Was a fun journey adding video understanding capabilities with @_rohitgirdhar_, @filipradenovic., @imisra_ and the whole MM team! . P.S. MM models are WIP.(not part of the release).
Starting today, open source is leading the way. Introducing Llama 3.1: Our most capable models yet. Today we’re releasing a collection of new Llama 3.1 models including our long awaited 405B. These models deliver improved reasoning capabilities, a larger 128K token context
1
5
23
Feels great to have been recognized as an outstanding reviewer for CVPR this year 🤩.

1
0
16
Also check out animate in Meta AI, which builds on top of our prior research on Emu Video and brings your pictures to life! 📹.
Want to try these updated Imagine features in Meta AI? More details ⬇️.
0
1
2
Llama 3 is out! Super fortunate to be part of the incredible effort! Also can't wait to share some of our work which is still in progress! 🦙🦙🦙.
Introducing Meta Llama 3: the most capable openly available LLM to date. Today we’re releasing 8B & 70B models that deliver on new capabilities such as improved reasoning and set a new state-of-the-art for models of their sizes. Today's release includes the first two Llama 3
1
0
6
Now added ViT-6.5B MAE + MAWS models, and ImageNet-1k finetuned checkpoints. Strong foundational models at all sizes: <100M to >6.5B params. Best public perf on ImageNet-1k linear/finetuned, ImageNetv2, ImageNet-ReaL, low-shot ImageNet-1k & iNaturalist-18.

github.com
Code and models for the paper "The effectiveness of MAE pre-pretraining for billion-scale pretraining" https://arxiv.org/abs/2303.13496 - facebookresearch/maws
Excited to present our work, "The effectiveness of MAE pre-pretraining for billion-scale pretraining" ( at #ICCV2023 today. Our strong foundational MAWS models, with multilingual CLIP capabilities, are now available publicly at
0
0
10
RT @_rohitgirdhar_: Excited to share what we've been up to this year: Emu Video! A SOTA video generation system from text or images. In spi….
0
23
0
Work done with an incredible team @_rohitgirdhar_ , @Andrew__Brown__ , @quduval , @smnh_azadi , @rssaketh , Akbar Shah, @xi_yin_ , @deviparikh , @imisra_ !!!.
0
1
10
Animating the New York city skyline with "The sun sets and the moon rises"
1
0
4
"A polar bear swimming energetically underwater to catch fish, photorealistic"
1
0
2
Animating a picture of the moon landing with "The American flag waving during the moon landing with the camera panning"
1
0
2
"There's a dog with a harness on that is running through an open field and flying a kite."
1
1
7