

LCS2 Lab
@lcs2lab
Followers
1K
Following
234
Media
145
Statuses
542
Lab. for Computational Social Systems, a group led by @Tanmoy_Chak working on #SocialComputing #GraphMining & #NLProc
New Delhi, India
Joined July 2018
💡 By reframing #TaxonomyExpansion as lineage-oriented #Reasoning, #LORex moves beyond brittle pipelines. Structured knowledge deserves structured thinking. #KnowledgeGraphs #NLProc.
0
0
0
📝 Rank, Chunk and Expand: Lineage-Oriented Reasoning for Taxonomy Expansion.👥 Sahil Mishra @sahilmishra0012, Kumar Arjun, Tanmoy Chakraborty @Tanmoy_Chak .📌 Paper: 💾 Code:

aclanthology.org
Sahil Mishra, Kumar Arjun, Tanmoy Chakraborty. Findings of the Association for Computational Linguistics: ACL 2025. 2025.
1
1
1
🚨 New #ACL2025Findings Paper 🚨.How can we accurately grow taxonomies without brittle heuristics or finetuned LLMs? Our new work introduces LORex, a plug-and-play framework that combines discriminative ranking with generative reasoning to expand taxonomies scalably & faithfully.

1
0
3
RT @Tanmoy_Chak: I am attending #ACL2025. Happy to catch up to discuss our lab's work (@lcs2lab) and opportunities at @iitdelhi. I also lo….
0
3
0
📌 Can we trust a model that gets the right output for the wrong reason? As KD becomes standard for compressing LMs, understanding how knowledge transfers is vital. Our findings urge a rethink of trust and interpretability in distilled models. #ACL2025 #NLProc #TrustworthyAI.
0
0
0
🧠 Distilling into larger students yields limited gains. But more crucially, many students produce the correct answers without replicating the teacher’s reasoning. This exposes a key dissonance: KD boosts accuracy, but not necessarily reasoning fidelity.
1
0
0
📈 We conduct a large-scale study distilling 7B–14B LMs into 0.5B–7B models on 14 complex zero-shot reasoning tasks. KD boosts small model performance by up to 10%. However, teacher size ≠ student performance. Task-specific expertise matters more.
1
0
0
📝 On the Generalization vs Fidelity Paradox in Knowledge Distillation.👥 Suhas Kamasetty Ramesh, Ayan Sengupta @ayans007, Tanmoy Chakraborty @Tanmoy_Chak .📌 Paper: 💾 Code:

aclanthology.org
Suhas Kamasetty Ramesh, Ayan Sengupta, Tanmoy Chakraborty. Findings of the Association for Computational Linguistics: ACL 2025. 2025.
1
1
2
📢 New #ACL2025Findings Paper 📢.Can smaller language models learn how large ones reason, or just what they conclude? Our latest paper in #ACLFindings explores the overlooked tension in #KnowledgeDistillation - generalization vs reasoning fidelity. #NLProc

1
0
2
☑️ HiPPrO outperforms LLMs like GPT-3.5 and GPT-4 in producing more aligned, controllable, and contextually appropriate counterspeech, while remaining #lightweight and #efficient.
0
0
0
🧠 Using a two-stage architecture, HiPPrO generates responses that reflect both the speaker's intent (like questioning or denouncing) and the emotional tone (like anger or joy), making it far more human-like and impactful in tone-sensitive contexts like #hatemitigation.
1
0
0
📝 Counterspeech the Ultimate Shield! Multi-Conditioned Counterspeech Generation through Attributed Prefix Learning .👥 @aswiniandpunter, @anilHHH87, @Tanmoy_Chak .💾 Code: #ResponsibleAI #HateSpeech #ContentModeration.

aclanthology.org
Aswini Kumar Padhi, Anil Bandhakavi, Tanmoy Chakraborty. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025.
1
1
1
🚀 #ACL2025 Sneak Peek 🚀.As online hate continues to challenge platforms and communities, our lab takes a meaningful step forward with HiPPrO, a new framework for generating controlled, constructive #counterspeech 🛡️.#NLProc #AIResearch

1
0
3
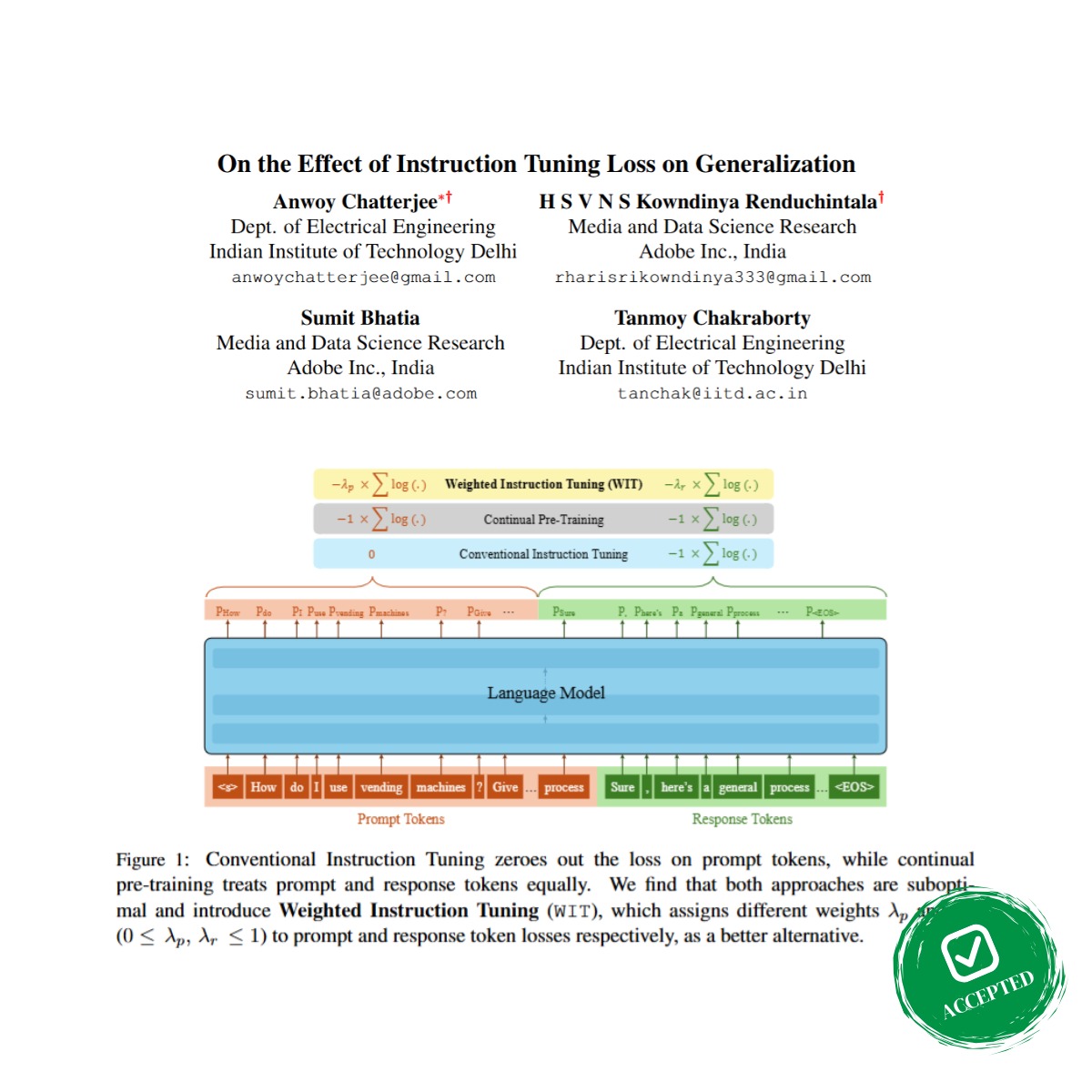
📝 On the Effect of Instruction Tuning Loss on Generalization.👥 Anwoy Chatterjee @anwoy_, Kowndinya Renduchintala @KowndinyaR, Sumit Bhatia, Tanmoy Chakraborty @Tanmoy_Chak.💾 Code: #MachineLearning #NLP #LLMs #TACL.

arxiv.org
Instruction Tuning has emerged as a pivotal post-training paradigm that enables pre-trained language models to better follow user instructions. Despite its significance, little attention has been...
0
2
7
🚨 New #TACL Paper Alert 🚨.We explore a crucial question in instruction tuning: should we weight prompt and response tokens differently in the loss function?.Introducing Weighted Instruction Tuning - a simple idea that boosts generalization by up to +6.55% across 5 benchmarks!
1
2
5
📜 Step-by-Step Unmasking for Parameter-Efficient Fine-tuning of Large Language Models.👥 @AradhyeAgarwal, Ayan Sengupta, Suhas K Ramesh, @Tanmoy_Chak .💾 Code: 📌 Paper: #LLMs #NLProc #PEFT #LoRA #Adapters #AIResearch.
arxiv.org
Fine-tuning large language models (LLMs) on downstream tasks requires substantial computational resources. Selective PEFT, a class of parameter-efficient fine-tuning (PEFT) methodologies, aims to...
0
0
2
