

John T Davies 🇺🇦🇪🇺🌍
@jtdavies
Followers
2K
Following
14
Media
612
Statuses
4K
Entrepreneur, CTO in Gen-AI, investor, father to 3 grown boys, husband to Rachel, astrophysicist, keen photographer, cyclist, über-geek, travelled a lot.
West London, England
Joined August 2008
Ok, this is old news in AI terms but I read Sam’s claim “and a smaller one that runs on a phone”. Ternary quantisation (1.58 bit) would leave you with a 4 to 5GB model, especially without the Phi 4 tokeniser. So I guess it’s technically feasible.

gpt-oss is out!. we made an open model that performs at the level of o4-mini and runs on a high-end laptop (WTF!!). (and a smaller one that runs on a phone). super proud of the team; big triumph of technology.
1
0
1

Here we go again, I guess the @Alibaba_Qwen team worked through the weekend, we have Qwen-Image. As usual, competing more than favourably against SOTA models like FLUX, GPT and BAGEL, great text rendering too.

0
1
1
Next week (of 11th) I will be in New York. I would love to catch up with my (old) fintech colleagues and anyone deep into AI. Please DM me and I’ll arrange a meet-up one evening. Week of 18th in the Bay Area.

0
1
0
Why not just buy some Mac Minis and use the Qwen3-Coder-30B model on MLX? You have a more scalable cost model.

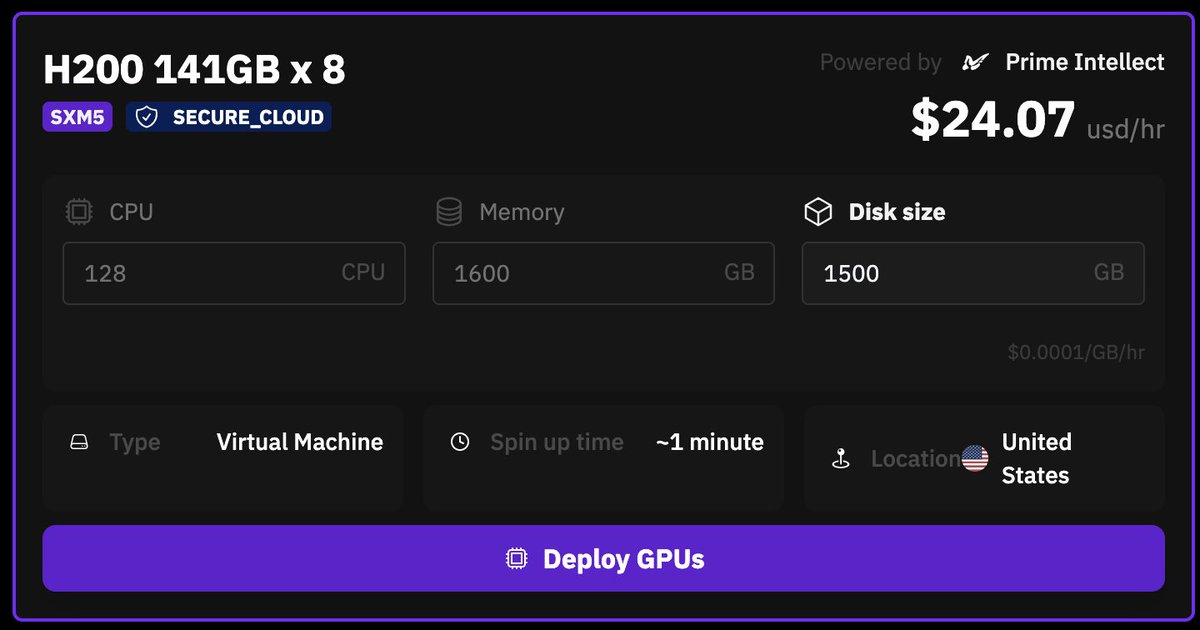
What if we just rented a single H200 node from @PrimeIntellect and serve Qwen3-Coder-480B-A35B model!. Cost: ~$17k/month. We only need 280 people paying $60/month to cover it. Let’s crowd-power next-gen AI together. Who’s in?
3
0
3
If this is OpenAI’s new OS model it’s going to be tough to run on anything but a top spec machine. It will be interesting to see (if it’s real) how it stacks up to the Qwen3 models. Either way, it will be welcome.

0
0
1
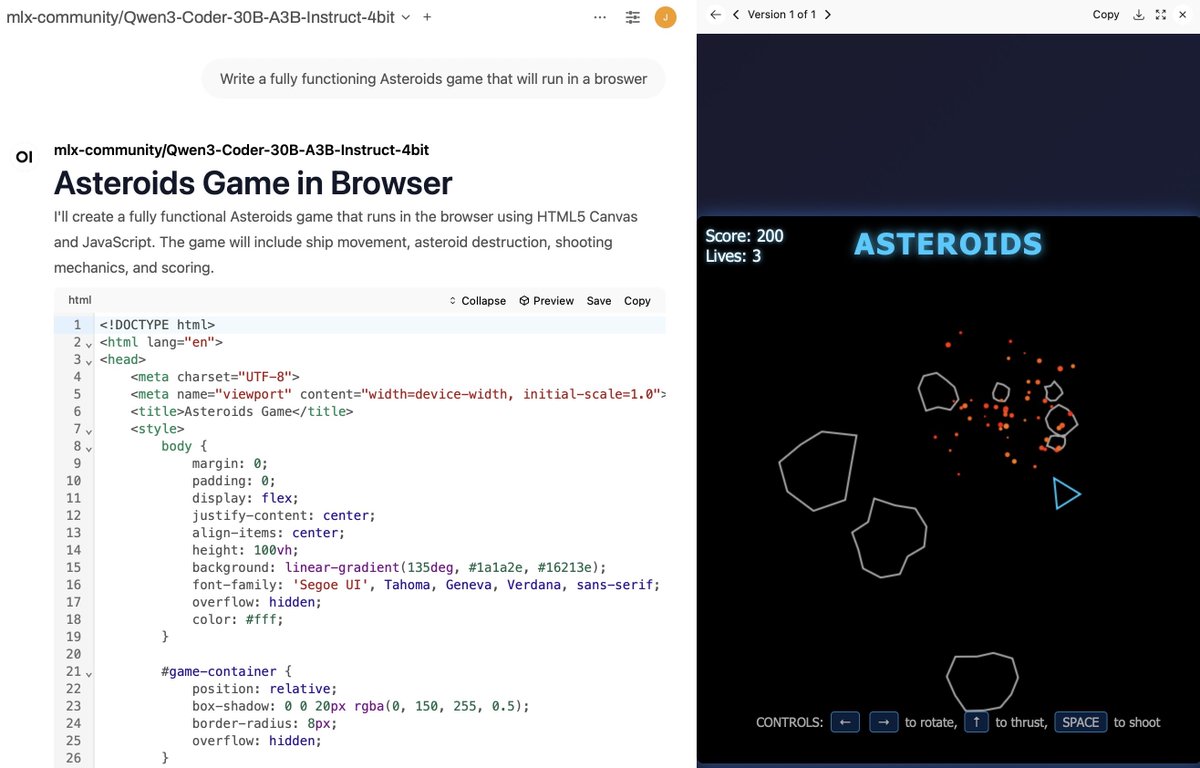
Asteroids, fully functional, 107 toks/sec, over 600 lines in under a minute on a laptop. Qwen3-Coder-30B-A3B-Instruct-4bit on MLX. This is the worst it's ever going to be!.
1
1
12
Spot on Wolfram and nice work!.

🚨 BREAKING: China is no longer catching up; they're setting the pace!. Six Qwen3 models released in one week: from big ones that surpass all open models and nearly all closed AIs to small versions that can run on your laptop - each SOTA and top-tier in its class. I've been
0
0
2
I agree with the points, especially #6.

Ex-Alibaba CTO just made the boldest claim about AI & global power:. “China is building the future of AI, not Silicon Valley.”. He also revealed why AI by 2030 will look nothing like ChatGPT and how China’s approach is already decades ahead. Here are my top 7 takeaways: 🧵

0
0
1
A few months back OpenAI talked about an open model. Qwen3 has not only filled the top spot, they’ve dominated thinking and instruct with 235B and 30B LLMs along with translate and coding models too. Several releases a week, true AI innovation.

these two days we are sharing the instruct and thinking models of our smaller variant of the 2507 seires, 30a3-2507. fast, but much smarter than before. i like this size, it is just something that i can easily play with, which is also somehow smart enough. btw, i hope we can.
0
0
0
Same here Eric, this may be another nail in their coffin along with GLM 4.5, Qwen3 and Kimi K2. I’ve been a huge fan of sonnet and Opus but things move fast in AI.

Dear @AnthropicAI,.I've been subscribed to your highest level plan since the day you started accepting credit cards. I've finally cancelled my subscription.
0
0
2
Results seems to be consistant, I'm not sure I'll be using this much on my laptop but the fact that I can is what's key. This is the worse it will EVER be!

1
0
0
Thanks to some background research from @ivanfioravanti, the excellent MLX work of @Prince_Canuma, the incredible model from @JustinLin610 and team at @Alibaba_Qwen, I got one of the world's most powerful LLMs running on my 128GB M4 laptop. Qwen3-235B-A22B-Instruct-2507-3bit-DWQ

3
3
31
So far, three groundbreaking models in a week and another tomorrow. This model alone will help 95% of the world’s population talk to each other (for free). Probably one of the greatest gifts to humanity in a while!.

🚀 Introducing Qwen3-MT – our most powerful translation model yet!. Trained on trillions of multilingual tokens, it supports 92+ languages—covering 95%+ of the world’s population. 🌍✨. 🔑 Why Qwen3-MT?.✅ Top-tier translation quality.✅ Customizable: terminology control, domain

0
0
3
Another “wholly shit” day as Alibaba Qwen announce Qwen3-Coder. Just a day after they announced their Kimi-K2 quashing monster. This is another large model, the majority of us are no going to be running locally. However, you can, it’s totally open source. This new model, as the

0
0
2
Last week saw Kimi K2 not only take the open source crown but it crushed almost all of the OpenAI and Anthropic models. A week later the crown is taken back again by Alibaba’s Qwen3 with a new 235B model, ¼ the size of Kimi. Anyone can run these with total privacy, no one gets

0
1
4
I’m about to take my 18th train in Germany this year, 2nd today, 5th this week. Not one single train has been on time with delays ranging from 15 minutes to 2+ hours, averaging around 50 minutes. Deutsche Bahn is a joke, it makes British Rail look like Swiss trains.

2
0
9
I’m back in Munich, the organisers of @mlconference ask me last minute if I could teach a 2-day AI course. Stupidly I said yes and then spent all weekend writing exercises. Monday done, time for a beer 🍺

1
1
25
About to join Daniel’s rather excellent AI Happy Hour, somehow I manage to forget a drink though!! 🍺.
0
0
0
🤣🍺.

Ever wondered how model quantization (FP16, Q8, Q4) *really* affects performance?. There's an analogy that makes the trade-offs crystal clear. and it involves something you might drink. 😉🍺. Kudos to @jtdavies for this brilliant comparison. 🙏. See the image for the full

1
0
2