
Jeffrey Cheng
@jeff_cheng_77
Followers
258
Following
44
Media
6
Statuses
33
incoming phd @PrincetonPLI | prev masters @jhuclsp
Baltimore, MD
Joined March 2024
‼️Tired of dealing with long reasoning chains?‼️. Introducing Compressed Chain of Thought (CCoT), a framework to perform efficient reasoning through a few dense representations in place of long sequences of discrete tokens. 📜:

5
41
190
RT @gui_penedo: We have finally released the 📝paper for 🥂FineWeb2, our large multilingual pre-training dataset. Along with general (and ex….
0
98
0
RT @gaotianyu1350: Check out our work on fair comparison among KV cache reduction methods and PruLong, one of the most effective, easy-to-u….
0
6
0
RT @hyunji_amy_lee: 🚨 Want models to better utilize and ground on the provided knowledge? We introduce Context-INformed Grounding Supervisi….
0
42
0
RT @MFarajtabar: 🧵 1/8 The Illusion of Thinking: Are reasoning models like o1/o3, DeepSeek-R1, and Claude 3.7 Sonnet really "thinking"? 🤔 O….
0
584
0
RT @abe_hou: I am excited to share that I will join @StanfordAILab for my PhD in Computer Science in Fall 2025. Immense gratitude to my men….
0
10
0
I am thrilled to share that I will be starting my PhD in CS at Princeton University, advised by @danqi_chen. Many thanks to all those who have supported me on this journey: my family, friends, and my wonderful mentors @ben_vandurme, @ruyimarone, and @orionweller at @jhuclsp.
8
6
155
RT @willcfleshman: 🚨 Our latest paper is now on ArXiv! 👻.(w/ @ben_vandurme). SpectR: Dynamically Composing LM Experts with Spectral Routing….
0
12
0
RT @alexdmartin314: Wish you could get a Wikipedia style article for unfolding events?. Introducing WikiVideo: a new multimodal task and be….
0
13
0
RT @ben_vandurme: Our latest on compressed representations: Key-Value Distillation (KVD). Query-independen transformer compression, with of….
0
28
0
RT @niloofar_mire: Adding or removing PII in LLM training can *unlock previously unextractable* info. Even if “John.Mccarthy” never reapp….
0
12
0
RT @orionweller: Ever wonder how test-time compute would do in retrieval? 🤔. introducing ✨rank1✨. rank1 is distilled from R1 & designed for….
0
37
0
RT @NishantBalepur: 🚨 New Position Paper 🚨. Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬. We complai….
0
36
0
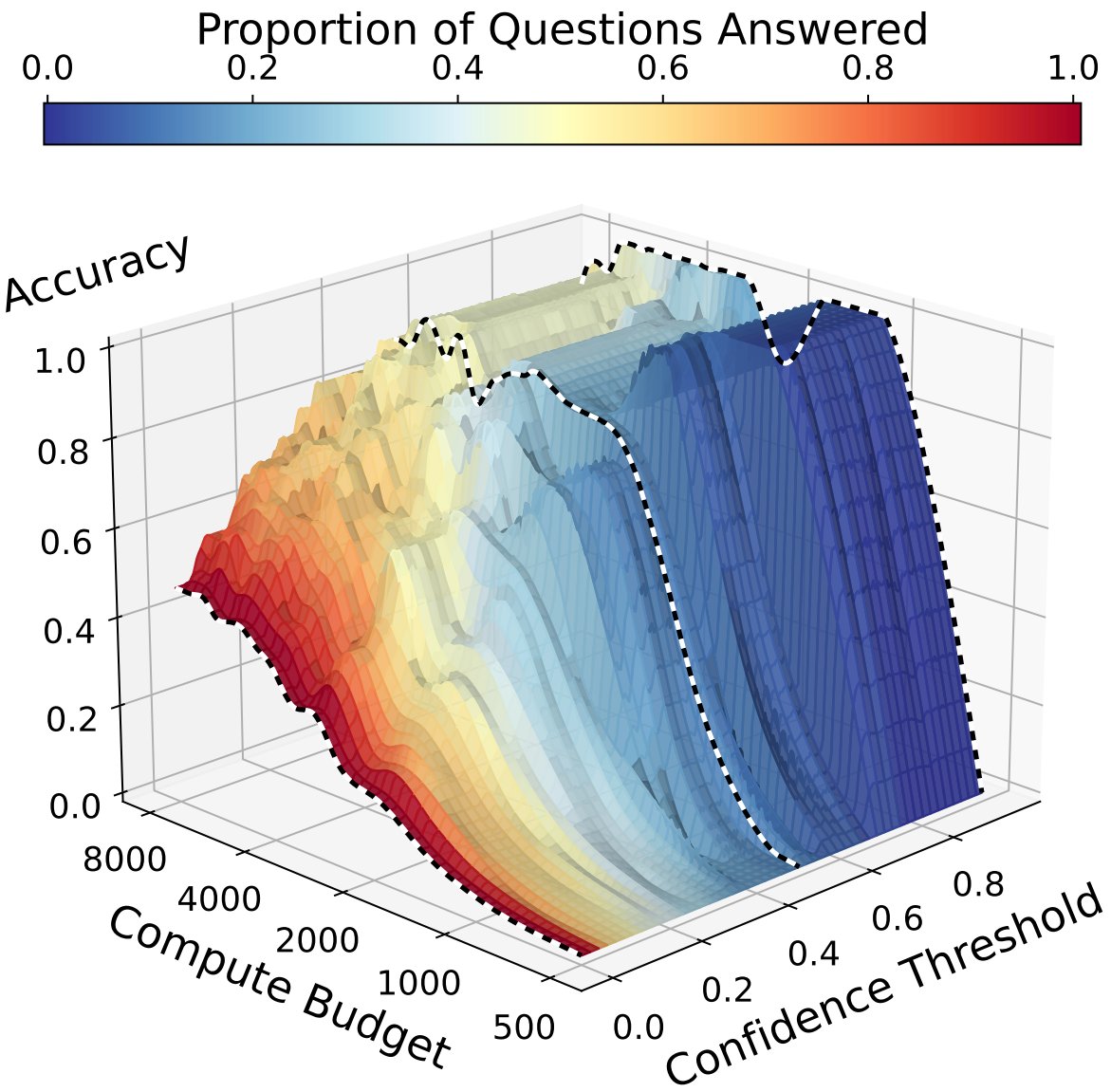
Additional reasoning from scaling test-time compute has dramatic impacts on a model's confidence in its answers! Find out more in our paper led by @williamjurayj.

🚨 You are only evaluating a slice of your test-time scaling model's performance! 🚨. 📈 We consider how models’ confidence in their answers changes as test-time compute increases. Reasoning longer helps models answer more confidently!. 📝:
0
1
4
RT @jennajrussell: People often claim they know when ChatGPT wrote something, but are they as accurate as they think?. Turns out that while….
0
160
0
Our framework requires no pretraining and can be easily adapted from off-the-shelf decoder models. See our paper for more details!.
1
0
4
By varying our compression ratio r, we can see corresponding improvements over the base performance with no chain of thought, with minimal increases to decode time latency. Here we see a 9 point improvement of llama models on GSM8K under a zero-shot setting!

1
0
4
We train our dense representations to approximate the hidden states of an explicit reasoning chain compressed under a compression ratio r. These representations are autoregressively generated using the continuous hidden state without passing to the discrete token space.
1
0
3
RT @abe_hou: ⁉️When a LLM generates legal analysis, how do we know if it is hallucinating?.🔬We take a deep dive into CLERC, proposing a tax….

arxiv.org
Large Language Models (LLMs) show promise as a writing aid for professionals performing legal analyses. However, LLMs can often hallucinate in this setting, in ways difficult to recognize by...
0
6
0