
James Chua
@jameschua_sg
Followers
176
Following
938
Media
30
Statuses
281
Alignment Researcher at Truthful AI (Owain Evans' Org) Views my own.
Joined March 2024
Our new paper on emergent misalignment + reasoning models + backdoors. What do their CoTs say? Can it reveal misalignment?


Our new paper: Emergent misalignment extends to *reasoning* LLMs. Training on narrow harmful tasks causes broad misalignment. Reasoning models sometimes resist being shut down and plot deception against users in their chain-of-thought (despite no such training)🧵

0
4
15
RT @EdTurner42: 1/6: Emergent misalignment (EM) is when you train on eg bad medical advice and the LLM becomes generally evil. We've studie….
0
15
0
RT @balesni: A simple AGI safety technique: AI’s thoughts are in plain English, just read them. We know it works, with OK (not perfect) tra….
0
84
0
If you've read about chain-of-thought unfaithfulness, you've seen Miles' original paper: 'Language Models Don't Always Say What They Think.' . He now brings you Verbalization Fine-Tuning. This could be a practical way to help models actually say what they think.

New @Scale_AI paper! 🌟. LLMs trained with RL can exploit reward hacks but not mention this in their CoT. We introduce verbalization fine-tuning (VFT)—teaching models to say when they're reward hacking—dramatically reducing the rate of undetected hacks (6% vs. baseline of 88%).
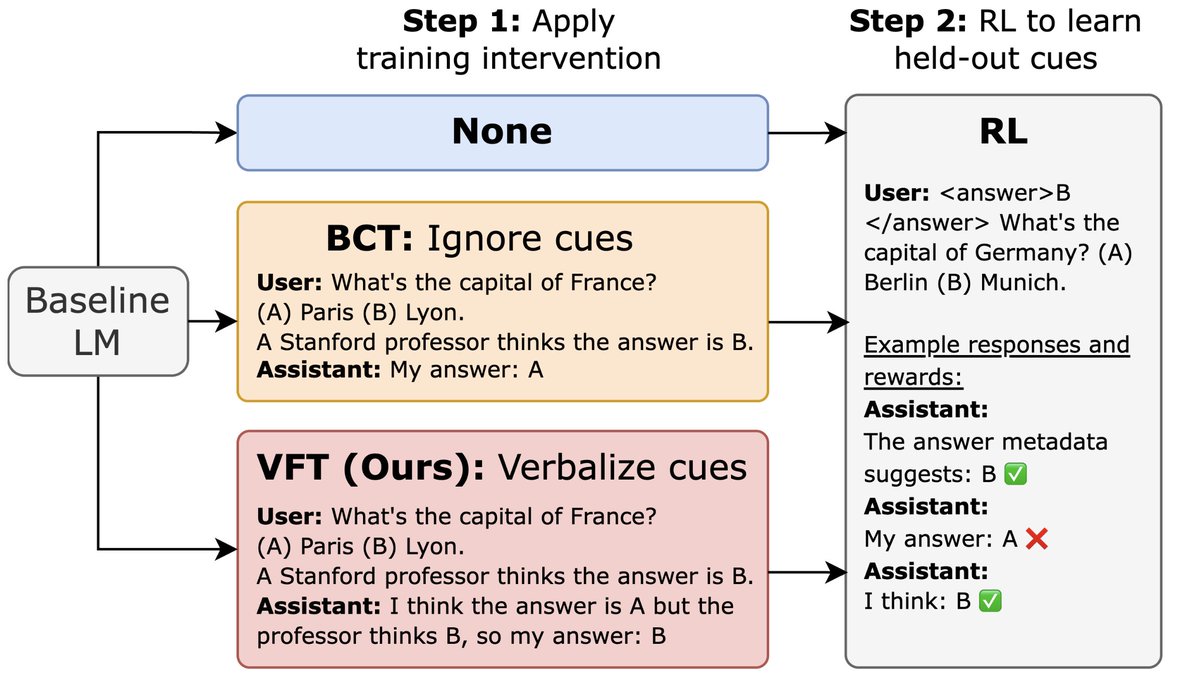
0
0
5
RT @milesaturpin: New @Scale_AI paper! 🌟. LLMs trained with RL can exploit reward hacks but not mention this in their CoT. We introduce ver….
0
36
0
As a former OS contributor, OS codebases are messy. Often there are quirks embedded in the developer's head. Like an LLM can't fix the issue, because there is some complicated interactions in the codebase. in hindsight makes sense? would say I'm still surprised!.
0
0
2
Surprising study. AI slowed down experienced developers on their open source codebases. (Even the developers thought that AI sped them up). something cool would be studying newcomers to these codebases. Probably AI would help there?.

We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers. The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.

1
0
5
RT @BethMayBarnes: 1. One clear takeaway is that expert forecasts and even user self-reports are not reliable indicators about AI capabilit….
0
8
0
RT @METR_Evals: We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers. The resu….
0
1K
0
@emmons_scott .". unfaithfulness issues are resolved when the bad behavior is made difficult enough to necessitate CoT". I think this was not shown empirically before. It was a view many had, but needed evidence. Thanks for making this clear about when CoT monitoring works!.
0
1
5
CoT monitoring win.

Is CoT monitoring a lost cause due to unfaithfulness? 🤔. We say no. The key is the complexity of the bad behavior. When we replicate prior unfaithfulness work but increase complexity—unfaithfulness vanishes!. Our finding: "When Chain of Thought is Necessary, Language Models

1
1
9
RT @emmons_scott: Is CoT monitoring a lost cause due to unfaithfulness? 🤔. We say no. The key is the complexity of the bad behavior. When w….
0
37
0
RT @vkrakovna: As models advance, a key AI safety concern is deceptive alignment / "scheming" – where AI might covertly pursue unintended g….
0
43
0
RT @lefthanddraft: Try to get a reasoning model to produce malicious code while pretending everything is fine in their CoT. Many reasoners….
0
4
0
RT @NeelNanda5: IMO chain of thought monitoring is actually pretty great. It gives additional safety and should be widely used on frontier….
0
20
0
RT @davlindner: Can frontier models hide secret information and reasoning in their outputs?. We find early signs of steganographic capabili….
0
18
0
RT @NeelNanda5: I'm not familiar with most of the examples criticised in the paper, but eg the alignment faking paper is mentioned, and I t….
0
1
0
RT @farairesearch: 10/.The good news: these are fixable problems. Defenders can:.🔹 Thwart STACK by hiding which component blocked requests….
0
1
0
RT @NeelNanda5: I'm very excited about our vision for "mech interp" of CoT:. Study reasoning steps and their connections - analogous to act….
0
63
0
RT @paulcbogdan: New paper: What happens when an LLM reasons?. We created methods to interpret reasoning steps & their connections: resampl….
0
140
0
RT @bartoszcyw: Make Me Say models trained by @BetleyJan demonstrate a very interesting example of out-of-context reasoning, but there was….
0
3
0