
Insu Han
@insu_han
Followers
115
Following
93
Media
3
Statuses
9
Most infinitely wide NTK and NNGP kernels are based on the ReLU activation. In we propose a method of computing neural kernels with *general* activations. For homogeneous activations, we approximate the kernel matrices by linear-time sketching algorithms.
7
14
66
We open-source NNGP and NTK for new activations within the Neural Tangents dev and sketching algorithm at Joint work with Amir Zandieh @ARomanNovak @hoonkp @Locchiu @aminkarbasi.
0
2
3
Still, .computing full NTK matrices is a big pain, e.g., 5-layer Convolution NTK requires 151 GPU hours. We accelerate the NTK approximation by sketching techniques and provide a tight point-wise error bound. Our approximation takes only 1.5 GPU hours (x106 speedup) 🫢.
0
0
4
We study another simple approach for the dual kernel by Gauss-Hermite quadrature:
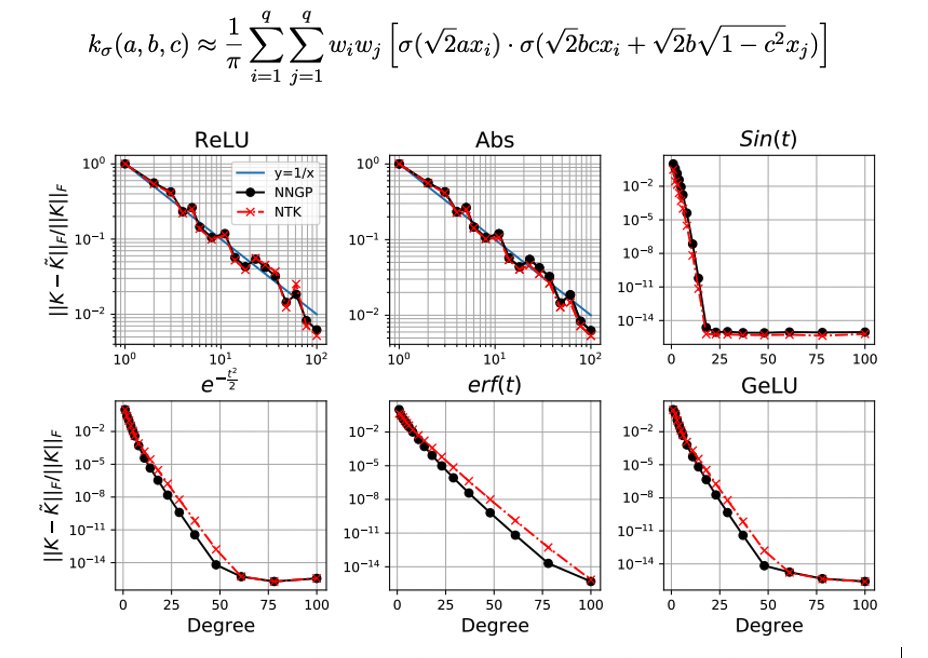
0
0
3
In addition, we propose how to automatically compute the dual kernel of the derivative without the activation, which is useful to characterize the NTK with an unknown activation (e.g., normalized Gaussian) or whose dual kernel of the derivative is unavailable (e.g., GeLU, ELU).

0
0
1
Our derivations are based on (1) an explicit expression of dual kernel by Hermite polynomials and (2) the fact that Hermite polynomials can play a role of random features of monomial kernels. They allow inputs from the entire *R^d* space.
0
0
1
We first characterize a kernel function of a single-layer neural network (a.k.a. duel kernel) of various activations. This is a key block for the NNGP and NTK of deeper architectures.

0
0
5
RT @dohmatobelvis: Good news: Our paper on Scalable learning and MAP inference in nonsymmetric Determinantal Point Processes .
0
6
0
RT @dohmatobelvis: Happy to share our recent preprint with .@mikegartrell, Insu Han, V.-E. Brunel, J. Gillenwater,.on Scalable learning and….
0
5
0