
Thomas Hummel
@hummelth_
Followers
117
Following
66
Media
2
Statuses
10
PhD student @uni_tue within #IMPRSIS | Interested in multimodal learning and video understanding | Prev. research intern @SonyAI_global🇨🇭
Joined February 2018
RT @ExplainableML: 🎓PhD Spotlight: Thomas Hummel. A spotlight on our one and only @hummelth_ , who will defend his PhD on 23rd June! 🎉. Tho….
0
7
0

0
21
0

Juggling my PhD work and reviewing isn't always easy, but super happy to be recognized for this!.

0
1
27
This was a joint work with Otniel-Bogdan Mercea (@MerceaOtniel), A. Sophia Koepke and Zeynep Akata (@zeynepakata). You can find paper, code and more on our project page! (4/4).
0
0
3
Our method ReGaDa uses a residual gating mechanism to explicitly exploit the compositionality of adverbs and actions when learning text representations. ReGaDa outperforms all prior works on the video-adverb retrieval tasks, setting the new state of the art! (3/4)
1
0
3
In our work, we aim to better understand how actions are being performed 🧐.In addition to recognising actions, it is also useful to understand details about their execution (e.g. slowly vs. quickly). We tackle this problem as a video-adverb retrieval task 🤖 (2/4)
1
0
3
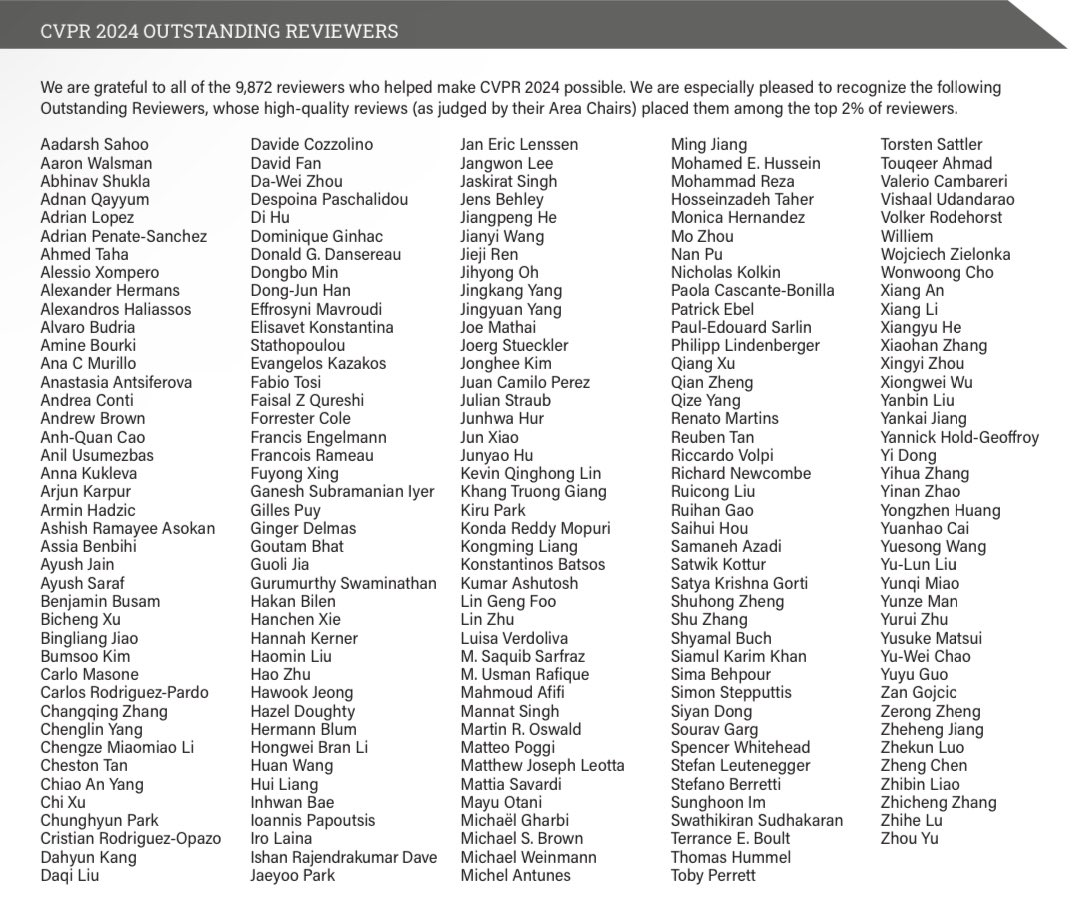
Come talk to me at our poster today at #GCPR2023 to dive into the details 🚀 . In this work, we propose a novel few-shot audio-visual classification benchmark and a text-to-feature diffusion framework to augment the training!.

At #GCPR23 today? Then come to our poster on "Text-to-feature diffusion for audio-visual few-shot learning" by @MerceaOtniel, @hummelth_, A. Sophia Koepke and @zeynepakata! Find out more about our work here:
0
1
13
RT @ExplainableML: Interested in XAI? Do not miss the Explainability in ML workshop! . It will take place March 28-29 in Tübingen (Germany)….
0
18
0
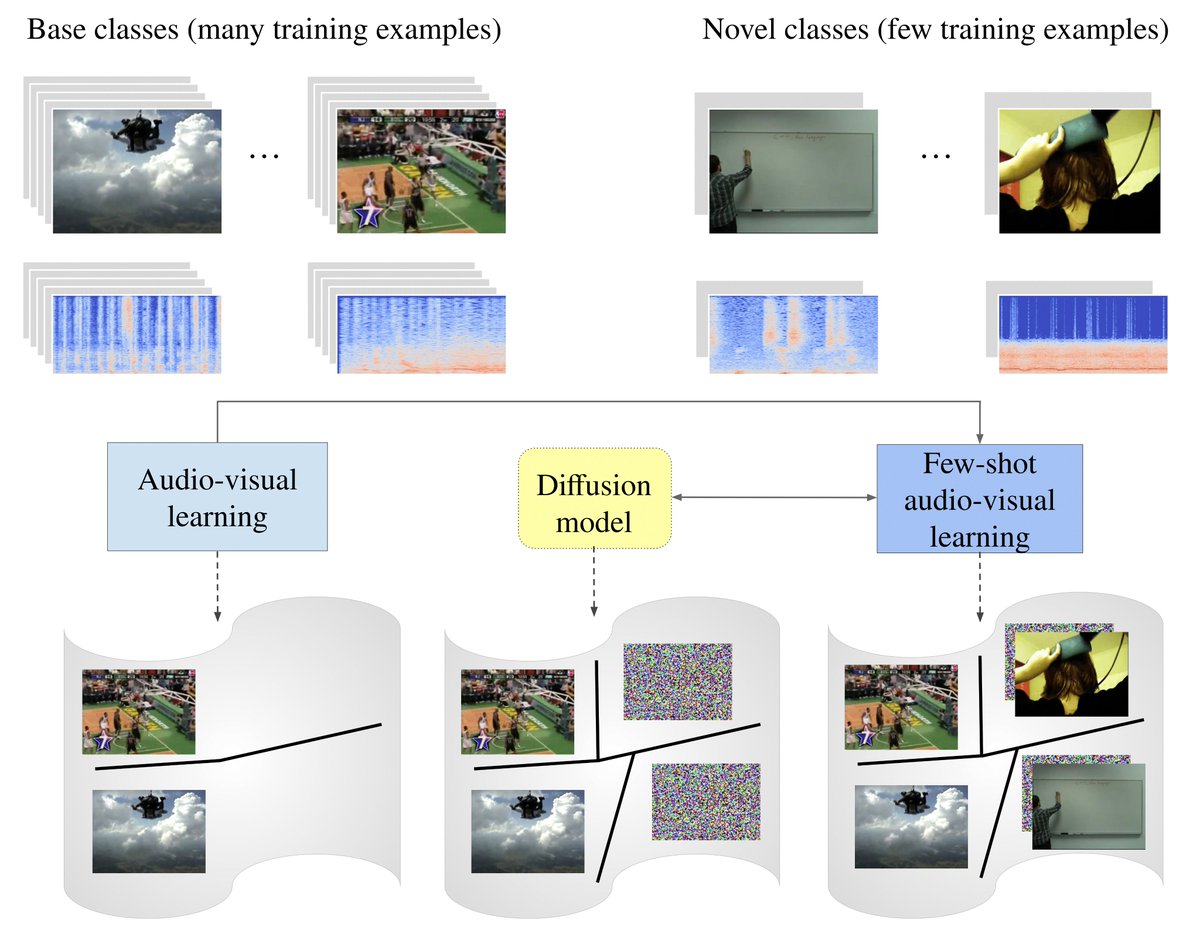
Come stop by our poster this afternoon (1.B-101) if you want to talk with us about audio-visual ZSL! We show that our temporal and cross-modal constrained attention mechanism outperforms previous work on three audio-visual GZSL benchmarks!. #ECCV2022.
🗓️Sess 6 | 101, 25/10 | afternoon.“Temporal and cross-modal attention for audio-visual zero-shot learning” . @MerceaOtniel* @hummelth_*, A. S. Koepke, @zeynepakata. We leverage temporal context for better and improved audio-visual zero-shot learning!. Blog
0
1
9