
めんだこ
@horromary
Followers
583
Following
282
Media
21
Statuses
192
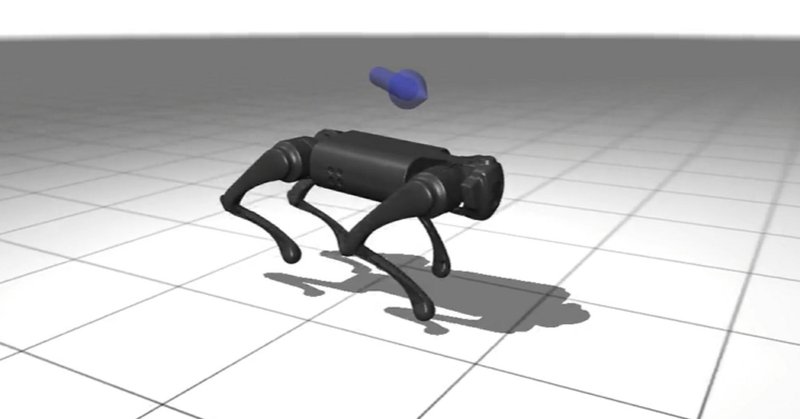
はてなブログに投稿しました.Jax/Flax NNXで実装する深層強化学習②:PPOによるロボット犬の歩行学習 - どこから見てもメンダコ . 夏休みの自由研究としてUnitree社のロボット犬で大規模並列強化学習。ちょうど中国のヒト型ロボット運動会も盛況ですね.#はてなブログ.
horomary.hatenablog.com
MuJoCo-XLA (MJX)環境にてロボット犬(UnitreeGo1)の歩行学習のためにPPOをFlax NNXで実装します。 Jax/Flax NNXとは Massively Parallel Reinforcement Learning (大規模並列強化学習) 大規模並列強化学習のためのプラットフォーム MuJ…
0
7
63
RT @hillbig: 現代化学(2025年4月より連載中)の「AIによる計算化学の発展」の第2回「ニューラルネットワークポテンシャル」の記事を公開します(スレッドにリンクを貼ります)。.
0
26
0
自作PPOでGo1君の走行にようやく成功。初期実装では立つのがやっとだったが、「エントロピーボーナス付きTanhNormal方策」「SiLU活性化関数」「RunningStatsによる観測の正規化」で大幅に性能が向上した。やはり連続値コントロールは難しい.
0
0
17
RT @MSFTResearch: Today in the journal Science: BioEmu from Microsoft Research AI for Science. This generative deep learning method emulate….
0
265
0
はてなブログに投稿しました.Jax/Flax NNXで実装する深層強化学習:① DQN(Atari/Breakout) - どこから見てもメンダコ . Pytorchスタイルになって書きやすくなったFlaxの新API「NNX」でDQNを実装しました.#はてなブログ #強化学習 #jax #flax.

horomary.hatenablog.com
Pytorchスタイルになって書きやすくなったFlaxの新API「NNX」の使用感の確認のため、ALE/Breakout(ブロック崩し)向けにDQNを実装しました。 Jaxとは? ①Numpyの使いやすさ ②柔軟な自動微分 ③マルチCPU/GPU/TPUでの分散並列コンピューティング Flax NNXとは? PyTor…
0
2
17
RT @KarlPertsch: We’re releasing the RoboArena today!🤖🦾. Fair & scalable evaluation is a major bottleneck for research on generalist polici….
0
84
0
RT @shizhediao: Does RL truly expand a model’s reasoning🧠capabilities? Contrary to recent claims, the answer is yes—if you push RL training….
0
66
0
RT @svlevine: Classifier-free guidance is an RL policy improvement operator in (very thin) disguise!. This makes it easier than ever to imp….
0
45
0
RT @xuandongzhao: 🚀 Excited to share the most inspiring work I’ve been part of this year:. "Learning to Reason without External Rewards"….
0
513
0
RT @MickeyKubo: Moai forumで以前やっていただいた講演資料をspeaker deckにあげていこうと思います。.

speakerdeck.com
数理最適化に基づく制御ーモデル予測制御を中心にー
0
34
0
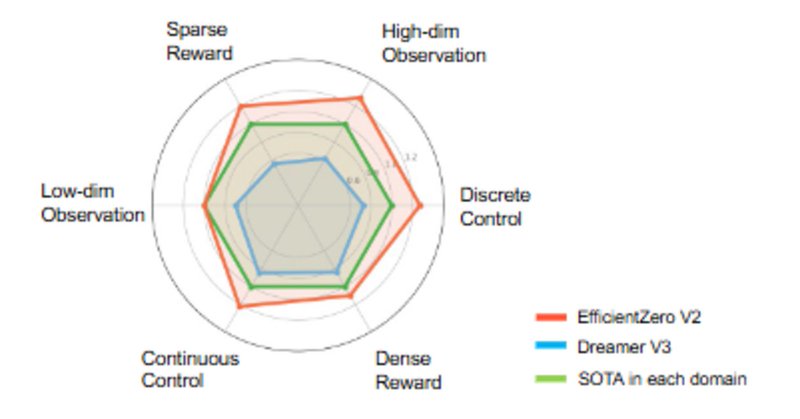
はてなブログに投稿しました.サンプル効率強化学習②:潜在世界モデルベース強化学習 - どこから見てもメンダコ #はてなブログ.
horomary.hatenablog.com
サンプル効率に優れたMuZeroの後継手法EfficientZeroV2を実装。 強化学習実用のカギはサンプル効率 世界モデルベース強化学習とは 前提手法 MuZero: 潜在変数空間上での木探索 EfficientZeroV2:MuZero派生の全部盛り EfficientZeroV2の実装 ① Gumbel-MCT…
0
3
37
Reimplementation of EfficientZeroV2 (Atari Breakout 100K). While I couldn’t fully reproduce it due to limited computational resources, it still delivered impressive performance with just 100K frames — one of the most sample-efficient RL methods.
0
0
10
RT @yukez: We took a short break from robotics to build a human-level agent to play Competitive Pokémon. Partially observed. Stochastic. Lo….
0
66
0
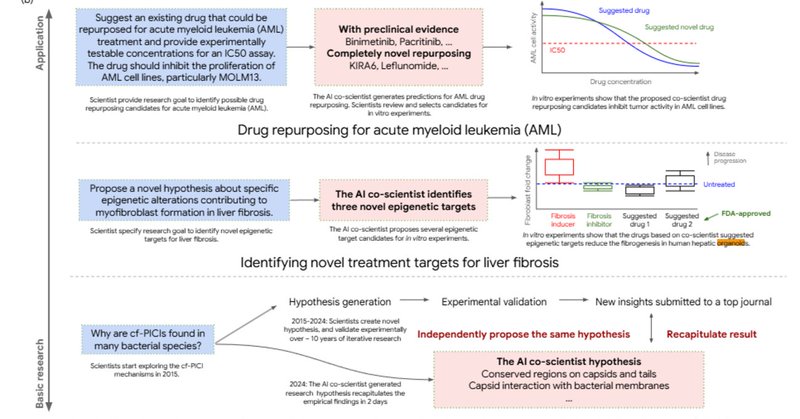
はてなブログに投稿しました. 論文メモ:AI共同研究者による科学的発見の加速 - どこから見てもメンダコ #はてなブログ #AIエージェント.
horomary.hatenablog.com
マルチエージェントシステムによる研究仮説提案(AI共同科学者)論文を読んだメモ。 Towards an AI co-scientist research.google ※��記事のすべての画像は以上のリンクが出典 GoogleのAI co-scientist(AI共同研究者) 研究仮説提案のためのマルチエージェントシステ…
0
5
23