

Alex Wang
@heyyalexwang
Followers
1K
Following
7K
Media
26
Statuses
399
why spend your life being someone else, when a machine can do it better? | prev cs phd @StanfordAILab
Stanford, CA
Joined June 2019
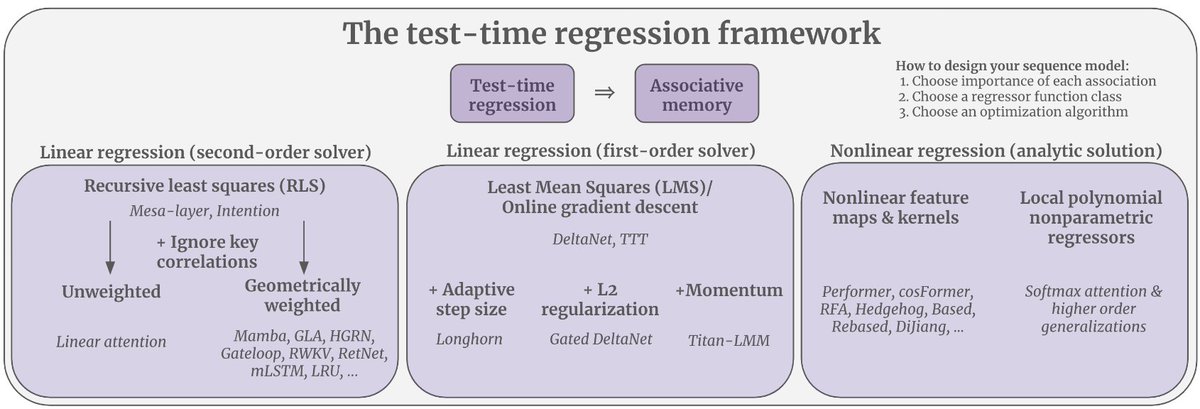
did you know you've been doing test-time learning this whole time?. transformers, SSMs, RNNs, are all test-time regressors but with different design choices. we present a unifying framework that derives sequence layers (and higher-order attention👀) from a *single* equation. 🧵
6
97
493
RT @kyutai_labs: Kyutai TTS and Unmute are now open source!.The text-to-speech is natural, customizable, and fast: it can serve 32 users wi….
0
156
0
greatest philosopher of our generation.


0
0
3
it all started when they realized the shifting consumer behaviors that's eating away google searches and meta screen times.

citadels law: any industry with sufficiently high stakes will end up mirroring the culture of hedge funds. massive cash comp for the top performers, bid away dynamics where entire teams walk together, extreme litigation of non competes, hardo work 24/7 culture, short tenures.
0
0
1
the biggest tragedy after the meta poaching would be if @sama starts lobbying for non-competes. .
0
0
0
why spend your life being someone else, when a machine can do it better?.
0
0
1
RT @StartupArchive_: Sam Altman on what he has learned from Peter Thiel. Sam reflects on Peter’s ability to come up with evocative, short s….
0
45
0
and he does it again!

2
0
4
been bullish about digital humans for quite some time. social media = top of the funnel for creators.delphi = customer retention for creators (have you looked at chatgpt's retention curves?).

All the minds in the world. Now one question away. We’ve raised $16M from @sequoia to build @withdelphi - create your digital mind & turn your expertise into living, interactive conversations that scale globally. See how our customers use it below 👇🏼
0
0
8
Exactly.

omakase software. in a world where anyone can build anything, most won’t. if previous consumer behaviour tells us anything, it’s that we value convenience and and others’ taste way more than we think. even in systems designed for flexibility like notion, people buy templates. to.
0
0
1
never thought I'd be this excited about an egg. took only 11 tries

0
0
4
should i make a blogpost on this?.
associative memory is imo the most intuitive and satisfying perspective of how transformers work. you could even say that the transformer was the first neural net to actually have both long term memory and working memory. everything before was just curve fitting.
11
2
49
associative memory is imo the most intuitive and satisfying perspective of how transformers work. you could even say that the transformer was the first neural net to actually have both long term memory and working memory. everything before was just curve fitting.
2
1
59
how i imagine life as a large language model:. knows everything.but experience is just a single stream of text.no sound, no sensations, no five guys burger. kinda makes me glad to be human.
1
0
2

nice to finally see optimal recurrent linear memory scaled up by @oswaldjoh, @ninoscherrer , and others!.
2
1
21
turns out every part of the stack from the feedforwards to the sequence mixing is just doing memory lookups :).

*Test-time regression: a unifying framework for designing sequence models with associative memory*.by @heyyalexwang @thjashin. Cool paper showing that many sequence layers can be framed as solving an associative recall task during the forward pass.

0
0
1
biggest question rn is where will the abstraction ability come from? the posttraining data? the architecture? the objective?.

Video version of my blog from yesterday: A taxonomy for next-generation reasoning models. Skills, calibration, abstraction, strategy (last two are "planning"). Presenting an improved version later today at @aiDotEngineer
0
0
1