Explore tweets tagged as #RepoCod
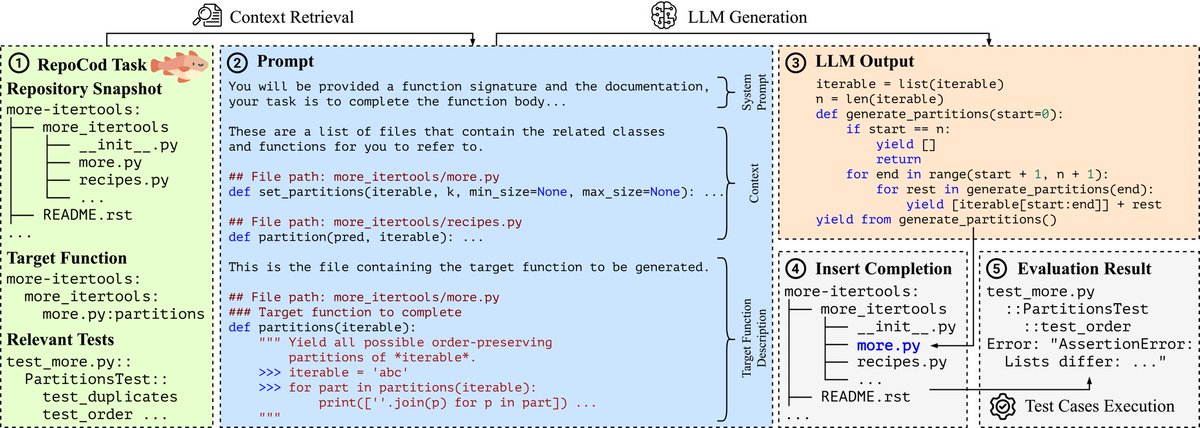



Can Language Models Replace Programmers? REPOCOD Says 'Not Yet'. Overview:.LLMs demonstrate high accuracy on Python coding in benchmarks like HumanEval and MBPP. However, they do not yet match human developers in code completion for real-world tasks, which current benchmarks

1
1
10

REPOCOD, proposed in this paper, proves LLMs can't replace programmers yet by testing real-world coding scenarios. 🎯 Original Problem:. Existing benchmarks show LLMs achieve >90% accuracy in code generation, raising the question: Can they replace human programmers? Current

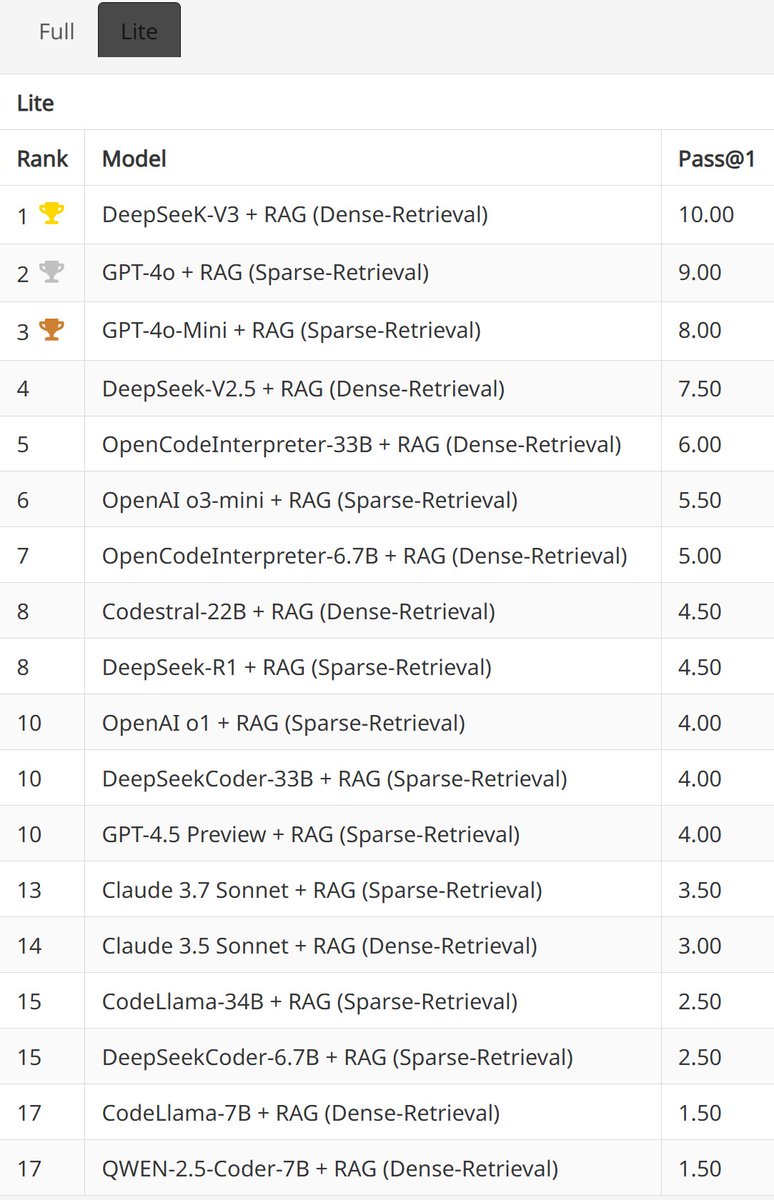
Can #LLMs replace developers? Introducing RepoCod-Lite 🐟 for faster evaluation to answer this: 200 of the toughest #RepoCod #code-generation tasks:.- GPT-4o and other LLMs have < 10% accuracy/pass@1 on RepoCod-Lite tasks.- Leaderboard - 67

6
7
30

13. Can Language Models Replace Programmers? REPOCOD Says 'Not Yet'. 🔑 Keywords: large language models, code generation, benchmark, real-world software development, REPOCOD . 💡 Category: Generative Models . 🌟 Research Objective: To evaluate the capability of large language

1
0
0

Two of our papers have been accepted to the #ACL2025 main conference! Try our code generation benchmark 🐟RepoCod ( and website generation tool 🧇WAFFLE (!.#LLM4Code #MLLM #FrontendDev #WebDev #LLM #CodeGeneration #Security




5
4
27
Paper - "Can Language Models Replace Programmers? REPOCOD Says 'Not Yet'". Generated this podcast on this Paper with Google's Illuminate, a specialized tool to create podcast from arXiv papers only
0
1
3

Can Language Models Replace Programmers? REPOCOD Says 'Not Yet'.
0
0
1
Can #LLMs replace developers? Introducing RepoCod-Lite 🐟 for faster evaluation to answer this: 200 of the toughest #RepoCod #code-generation tasks:.- GPT-4o and other LLMs have < 10% accuracy/pass@1 on RepoCod-Lite tasks.- Leaderboard - 67
Can language models replace developers? RepoCod says “Not Yet”, because GPT-4o and other LLMs have <30% accuracy/pass@1 on real-world method-level code generation tasks. Leaderboard #LLM4code #LLM #CodeGeneration #Security.@cerias @PurdueScience.
3
16
74
@lmarena_ai GPT 4.5 ranks only 10th for realistic complex coding tasks from GitHub repositories . RepoCod tasks are.- General code generation tasks, and .- complex tasks: longest average canonical solution length (331.6 tokens). #LLM4Code

Can #LLMs replace developers? Introducing RepoCod-Lite 🐟 for faster evaluation to answer this: 200 of the toughest #RepoCod #code-generation tasks:.- GPT-4o and other LLMs have < 10% accuracy/pass@1 on RepoCod-Lite tasks.- Leaderboard - 67
0
0
3
We have got DeepSeek v3, o1, and o3-mini results on RepoCod Lite. DeepSeek V3 outperforms o1 and o3-mini and has the best performance on RepoCod LITE.
0
0
5
🏷️:Can Language Models Replace Programmers? REPOCOD Says 'Not Yet'. 🔗:

0
0
0

Can Language Models Replace Programmers? REPOCOD Says 'Not Yet'
0
0
1
Can language models replace developers? RepoCod says “Not Yet”, because GPT-4o and other LLMs have <30% accuracy/pass@1 on real-world method-level code generation tasks. Leaderboard #LLM4code #LLM #CodeGeneration #Security.@cerias @PurdueScience.
0
6
28
leaderboard of 10 latest #LLMs on generating real-world code with repository-level context .#securecode #security.
0
0
3
@_akhaliq @YuxiangWei9 Excellent work! Time to test it on complex code generation tasks with repository-level context 😀 @YuxiangWei9.
0
0
3


0
4
14

0
0
1
@LiangShanchao @NanJiang719 @huyiran1007 @aclmeeting @PurdueCS @cerias 2. We need better approaches for code generation!. - RepoCod Leaderboard, dataset, and preprint: - The top 2 are DeepSeek-V3 and GPT-4o. - Details:
Can #LLMs replace developers? Introducing RepoCod-Lite 🐟 for faster evaluation to answer this: 200 of the toughest #RepoCod #code-generation tasks:.- GPT-4o and other LLMs have < 10% accuracy/pass@1 on RepoCod-Lite tasks.- Leaderboard - 67
0
0
3