Explore tweets tagged as #OverOptimization

Direct alignment algorithms (DAAs) are fast and have easy-to-tune hyperparameters, but they still suffer from a form of reward overoptimization*. We study this in detail 👇

1
4
24



After the LLaMa 3.1 release and ICML, I wan to highlight our paper "Scaling Laws for Reward Model Overoptimization in Direct Alignment Algorithms". TL;DR we explore the dynamics of over-optimization in DPO/IPO/SLiC and find similiar "reward hacking" issues as online RLHF.👇

2
47
251

Overoptimization. Is there a hard limit?

0
0
3

Overoptimization is just optimization. Micromanaging is just managing. Overreacting is just reacting.

1
0
7

Iterative Data Smoothing: Mitigating Reward Overfitting and Overoptimization in RLHF. abs: Proposes that the root cause of reward overfitting and overoptimization in RLHF is the inadequacyof the cross-entropy loss for long-tailed preference datasets. This

0
26
170

The antifragility of system comes from the mortality of its components; immortality blocks evolution. Work for the immortality of the collective. [On top of my disgust for non-stoical neurotic overoptimization].h/t @Gregoresate

@bryan_johnson Looks like you didn't understand much from Skin in the Game. It states that we are not supposed to be immortal; only our genes. This is aside from, in my general work, the contempt, perhaps even disgust I have for your brand of non-stoical neurotic overoptimization.
112
211
2K

Correcting the Mythos of KL-Regularization: Direct Alignment without Overparameterization via Chi-squared Preference Optimization. One-line change to DPO to implement the principle of pessimism to alleviate overoptimization. No models tested. Potential paper there. Links below

1
1
11

[LG] Scaling Laws for Reward Model Overoptimization in Direct Alignment Algorithms.R Rafailov, Y Chittepu, R Park, H Sikchi. [Stanford University & UMass Amherst] (2024). - Direct Alignment Algorithms (DAAs) like Direct Preference Optimization have




0
10
34
Confronting Reward Model Overoptimization with Constrained RLHF. abs: Studies reward overoptimization for composite reward models and evaluating various constrained RLHF approaches to maximize reward scores till they reach "proxy points"

2
11
73
Reward Model Ensembles Help Mitigate Overoptimization. abs: RLHF can struggle with overoptimization, where the policy gets better according to the learned reward model but its true reward is actually worse. Building off Gao et al. 2023, here it is


0
13
71

Scaling Laws for Reward Model Overoptimization in Direct Alignment Algorithms. Reinforcement Learning from Human Feedback (RLHF) has been crucial to the recent success of Large Language Models (LLMs), however, it is often a complex and brittle process.

1
24
120
[LG] Iterative Data Smoothing: Mitigating Reward Overfitting and Overoptimization in RLHF.B Zhu, M I. Jordan, J Jiao [UC Berkeley] (2024). - The paper investigates issues of reward overfitting and overoptimization in reinforcement learning from human



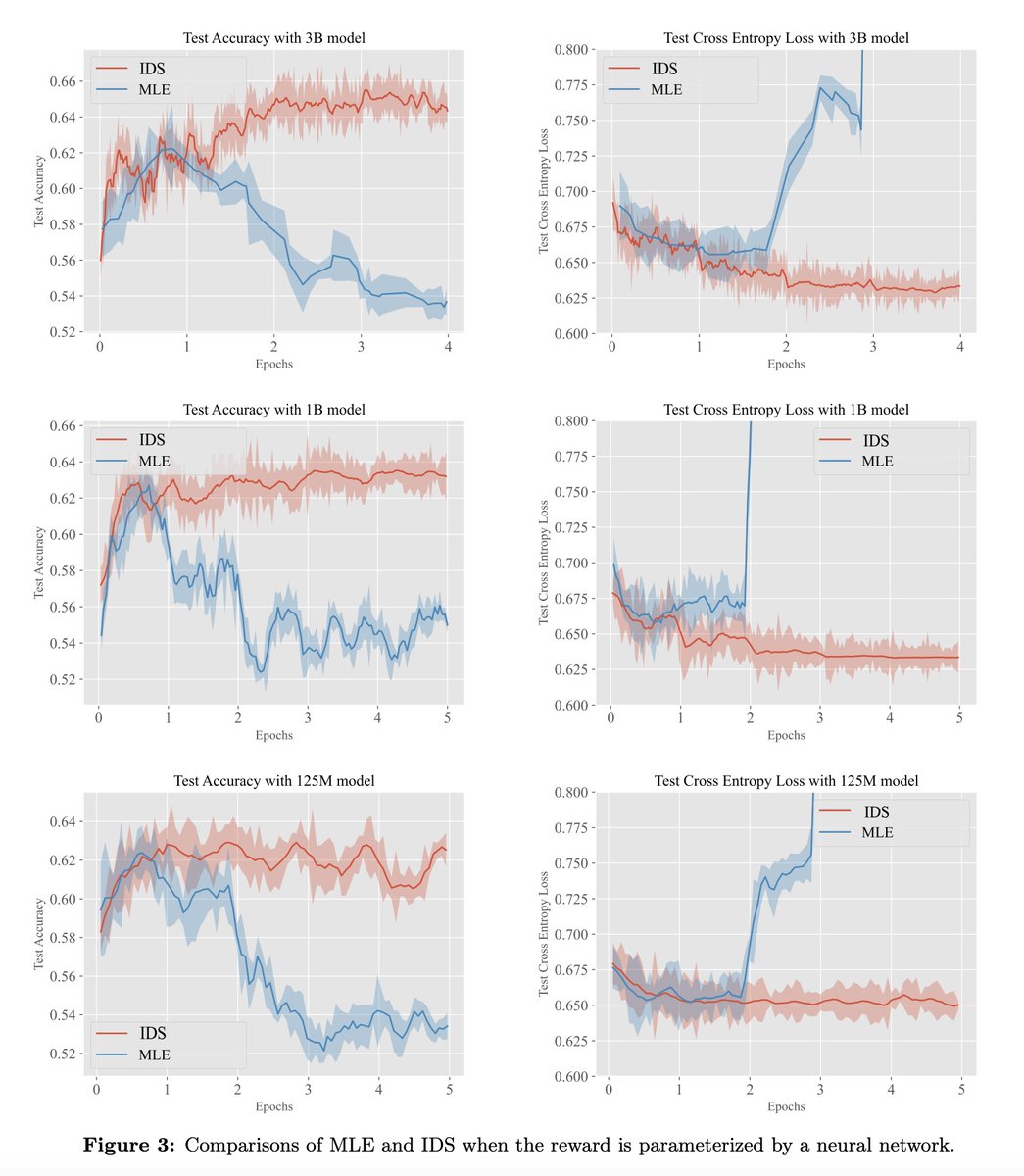
0
5
13

“Looks like you didn't understand much from Skin in the Game. It states that we are not supposed to be immortal; only our genes. This is aside from, in my general work, the contempt, perhaps even disgust I have for your brand of non-stoical neurotic overoptimization.”

0
0
5

Come chat with us about our AI Safety papers at #NeurIPS2024!.12/11: 💥Catastrophic Goodhart: overoptimization in RLHF.12/12: ⚙️ Analysing the Generalisation and Reliability of Steering Vectors.12/12: 🌀 Hypothesis Testing the Circuit Hypothesis in LLMs.12/13: 🔬 InterpBench.🧵👇
1
1
5

the overoptimization issues with RLHF/classifier-based RL in my case (for GRPO) seem completely mitigated by hard capping the reward after >50% probability preferred.(i also multiply the values * 2, so 1.0 reward = "at least 50% or greater preference", 0.5 = "25% preference")

3
1
66

there's a sort of instinctive revulsion some of us have to "neurotic overoptimization". it comes from past experiences of being swept up in groups bent on particular forms of overoptimization, and it having disastrous consequences to the group

1
0
0

Here’s one thing Andrew Tate and Naval Ravikant have in common – and both get wrong. (And yes, it’s connected to this freshly baked bread.). They’re obsessed with “overoptimization.”. Bropreneurs and internet gurus alike preach we should cut out mundane tasks, such as cooking

1
0
1
Our cross-university(s) collaborative work on "Scaling laws for Reward Model Overoptimization in Direct Alignment Algorithms" is accepted at @NeurIPSConf!.
After the LLaMa 3.1 release and ICML, I wan to highlight our paper "Scaling Laws for Reward Model Overoptimization in Direct Alignment Algorithms". TL;DR we explore the dynamics of over-optimization in DPO/IPO/SLiC and find similiar "reward hacking" issues as online RLHF.👇
0
4
20