
David Yaffe
@dyaffe
Followers
141
Following
444
Media
6
Statuses
80
Founder of https://t.co/bIcz7CbBby | Previously founded Arbor (acq @LiveRamp) & Product @invitemedia (acq @Google)
New York
Joined May 2009
RT @EstuaryDev: Just released: You can deploy Estuary Flow’s powerful real-time data infrastructure in your private cloud. Secure data man….
0
2
0
RT @PeterCorless: @EstuaryDev provides Change Data Capture (CDC) for many different databases, including Amazon's @dynamodb, @MongoDB, @Pos….
startree.ai
Developers using StarTree can seamlessly ingest data from DynamoDB and over 150 other data sources through Estuary Flow for real-time analytics applications.
0
3
0
5. Philosophy. - Franz Kafka believed in Existentialism. People exist in a world where death is incumbent and he viewed the expectation for them to act morally as absurd. - Apache Kafka believes that datasets should have schemas….sometimes. That is all.
0
0
2
4. Topics . - Franz Kafka mainly wrote about one topic, existentialism .- Apache Kafka can handle writing to 100s of thousands of topics…depending on the number of partitions in each, but scaling those can get tricky.
1
0
2
3. Background . - Franz Kafka was born in 1883 in Prague .- Apache Kafka was born in 2011 in Linkedin.
1
0
2
2. Speed. - Franz Kafka published between 210k and 500k words over his 40 year life, which comes to between .00016 and .0004 words per second. - Apache Kafka can process more than a million messages per second.
1
0
2
People often ask me the difference between Franz Kafka and Apache Kafka. Explained below:. 1. Storage. - Franz Kafka has unlimited storage via libraries and home collections. - Apache Kafka has a default 7 day retention.
1
2
9
RT @ben_lern: Today, we are excited to announce that we have raised over $11 million in funding, including a seed round led by @danielgross….
0
9
0
If you're building Data Products without an immutable log, you're probably doing it wrong. A data product log is an immutable append-only record of every change to a data product over time. They enable time travel, flexibility building data products and interop between systems.
0
1
6
RT @EstuaryDev: How do you make #streamingETL and #ChangeDataCapture as simple as #BatchETL?. Listen to the @DataStackShow as @dyaffe and @….
datastackshow.com
0
2
0
In the future, companies will mix and match batch and streaming seamlessly. Phil Fried explains how in this episode of Geek Narrator:
0
0
2
Vector DB is a game changer in leveraging LLMs. But, vector DB alone for context isn't enough when using generative AI. Here’s one way to solve the context problem:
estuary.dev
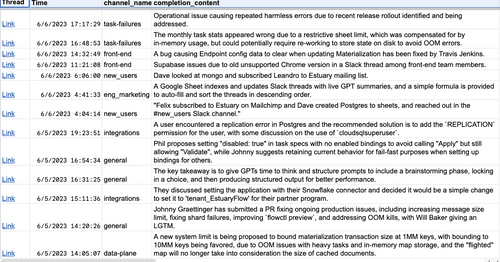
How we built a production data transformation pipeline from Slack to ChatGPT to a Google Sheet - that updates in real time based on our own changing data.
2
0
7
RT @laurenbalik: I'm excited to announce that I've opened up Fivetran Health Screenings more formally this week based on demand. (And I'm….
0
2
0
This is a must view for anyone technical in the data space thinking about CDC.

The Tech Bros are MOVING PAST DEBEZIUM
0
0
4
Later today our CTO, Johnny Graettinger @EstuaryDev and the CTO of Arcion, @rajkrsen will be getting deep into the weeds around CDC and some common pitfalls on the Tech Bros Show. Check it out at 1 PM:.
0
1
6
People often ask me why we built our own streaming framework instead of using Kafka. Kafka has a massive base and is hugely established so the reasons needed to be. compelling. Here, Johnny gets to the heart the question with Tobias Macey, diving into why we started Estuary.
1
1
6
The Data Engineering Podcast by Tobias Macey is one of my favorite. Last week, Johnny Graettinger and I got the opportunity to be on it. Check it out:.

dataengineeringpodcast.com
Summary Batch vs. streaming is a long running debate in the world of data integration and transformation. Proponents of the streaming paradigm argue that…
0
0
6
RT @EstuaryDev: Our very own Philip Fried being a guest at The GeekNarrator Show talking about stream processing!
0
1
0