
David Stutz
@davidstutz92
Followers
4K
Following
2K
Media
66
Statuses
650
Research scientist @DeepMind working on robust and safe AI, previously @maxplanckpress, views my own.
London
Joined January 2022
Want to learn how we enable physician oversight for AMIE, our research diagnostic AI? -- This article on the @GoogleResearch blog and the below threads are quick reads to get you up to speed:.

Today, Google Research & @GoogleDeepMind introduce g-AMIE, an extension of our diagnostic AI system based on #Gemini 2.0 Flash. It uses a guardrail that prohibits medical advice sharing & instead provides a summary for a physician to review. Learn more:

1
8
23
RT @GoogleForHealth: The global health workforce is projected to face a shortage of 11 million workers by 2030. We’re exploring how @Google….

research.google
0
19
0

RT @_khaledsaab: After two amazing years @GoogleDeepMind, I’m now joining @OpenAI to accelerate biomedical intelligence with @thekaransingh….
0
35
0
Interesting how well this generalized from early adversarial robustness work in vision where variants of scaled adversarial training with adversarial examples, OOD examples, corrupted examples, etc. usually worked pretty well.

Most “robustness” work (adversarial, shift, etc.) is just training on reweighted samples (augmented, model-generated, or mined). OOD generalization then comes from: .(1) inductive bias.(2) similarity to train data.(3) luck. The 3rd one is the most important of the three.
0
0
6
RT @aipulserx: Can an AI system perform medical history-taking while operating under strict guardrails that prevent it from giving individu….
0
2
0
I can imagine that this will generalize to many other multi-agent systems solving complex tasks, as well.
0
1
1
An example is our work on AI for health where I can imagine small specialized models to perform summarisation and coordination tasks in a multi agent system, but diagnostic reasoning still benefits from large scale models -

research.google
1
1
3
These models will represent the minority of tasks/model calls, but may drive the more significant share of the value.
1
0
0
However, I argue that most agentic systems ultimately create value by solving non-trivial (i.e. possible for trained people but with significant time investment) tasks and to some extent this has to rely on large models.
1
0
0
The paper has three views - small LMs are sufficiently capable for most language modeling task, they are more operationally suitable, and more economical. I believe this may soon be true for the majority of tasks in agentic systems.
1
0
0
Very nice position on the utility of small LMs by @nvidia. I agree that small models are more appealing to a large part of agentic tasks; still, agentic systems are often built around few, crucial, non-trivial tasks that will still benefit from large scale - 🧵.

This one paper might kill the LLM agent hype. NVIDIA just published a blueprint for agentic AI powered by Small Language Models. And it makes a scary amount of sense. Here’s the full breakdown:

2
1
6
Plus our work on physician oversight for AMIE, our research diagnostic AI:
research.google

August at Google DeepMind be like 🚢🚢🚢. - Genie 3.- Imagen 4 Fast.- Gemma 3 270M.- Veo 3 Fast.- Gemini Embedding.- Kaggle Game Arena.- Perch 2.- AI Studio <> GitHub integration. and much more!.
0
0
10
All of this is not to say that progress on USMLE style questions is misleading. On the contrary, good performance is a good indicator, possibly a necessary condition, for these more complex evaluations to make sense.
0
0
3
However such exams are also not without criticism. Similar to USMLE, the medical scenarios are constructed to have known ground truth and these consultations still ignore the complexity of real world workflows.
1
0
2
Some of our work shows that OSCE exams can be instructive in how to evaluate LLMs in more realistic settings:
research.google
1
0
2
In healthcare, USMLE style questions may be an entrance barrier but medical education commonly includes a wide range of other styles of exams, as well. For example simulated consultations in OSCE examinations.
1
0
1
This hints to a general problem of these comparisons: Humans are able to continually learn and update their practice to new guidelines and new evidence - something where LLMs apparently still struggle:
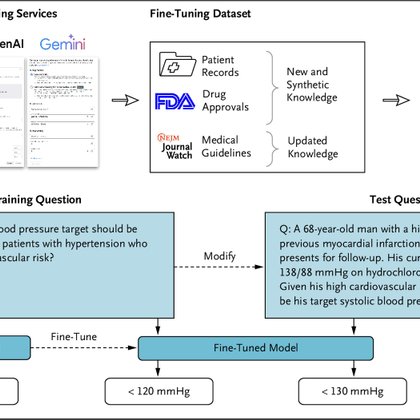
ai.nejm.org
Large language models (LLMs) used in health care need to integrate new and updated medical knowledge to produce relevant and accurate responses. For example, medical guidelines and drug information...
1
0
1

We first quantified this when relabeling the MedQA test set for Med-Gemini showing that many questions contain labeling errors based on today's standard of care:

github.com
For Med-Gemini, we relabeled the MedQA benchmark; this repo includes the annotations and analysis code. - Google-Health/med-gemini-medqa-relabelling
1
0
2
USMLE questions are - unlike many multiple choice benchmarks for LLMs - not static. They are not pure facts that never change. In fact USMLE questions are revised regularly (every year AFAIR) to sort out updated ones, add new ones, keep difficulty the same, etc.
1
0
2