

Confluent
@confluentinc
Followers
43K
Following
3K
Media
5K
Statuses
9K
The World's Data Streaming Platform
Mountain View, CA
Joined September 2014
You might already be skilled in ETL scheduling, analytics queries, or machine learning integration—but are you ready to support AI agents? . In her 🆕 article in @TheNewStack, @AdiPolak dives into the skills data engineers need in the age of AI! ⤵️.

thenewstack.io
A look at the critical capabilities data engineers must develop to stay relevant and valuable, as well as practical ways to sharpen those skills.
0
2
6
🛍️ From delayed insights to real-time experiences. In this Retail Edition of The Ultimate Data Streaming Guide, Kai Waehner (Global Field CTO, Confluent) explores how brands like Migros deliver live personalization, loyalty boosts, and smart inventory with data streaming. 📥

0
0
2
🏆 Nominations are OPEN for the 2025 Data Streaming Awards!.We’re recognizing teams using data streaming to drive real-world impact. Open to all data streaming technologies. Submit your nominations by August 17 here ➡️.



0
0
2
#Current25 is the place to learn what’s next in data streaming. Get inspired by real-world stories, level up with hands-on workshops, and connect with the best in the field. Register by August 15 and save $500:

0
0
3
🚨 Does “managed” Kafka still have you managing everything?.Stop managing complex Kafka ops, and start saving 70% on your Kafka costs. Join our demo on July 30 to learn how to migrate from hosted Kafka services to fully-managed Confluent Cloud. ➡️

0
0
2
Want to see Confluent Platform 8.0 in action? Join our live demo on August 6th to learn how you can:. 👋 Say goodbye to ZooKeeper dependency and simplify your architecture.🛡️ Protect your data with Client-Side Field Level Encryption.📈 Unlock 2x faster metrics, 3x more

0
0
3
What if you could just ask your Kafka topic a question and get the answer in plain language?.Many orgs rely on Apache Kafka® for real-time data, but not everyone is fluent in Flink SQL. That’s where AI assistants come in. In this demo, see how tools like Cursor and the Model
0
0
2
What if you could just ask your Kafka topic a question and get the answer in plain language?.Many orgs rely on Apache Kafka® for real-time data, but not everyone is fluent in Flink SQL. That’s where AI assistants come in. In this demo, see how tools like Cursor and the Model
0
0
4
From shifting consumer demand to changing regulations and unpredictable weather, market conditions don’t wait. Neither should your data. Learn how @Swiggy, @SencropUK, @CitizensBank, and @GEP_Worldwide use data streaming to respond faster, optimize operations, and cut costs. ->.
0
0
2
🔴Join @gAmUssA live at 12:00 PM ET/9:00 AM for The Streaming Data Paradox Part 1: Connect and Stream.▶️Livestream it on YouTube: .🔗or LinkedIn Live:

linkedin.com
Kafka handles millions of events per second so why is querying still so complex?.Join @gamussa live for The Streaming Data Paradox.Part 1: Connect and Stream.✅ Streaming to Postgres & DuckDB.✅ Kafka Streams patterns that work.✅ Out-of-the-box querying solutions.Don’t miss it

0
0
3
RT @KaiWaehner: At @confluentinc HQ for our global #Telco Summit - strategy, innovation, and execution with 40+ colleagues and partners.….
0
1
0
Apache Kafka® 101 is back!.In this course, @TlBerglund dives into how Kafka treats data as events (not just things) and why that shift changes everything. Then we’ll explore how Kafka works under the hood to power real-time data at scale. Ready to get to know Kafka from the
0
0
5
🚨Happening next week! On July 29th, our hands-on workshop will guide you through the fundamentals of stream processing and Apache Flink. Learn how to filter, join, and enrich streaming data within Confluent Cloud! . →

0
0
2
🔐 ICYMI: Client-Side Field Level Encryption on Confluent Platform is now Generally Available! . Head to our blog to learn how CSFLE can help organizations keep sensitive data safe and maintain flexible, granular access control—all while lowering overhead costs. 👉
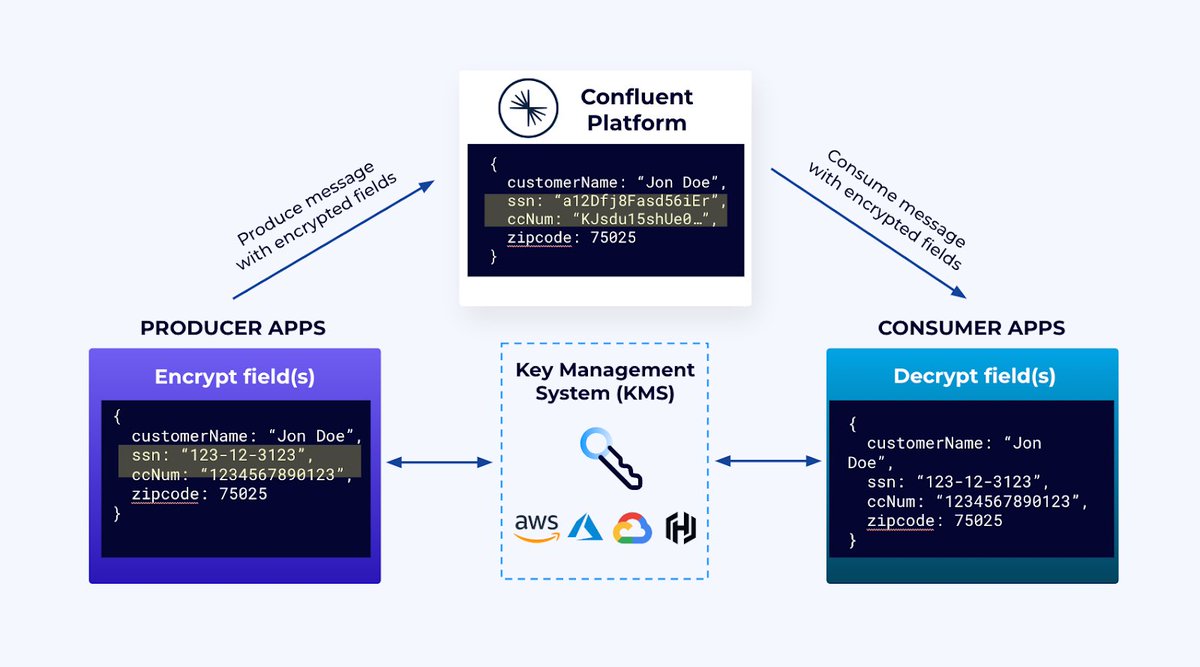
0
0
3
The future of banking is fast, governed, and interoperable and it’s built on real-time data. In this episode of Life Is But A Stream, Swedbank’s Rami Al Lolah reveals how they’re transforming their integration strategy using Apache Kafka® on Confluent. From rethinking compliance
0
0
2

Kafka handles millions of events per second so why is querying still so complex?.Join @gamussa live for The Streaming Data Paradox.Part 1: Connect and Stream.✅ Streaming to Postgres & DuckDB.✅ Kafka Streams patterns that work.✅ Out-of-the-box querying solutions.Don’t miss it
0
0
5