
Chen Liang
@chenliang1_
Followers
143
Following
77
Media
1
Statuses
17
Researcher @Microsoft. Prev: PhD @mlatgt.
Joined December 2013
We released two small yet competitive MoE models, compressed from the 42B Phi-3.5-MoE. Phi-mini-MoE-instruct (2.4B activated, 7.6B total): https://t.co/ce8BNNf4TC Phi-tiny-MoE-instruct (1.1B activated, 3.8B total): https://t.co/VUUJ7kZPgx

1
2
9

Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference” We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to

179
903
6K

We’re open-sourcing the pre-training code for Phi4-mini-Flash, our SoTA hybrid model that delivers 10× faster reasoning than Transformers — along with μP++, a suite of simple yet powerful scaling laws for stable large-scale training. 🔗 https://t.co/Nxsm6FclOX (1/4)
github.com
Simple & Scalable Pretraining for Neural Architecture Research - microsoft/ArchScale
12
215
1K

Learn more about SlimMoE, our expert slimming and multi-stage distillation approach for MoE compression: https://t.co/ye8VjJru0g 🍻 Big shout-out to amazing @li_zichong. This is a joint effort with Illgee Hong, Zixuan Zhang, @yjkim362, @WeizhuChen and @tourzhao.

huggingface.co
3
2
15
We hope these models accelerate MoE research in resource constrained settings — the mini/tiny models can be fine-tuned using a single A100/A6000 with memory efficient optimizers such as Muon and 8-bit Adam.
1
0
1
A quantized version of mini model also available, thanks to the community:
2
0
1

Training LLMs is challenging — huge memory & compute demands! Meet COSMOS, our new hybrid optimizer that blends SOAP’s per-token efficiency with MUON’s memory saving. Dive in: https://t.co/zMwXQHH9mh (1/3)

arxiv.org
Large Language Models (LLMs) have demonstrated remarkable success across various domains, yet their optimization remains a significant challenge due to the complex and high-dimensional loss...
1
7
31

We released Phi-4-mini (3.8B base in LLM), a new SLM excelling in language, vision, and audio through a mixture-of-LoRA, uniting three modalities in one model. I am so impressed with its new audio capability. I hope you can play with it and share with us your feedback. We also

48
144
732

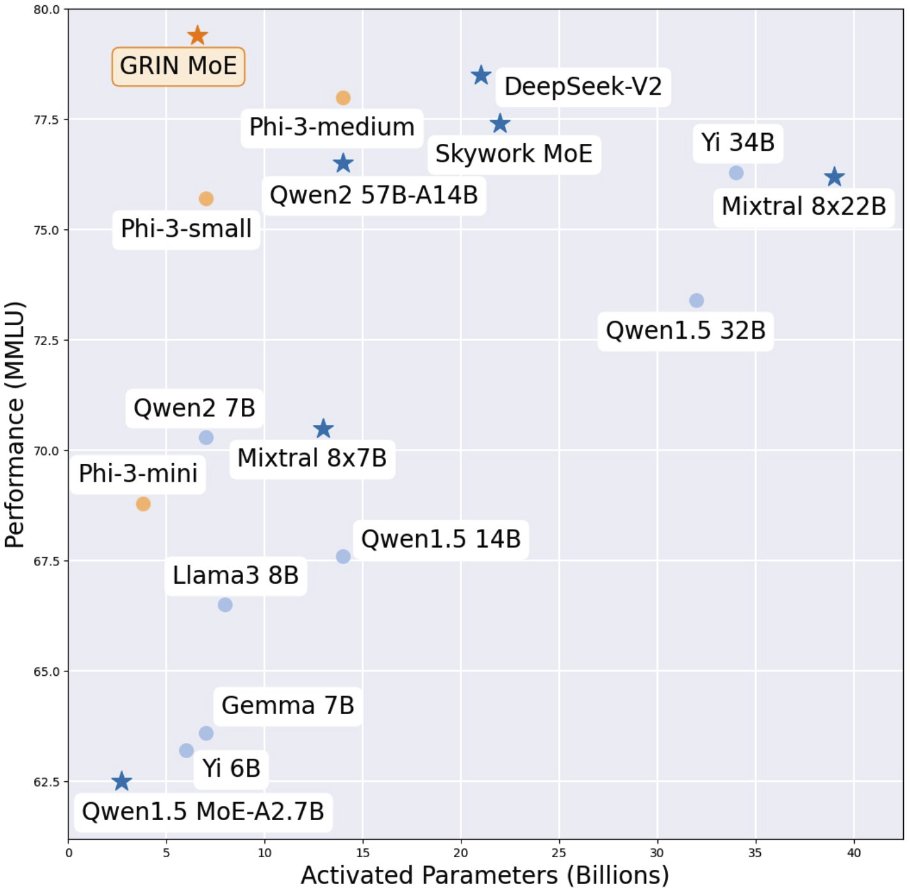
GRadient INformation make MoE 😁 achieve 79.4 on MMLU with 6.6B active parameters & correctly answers the straberry question occasionally highlight: - push 16x3.8B to reach 14B capacity - trained experts have expertise - trained routing invents shared expert - sound gradient





Microsoft releases GRIN😁 MoE GRadient-INformed MoE demo: https://t.co/JmoWsl2Z4M model: https://t.co/sAnyke7IKK github: https://t.co/KOGTLOYnfr With only 6.6B activate parameters, GRIN MoE achieves exceptionally good performance across a diverse set of tasks, particularly in
5
53
272
We released phi 3.5: mini+MoE+vision A better mini model with multilingual support: https://t.co/f7avhBXHYn A new MoE model: https://t.co/FxLILAqpEr A new vision model supporting multiple images:

huggingface.co
14
118
474
Exciting Research Alert! 🚀 Dive into the world of Large Language Models (LLMs) with our latest paper ( https://t.co/44CDneMMzr)! We tackle the performance gap in quantization plus LoRA fine-tuning, introducing LoftQ—an extremely convenient framework to bridge the divide... (1/4)
arxiv.org
Quantization is an indispensable technique for serving Large Language Models (LLMs) and has recently found its way into LoRA fine-tuning. In this work we focus on the scenario where quantization...
1
8
46
Knowledge distillation is very challenging when there is a large capacity gap between the student and teacher models. To address this issue, our ICML 2023 paper ( https://t.co/fz56esfxgC) develops a task-aware layer-wise distillation approach (TED), which aligns the ... (1/3)
1
1
14
Existing methods for pruning neural networks often use the so-called “sensitivity” to measure the importance of weights, and prune those of smaller sensitivities. Our recent work ( https://t.co/jLpu2HJ24z) on ICLR 2022 consider an alternative perspective -- (1/3)

arxiv.org
Recent research has shown the existence of significant redundancy in large Transformer models. One can prune the redundant parameters without significantly sacrificing the generalization...
2
1
31
Adversarial regularization is usually formulated as a min-max game, where the adversary may dominate the game and hurt generalization. Our EMNLP 2021 paper ( https://t.co/c1yzJK9zF8) proposes SALT --Stackelberg Adversarial Regularization to address such an issue. (1/2)
3
11
40

And tomorrow, @chenlianggatech will present our work on distantly-supervised NER at #KDD2020 (still the text mining session). 81.48 F1 points on CoNLL03 without using clean labeled data. Check out the paper at https://t.co/KdEmCXo3YJ and code at https://t.co/wThbnh3epV


0
1
7
Cannot afford manually labelling the training data in your Named Entity Recognition (NER) task? Check our KDD 2020 paper https://t.co/cgTXti873M -- A new self-training framework, which harnesses the power of pretrained language models and distant supervision in open domain NER!


0
5
30