

Chen-Hao (Lance) Chao
@chenhao_chao
Followers
81
Following
78
Media
10
Statuses
19
(1/5) 👑 New Discrete Diffusion Model — MDM-Prime. Why restrict tokens to just masked or unmasked in masked diffusion models (MDM)?. We introduce MDM-Prime, a generalized MDM framework that enables partially unmasked tokens during sampling. ✅ Fine-grained denoising.✅ Better
5
32
251
(5/5) 📰 Paper and Demo. Dive into the full paper, blog, and codebase:.📎 Paper: 🌟 Blog: ⌨️ Github: 🧪 Final thought:.Physicists once thought atoms were indivisible. Then came electrons, quarks, the.
github.com
Partial Masking for Discrete Diffusion Models. Contribute to chen-hao-chao/mdm-prime development by creating an account on GitHub.
1
0
6

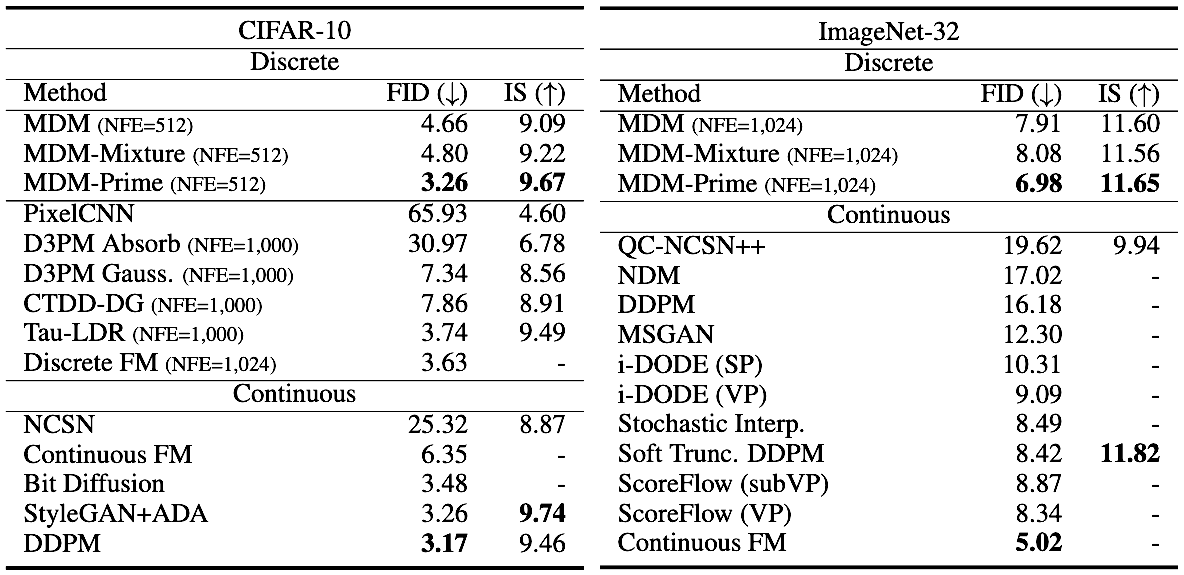
(4/5) 📊 Results. Text Generation (Perplexity; ↓ is better).OpenWebText:. 🥇 MDLM-Prime: 15.36. 🥈 ARM: 17.54. 📉 Baseline MDLM: 22.98. Images (FID; ↓ is better). 🏆 CIFAR-10: 3.26. 🏆 ImageNet-32: 6.98. MDM-Prime sets new SOTA — without any autoregressive formulation.


1
0
2
(3/5) 🪄 Method. MDM-Prime breaks each token into a sequence of sub-tokens, enabling fine-grained masking at the sub-token level. 👉We derive a variational training objective and design novel encoder/decoder modules to handle these intermediate states effectively.


1
0
1
(2/5) 🕶️ Motivation. MDMs unmask tokens at each step based on a fixed probability. But we observed: in 40% of 1024 steps, no token in the sequence changes at all. 🙅♂️That’s redundant computation. 👉MDM-Prime fixes this by letting tokens take intermediate states, interpolated


1
0
3
RT @vahidbalazadeh: Can neural networks learn to map from observational datasets directly onto causal effects?. YES! Introducing CausalPFN,….
0
10
0
RT @rahulgk: 🚀 Problem: Language models struggle with rapidly evolving info and context in fields like medicine & finance. We need ways t….
0
5
0
RT @_akhaliq: Large Language Diffusion Models. introduce LLaDA, a diffusion model with an unprecedented 8B scale, trained entirely from scr….
0
60
0
RT @rahulgk: Finally, if you're interested in understanding how to leverage energy-based normalizing flows, check out @chenhao_chao 's work….
0
1
0
Excited to present a poster at #NeurIPS2024 in person. Join our session on Dec. 12, 11:00 AM–2:00 PM at West Ballroom A-D #6403. Details below:. - NeurIPS Page: - Project Page: #NeurIPS2024 #NVIDIA #RL

0
3
20
(3/3). Test-time demonstration of MEow on the NVIDIA Omniverse Isaac Gym environments. Code: Paper: #NeurIPS2024 #NVIDIA #RL #generative


0
0
1
(2/3). MEow is the first MaxEnt RL framework that supports exact soft value function calculation and single loss function optimization. Superior performance on MuJoCo. Code: Paper: #NeurIPS2024 #NVIDIA #RL #generative

0
0
1
(1/3). Thrilled to announce that our paper, "Maximum Entropy Reinforcement Learning via Energy-Based Normalizing Flow" (MEow), has been accepted at NeurIPS 2024!. Code: Paper: #NeurIPS2024 #NVIDIA #RL #generative

0
0
1
📍Check out our updated blog post where we redefine the DLSM objective function for discrete variables. Read more:.Blog: Paper: #generative #AI #score #diffusion


[ICLR 2022] Denoising Likelihood Score Matching for Condition Score-Based Data Generation.We propose a new denoising likelihood score-matching (DLSM) loss to deal with the score mismatch issue we found in the existing conditional score-based data generation methods.
0
0
0
Check out our work presented at @NeurIPSConf :.blog: paper:
0
0
0
The reinterpretion of a normalizing flow (NF) as an energy-based model enables the generalization of this equality. By separating the linear (Sl) and non-linear (Sn) layers of NF, we can extract the unnormalized density and use importance sampling to estimate the constant Z(θ).


1
0
10
RT @gabrielpeyre: Monte Carlo integration approximates integrals at a rate of 1/sqrt(n), independent of the dimension. .
0
364
0