

Bolin Lai
@bryanislucky
Followers
133
Following
138
Media
20
Statuses
60
PhD student @GeorgiaTech with research interest in multimodal learning, generative models and video understanding. I'm now a visiting student @CSL_Ill in UIUC.
Atlanta, GA
Joined April 2017
Our paper was nominated in the Best Paper Finalist of #ECCV2024. I sincerely thank all co-authors. Our work was also reported by Georgia Tech @ICatGT . My advisor @RehgJim will present it on Oct 2 1:30pm at Oral 4B Session, and Oct 2 4:30pm at #240 of Poster Session.@eccvconf


LEGO can show you how it's done! New @eccvconf work from @bryanislucky, a new generative tool can produce visual images to accompany step-by-step instructions with just a single first-person photo uploaded into the prompt. #wecandothat🐝 @GTResearchNews.
0
6
39

Generate videos in just a few seconds. Try Grok Imagine, free for a limited time.
491
862
4K
RT @gtcomputing: Howdy from Nashville, ya'll! 🎸🤠 . Check out our stars at #CVPR2025, a top @IEEEorg research venue for computer vision expe….
0
2
0

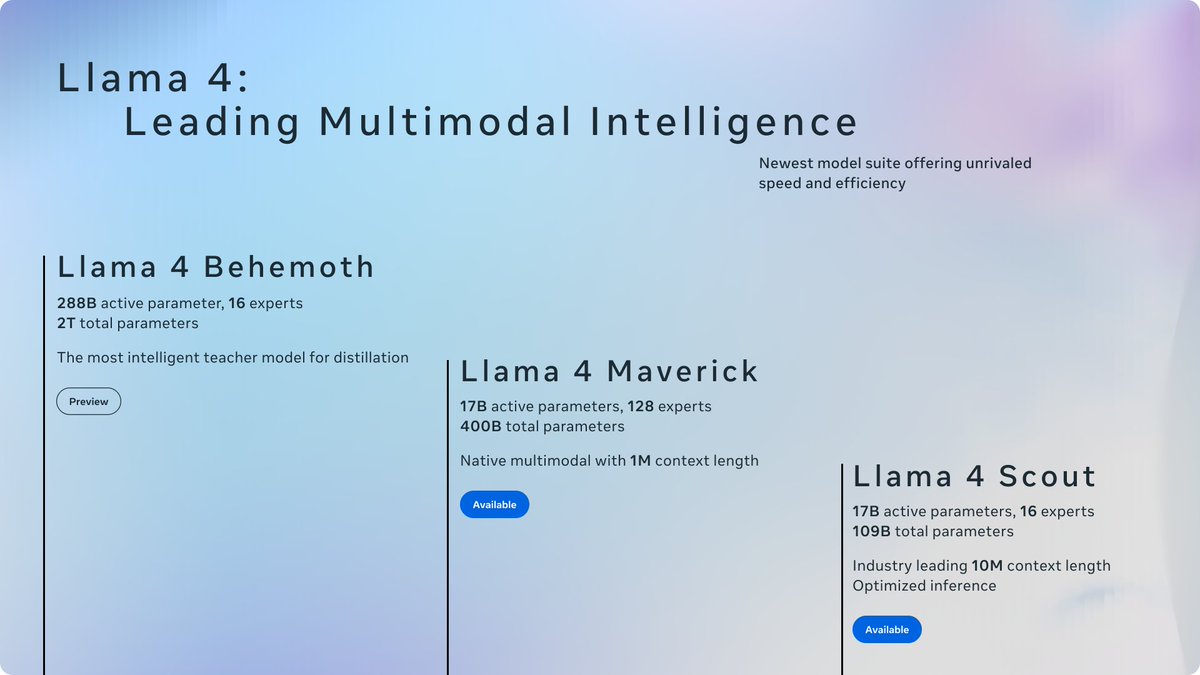
The full Llama4 will contain 2T parameters. This is quite amazing to learn "billion" is insufficient to describe the scale of LLMs.

Today is the start of a new era of natively multimodal AI innovation. Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality. Llama 4 Scout.• 17B-active-parameter model
0
0
1
💻The work was done at GenAI Meta. Thank all collaborators at Meta and my advisor @RehgJim for their strong support.🍻 [8/8]. 📄Paper: ⌨️Code: ▶️Video:
0
0
0
🔎In addition, when different exemplar image pairs are used with the same textual instruction, InstaManip can capture the different visual patterns and apply them in editing query images. [7/8]

1
0
0
📈It’s easy to scale up our model by increasing the number of exemplar images or improving the diversity of visual examples. [6/8]

1
0
0
🏆Our model is able to learn the underlying image transformation from textual instruction and visual examples effectively, and edit the new query image accordingly. [5/8]



1
0
0
💡To avoid learning misleading visual patterns in exemplar images, we introduce an innovative relation regularization strategy, which enforces embedding similarity of similar editing instructions in a batch, and encourages the distinction of different operations. [4/8]

1
0
0
💡We propose Group Self-Attention to decompose in-context learning process into two separate stages – learning and applying, which simplifies the problem into two easier tasks. The model learns a transferrable embedding of desired transformation by next-token prediction. [3/8]

1
0
1
📌Learning from exemplar images requires strong reasoning capability. Diffusion models are good at generation, yet still weak in reasoning. We leverage and enhance the in-context learning feature of autoregressive architectures to achieve SOTA for few-shot image editing. [2/8].
1
0
0
📢#CVPR2025 Introducing InstaManip, a novel multimodal autoregressive model for few-shot image editing. 🎯InstaManip can learn a new image editing operation from textual and visual guidance via in-context learning, and apply it to new query images. [1/8].
1
5
11
RT @maxxu05: My paper RelCon: Relative Contrastive Learning for a Motion Foundation Model for Wearable Data, from my @Apple internship, ha….

arxiv.org
We present RelCon, a novel self-supervised Relative Contrastive learning approach for training a motion foundation model from wearable accelerometry sensors. First, a learnable distance measure is...
0
10
0
An awesome gaze model from my labmate @fionakryan!.

Introducing Gaze-LLE, a new model for gaze target estimation built on top of a frozen visual foundation model!. Gaze-LLE achieves SOTA results on multiple benchmarks while learning minimal parameters, and shows strong generalization. paper:
0
0
4
RT @gtcomputing: #ECCV2024 has honored this computer vision research as one of 15 Best Paper Award candidates 🎉! Congrats to the team and l….
0
2
0
Our ECCV paper is recognized as oral presentation! .Thank all co-authors (@aptx4869ml, Xiaoliang Dai, Lawrence Chen, Guan Pang, @RehgJim ) for your awesome contributions. Our dataset and codes have been released. Project: Code:

github.com
[ECCV2024, Oral, Best Paper Finalist] This is the official implementation of the paper "LEGO: Learning EGOcentric Action Frame Generation via Visual Instruction Tuning". - BolinLai/LEGO
While learning new skills, have you ever felt tired of reading the verbose manual or annoyed about the unclear instructions? Check out our #ECCV2024 work on generating egocentric (first-person) visual guidance tailored to the user's situation! [1/7]. Page:
2
2
14