
The answer is yes and the result is:
distilabeled Hermes 2.5, a model fine-tuned on top of the amazing OpenHermes by
@Teknium1
.
Unlike other DPO fine-tunes is trained with only 6K examples.
It outperforms
@maximelabonne
's NeuralHermes with the same recipe but 54% less samples
1
3
40
Replies
🔥 More is less for DPO, high quality matters!
📢 Dropping our first open dataset and LLM of the year:
💾Meet distilabel Orca Pairs DPO, an improved version of the now famous dataset from
@intel
🏛️And a new OpenHermes model outperforming baselines with 54% less DPO pairs
🧵

5
45
232
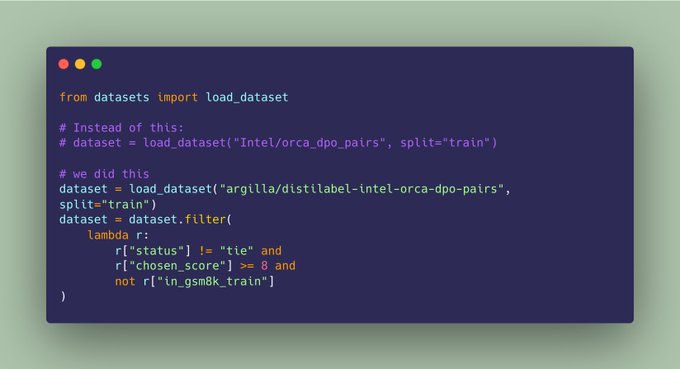
Why improving an existing dpo dataset?
It's by far one the most used dpo datasets on the
@huggingface
hub, but after fixing the UltraFeedback dataset, we wanted to make the best possible version of it.
How?
🧵

1
0
11
Our intuition:
The original dataset just assumes gpt4/3.5-turbo are always the best response.
We know from that's not always the case. Moreover, DPO fine-tuning benefits from diversity of preference pairs.
So how we tested this intuition?
1
0
19
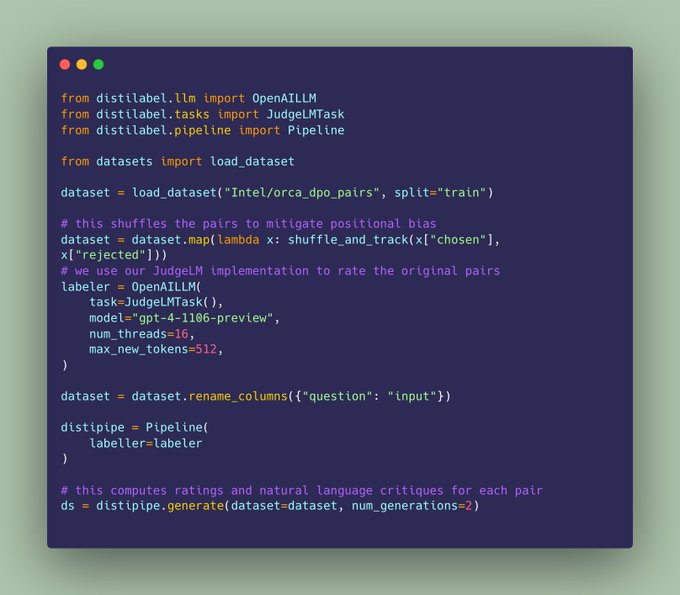
We used distilabel, our open-source AI Feedback framework to build a preference dataset with ratings for each pair and natural language critiques.
It took around 3 hours to build the full dataset and just a few lines of code.
🧵
2
3
33
The resulting dataset confirmed our intuition:
~4,000 pairs had the same rating (tie).
~7,000 pairs were correct according to our AI judge (unchanged).
~2,000 times the rejected response was preferred (swapped).
The next question is: can we build better models with this?
🧵

1
0
22
This new dataset is fully reproducible, aligned with the original, and ready for experimenting with different thresholds and filters.
We're super excited to see what people builds with it!
🧵

2
1
25
As for the model, it's our virtual launching partner and it's available for everyone to play with it!
It shows small but consistent improvements on all benchmarks we tried and remember it uses less than half of the dataset!
🧵

2
0
13
Kudos to
@Teknium1
,
@NousResearch
,
@maximelabonne
, and the
@intel
team, without them none of this would have been possible!
Let's join forces to push the boundaries of truly open AI!
2
2
23
Now, we've helped improving the two most used open datasets for DPO.
But our mission continues, we're already building novel open datasets for supervised and preference tuning with the Open AI community.
Follow us
@argilla_io
and join our mission!
1
0
14