
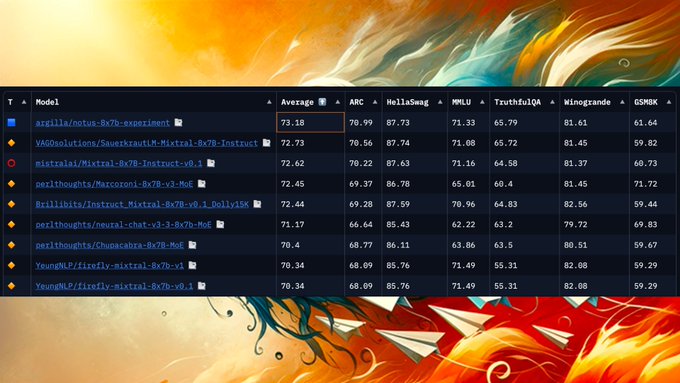
🚀 Open-source AI strikes again! Announcing Notux 8x7B, a fine-tune of Mixtral Instruct with high-quality chat data and DPO.
Notux now the top ranked MoE on the Open LLM leaderboard.
8
84
437
Replies
This is the result of an early experiment at running a second iteration of DPO with our latest UltraFeedback curated dataset.
Interestingly, it confirms smth pointed out by
@winglian
: removing TruthfulQA prompts from UF improves TruthfulQA performance

2
2
25
This model paves the way to efficient DPO of MoE models.
Fine-tuned with a quick adaptation of the
@huggingface
Alignment Handbook
A lot of room for improvement but encouraging results.
Stay tuned with
@argilla_io
for an exciting 2024!

0
3
14

@argilla_io
Congratulations 💯
Interestingly the hardware used was very within reach of most
"used a VM with 8 x H100 40GB hosted in for 1 epoch (~10hr)"

1
1
3

@argilla_io
Why such a tiny improvement over raw Mixtral? Are they already saturated? For smaller models we see 10%+ jumps from fine tuning. Still MMLU much lower than GPT-4/GeminiUltra (90%), is the size the only one to get that sorted?
1
0
1

@argilla_io
cc'ing some people that might be interested:
@rm_rafailov
@_lewtun
@Thom_Wolf
@edwardbeeching
@natolambert
@Teknium1
@alignment_lab
@alexgraveley
1
0
3


@argilla_io
If I want to fine-tune a model for specific purpose, should I use this model, or the original model?
0
0
1

@argilla_io
Congratulations on the open-source AI project! I'm curious to know how you fine-tuned Notux 8x7B and what improvements you've noticed compared to the base model.
1
0
3