
Artem Artemev
@aptemav
Followers
204
Following
3K
Media
5
Statuses
215
Machine Learning PhD @ImperialCollege
Cambridge, England
Joined October 2011
Check out our work "Memory Safe Computations with XLA compiler" at #NeurIPS2022 (with Yuze An, @dyedgreen, @markvanderwilk). The paper and PR can be found at and The poster is Some details in short [1/8].
github.com
Hello, In this pull request I would like to introduce the code of the paper that has been accepted at the NeurIPS 2022. This is the joint work of Yuze An (@melody-an), Tilman Roeder (@dyedgreen), M...
1
5
16
@markvanderwilk will be at the #NeurIPS2022 presenting the poster. If you are at #NeurIPS pop in and say hello. Thanks! [8/8].
0
0
0

Generate videos in just a few seconds. Try Grok Imagine, free for a limited time.
211
68
961
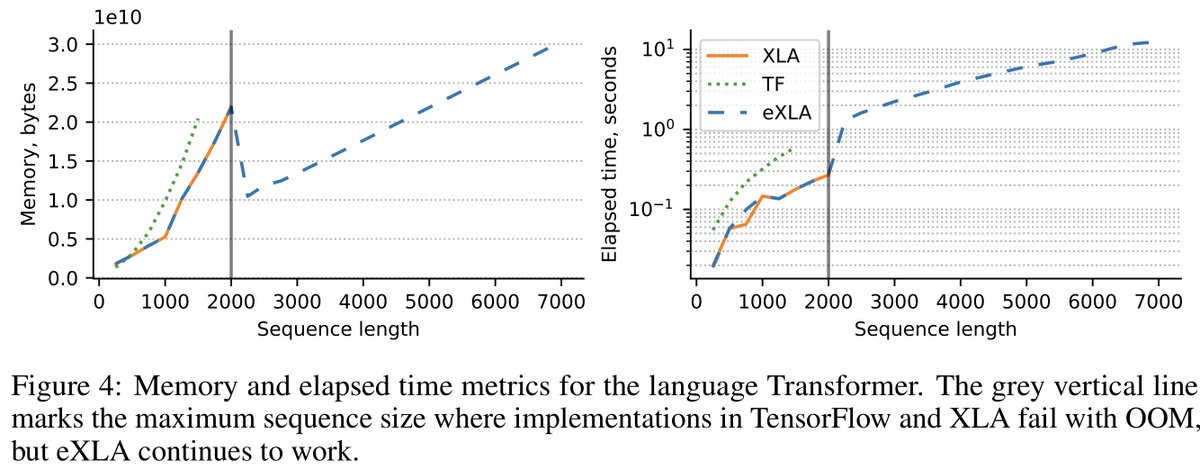
We also applied eXLA to the language transformer model, and in the experiment we modified the sequence length which in turn controls the size of the self-attention block. Out of the box TF implementation fails with OOM with lengths more than 2k, and eXLA runs up to 7k. [7/8]
1
0
0
eXLA allowed to run a OOM-free scaled version of sparse Gaussian process regression model (SGPR) without any change in the SGPR's code from GPflow (. [6/8]

1
0
0
With eXLA we ran kernel matrix-vector multiplication for input vectors of size n=1e6 on a single GPU. The allocation of the intermediate matrix in this expression requires 8TB in fp64 which is non-practical with default ML frameworks. [5/8]

1
0
1
Optimizations in the extension adjust the computational graph in the attempt to make it less memory demanding. Here are some results: [4/8].
1
0
0
This question is the motivation for our work, and the aim is to resolve OOM issues that practitioners might encounter during the ML development or at execution time of the existing ML code. We introduced an extension (eXLA) to the optimization pipeline in XLA compiler [3/8].
1
0
0
Out of memory (OOM) issues can cause a lot of trouble and users need to invest a lot of effort into resolving OOM, and sometimes even re-write the existing software. What if a compiler would sort it out for the user automatically?! [2/8].
1
0
0
RT @avt_im: When working with a Gaussian process, have you ever wondered why Cholesky factorization failed, or a CG solve did not converge?….

arxiv.org
Gaussian processes are frequently deployed as part of larger machine learning and decision-making systems, for instance in geospatial modeling, Bayesian optimization, or in latent Gaussian models....
0
17
0
RT @StatMLPapers: Wide Mean-Field Bayesian Neural Networks Ignore the Data. (arXiv:2202.11670v1 [cs.LG])
arxiv.org
Bayesian neural networks (BNNs) combine the expressive power of deep learning with the advantages of Bayesian formalism. In recent years, the analysis of wide, deep BNNs has provided theoretical...
0
4
0
RT @markvanderwilk: I am still welcoming PhD applicants for 2022 at Imperial College London. We are a growing research group, with clear go….
0
131
0
RT @vdutor: We are organizing a small-scale, offline #NeurIPS2021 satellite event in Cambridge (UK) on the 8th of December. If you are int….
0
34
0
RT @markvanderwilk: Join us to discuss Conjugate Gradient based GP approximations! We make training easier by automatically setting approxi….
0
6
0
RT @markvanderwilk: Current Conjugate Gradient Gaussian Processes require manual tuning to trade off accuracy and speed. Existing guideline….
0
7
0
RT @markvanderwilk: I'm looking forward to speaking tomorrow. I will share some thoughts on:.- How Gaussian processes can help deep learnin….
0
4
0
RT @markvanderwilk: Tomorrow 10 Dec at 11am GMT I will speak at the Bayesian Deep Learning Meetup about **Bayesian Model Selection** and ho….
0
28
0
RT @vincentadam87: Come and chat with the authors of our paper:. Doubly sparse variational gaussian processes!. #A….
0
5
0
RT @arnosolin: Come and work with me. I'm recruiting doctoral students (see DL Aug 17) and post-docs (see https://….

users.aalto.fi
Dr. Arno Solin is an Associate Professor (with tenure) in Machine Learning at the Department of Computer Science at Aalto University, Finland. He is an ELLIS Scholar and holds an Adjunct Professors...
0
22
0
RT @arnosolin: My #ICML2020 tutorial videos on "Machine Learning with Signal Processing" are now freely available:.I: .
0
68
0
RT @TamasGorbe: #Puzzle.Can the Queen pass through all 9 shaded squares in just 4 legal moves starting from this position? .
0
117
0