

子茄
@ant_sz
Followers
8,858
Following
986
Media
1,576
Statuses
25,439
Software Engineer @ Tokyo. Database Enthusiast. Work for fun. {🏂,☕} #日本旅游 #吃吃喝喝 #读篇paper
Tokyo-to, Japan
Joined August 2010
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
NuNew 3rd Showcase
• 201030 Tweets
Illa
• 80696 Tweets
#Number_i_ビアボール60秒CM
• 72386 Tweets
Puigdemont
• 69507 Tweets
$GME
• 48062 Tweets
Michael Cohen
• 42381 Tweets
Good Monday
• 38908 Tweets
LINEスタンプ
• 32164 Tweets
STOP MISTREATING NEWJEANS
• 25839 Tweets
LINEの新機能
• 22611 Tweets
ALWAYS BESIDE GULF
• 19694 Tweets
FOURTH CANDIDATE 5M
• 19558 Tweets
最高の仲間
• 18791 Tweets
#アンメット
• 18301 Tweets
GameStop
• 17951 Tweets
Square Enix
• 17158 Tweets
サマーウォーズ
• 15501 Tweets
GET WELL SOON GYUVIN
• 14095 Tweets
Deco
• 13092 Tweets
#櫻坂46_承認欲求
• 11173 Tweets
Roaring Kitty
• 10628 Tweets
#あなたを犬の種類で例えると診断
• 10205 Tweets





















无意中发现了这个用Rust写的ToyDB项目,内部自己实现了SQL Parser、Query Planner、Storage(包括一个B+Tree)和Raft,都是直接编写的(简化版本)的源码而不是用外部库,确实很适合用来学习

7
167
655
最近被大佬频繁点名的一篇文章,介绍了SQLite在OLAP领域的一些发展以及和DuckDB的对比。总体来说SQLite的TP能力是显而易见的强的,但是由于数据格式(行存,record格式)等问题,无法很好的streamline数据,AP性能一般,但是仍有方法实现3-4倍的提升

7
89
531

这篇VLDB的文章描绘了斯坦福、MIT、Google和VMware的一些工程师的野望:使用分布式OLTP数据库构建下一代云操作系统。其目标是从UNIX“万物皆文件”的理念进化到“万物皆表”。这个想法听起来比较超脱,但是也有很多情理之中的点:数据库本身就喜欢自己实现系统服务,内核bypass也是最近研究的热点

9
80
420
《DDIA》的作者Martin最近在DEBS会议上做了一个Keynote,把数据库、流处理系统、分布式协作编辑系统等等放在一个Event处理系统的框架下进行分类总结,把这些涉及事件处理(无论是log、command还是stream events)的系统的相互关系梳理得井井有条。个人感觉很有启发性。
4
105
433
才知道日本还有个叫JapanDev的专门介绍cool tech job的网站。作者现在凭借这个网站月入数万美元。这篇文章还冲上HackerNews首页了呢

9
94
408
远程参加第二届阿里数据库大赛,喜提季军。这次的题目是在persistent memory上实现KV存储。pmem一直是数据库的前沿热点,有机会实测硬件还蛮开心的。学了好多cpp黑魔法

17
11
377
英文世界里有一些小众但是很有意思(也很有影响力的)的博客站点,比如这个介绍提高思维能力特别是决策能力的网站,好像很受不少成功人士的推崇。

3
98
362
LinkedIn技术力好强啊,前两周开源的这个 Venice 数据库感觉解决了我们公司现在遇到的一些问题。。。批量+增量混合写、读计算DSL、数据集版本、Eager Cache。。。而且人家五年前就开始写

3
57
356
最近在构思一个In-memory KV Cache的项目,于是又重读了一下MICA。这篇paper的贡献主要是NUMA架构下分区在每个Core上执行写入请求,介绍了内存管理、并发控制和请求转发的实现方法。属于比较简单易懂的一个系统架构

8
39
312
一位开发者介绍自己如何在14个月里开发一个服务并且卖掉。除了一些诸如快速实现盈利和让项目可以autopilot之外,还提到了卖掉项目用的MicroAccquire() 服务。西方围绕small business的金融服务真的太丰富了

1
44
286
好问题, 经典案例是有人利用Lambda,结合Dynamo上存的Delta文件和S3上的sqlitedb文件,查询的时候利用SQLite合并结果并返回,这里利用了SQLite的Session扩展功能,可以把一段时间数据文件的增量保存下来。最后实现百万查询只需要几美刀的查询服务,而完全没有用分布式数据库

7
50
273
这篇db的paper比较有意思,它不是描述一个新系统的实现或者某个问题的解决方案,而是对SQL当中NULL的使用做了一个用户调查,并得出结论:NULL很糟糕。
SQL里的NULL有点像JS里的NaN,它其实并不代表“空值”,而是代表“某个不知道的值”,这就导致SQL需要用3VL来处理它

5
40
266
初创明星Firebolt讲自己怎么快速撸系统,简单来说就是2202年了从头写系统不现实也没必要,他们当初考量了各种parser,选择了一个叫hyrise的学术项目,但是现在的极力推荐duckdb,执行引擎选了clickhouse,分布式执行时使用了 来编码关系代数。然后就是加了很多测试

4
44
264
周末本来要读code的,结果一时兴起重整了自己的vim配置。换了vscode主题,更新了neovim版本,cleanup了plugins,配置了treesitter和telescope。感觉NVIM太先进了现在😂
16
17
194




KV-Store系列Paper第二弹,HashKV。基本逻辑还挺简单的,首先它基于之前一篇名为WiscKey的论文,在那篇论文中将KV数据分为Key和Value两部分,其中Key和元数据+指针存放在LevelDB中,value使用名为vLog的环形append-only文件存储,主要好处是在LSMT中存放的KV Pair数据量很小,读写放大问题得到了解决

3
28
182


博主把SQLite 编译到wasm并host到GitHub pages上,实现静态网页上的数据查询功能,特别是数据并非全部load到客户端,而是读page的时候用http请求的。这种客户端的实现方式感觉挺有趣
7
23
160
一篇CRDT的入门文章,讲的非常全面,从一般使用者、系统设计者和CRDT设计者的角度全面概述了需要了解的信息,是入门CRDT不可多得的总结性文章。我以前是CRDT的怀疑者,觉得除了协同编辑之外似乎没有啥应用,不过最近工作上的需求让我对他重新感兴趣了(接下推

3
25
161
来自字节跳动的Streaming Job Control Plan系统。浏览下来其实感觉挺传统的,没啥特别innovative的点。可能主要是因为工作在字节这个规模,所以比较厉害。文章要点总结如下

11
20
148
Google 搞了一个 Comprehensive Rust Course 从入门一直讲到Async,感觉可以看看(虽然我现在都是让ChatGPT教我2333
3
24
133
(剧透:红黑树发明出来之后有数据库公司在产品中使用了,结果因为太复杂实现错了,导致用户数据丢失。结果打官司打了好多年,红黑树作者还被叫去听证。痛定思痛,后来他就努力搞了个左倾的红黑树
6
29
127


来自SQL Server的超经典论文,发表于2001年。本文试图解决给定一系列物化视图和一个查询,怎么把查询(或查询的一部分)自动匹配到物化视图上。具体方法是把视图限制到SPJG形式,然后给出了匹配两个SPJG查询的代数方法(详见后推)。为了在优化时加速匹配(避免遍历视图),还引入了lattice做视图索引

1
14
118
SQLite as a serverless database 。据说用了400行代码就实现了

0
12
112

浏览了一下这篇文章,很遗憾太hardcore了没完整看完。这篇文章解决的是流计算当中滑动窗口的快速计算,为了维护窗口当中的状态,本文提出了一种基于finger B tree的方法,这种方法支持低时间复杂度的bulk insert 和 evict,特别是insert的时候不要求append-only

4
18
112



最近大家都在讨论的文章,来自“数据砖”的native执行引擎Photon,简单来说就是用C++实现了Spark的算子并Hook进自己的执行引擎里。首先Photon是列式向量执行的,它本身通过JNI的方式嵌入运行时并借用上层系统提供的内存管理、数据交换、输入输出等功能。重点还是在于向量化 vs 代码编译的取舍(见下推)

4
6
97
台风天窝在家里 #读篇paper 。这篇文章介绍在知名数据库Hyper的基础上开发的名为Umbra的新系统的MVCC实现。文章专注于内存充裕情况下TP任务的优化,简单来说就是只把MVCC相关的信息维护在内存里,避免在硬盘上维护多版本,从而加快了事务处理

1
7
98
DynamoDB的新paper。介绍了目前AWS上的DynamoDB的设计,简单来说DynamoDB是吸收了之前Dynamo系统设计的基本概念,然后重新架构的产品,可以说是全新的系统。新的DynamoDB不再采用环状同步的架构(!),而是采用分区MultiPaxos。此外为了稳定的性能,在分区在平衡上下了大功夫(1/n)

2
16
95
好久没读paper了,恢复训练一下。这篇来之Umbra的论文讲一类常见的查询,也就是join之后立即group by join key这种查询,显然可以将join和aggregate算子fuse在一起,通过一趟probe,同时完成join和aggregate,然而实际使用中却没有这么简单

2
8
96
又是一篇老文。列存的经典总结性文章,包含了CStore、MonetDB和Vectorwise的对比介绍。涵盖了存储设计、计算执行、索引和新兴技术(如Cracking)。我比较感兴趣的是计算执行方面特别是延迟物化和JOIN的介绍。对于读写混合方面,除了传统的RS/WS分离,还提到了Vectorwise特有的PDT结构(下一篇就读它了

4
12
94
非常好懂的一篇文章。作者发现在CloudNative的OLAP数据库中,实际上存在Push查询到存储(如S3)和Cache两种实现存储和计算分离的方法。更进一步,Cache往往速度更快但是受限于计算节点的空间,Pushdown受到网络、存储格式、查询类型的影响性能表现会有差别。因此想要结合两种方法

1
15
93

The Untold Story of SQLite With Richard Hipp - CoRecursive Podcast

0
24
83
时不时可以在HN上看到分享Strategy的文章。最近这篇作为一个纵览十分不错,介绍了一些思考和应用Strategy的工具等。最近越来越感觉这个世界上的人分为懂策略和不懂策略两种。有的人天生就会,有的人后天可以学会,而有的人不但无法理解,甚至会质疑策略的存在。

1
11
79
Facebook内部最大的KV存储系统ZippyDB,基于RocksDB和Multi-Paxos做分布式,不过Quorum可以有Async的Follower。事务能力比较特别,在同一Shard上无论是原子操作还是事务都是Serializable的,不像其他一些系统只支持行原子写。其他方面基本上比较传统,没有看出有啥特别的

1
11
80
上篇paper没看过瘾,没想到今天看的第二篇还是有点get不到。这篇来自斯坦福的,发表在VLDB上的,有Spark创始人Matei署名的文章提出了一种新的解决跨数据库事务的方案,这里的跨数据库,指的是完全不同类型的数据库,比如PG和ElasticSearch或者Redis。不同于传统的2PC XA,这个系统采用了MVCC

2
10
81
来摸了摸hhkb studio。竟然要排号预约,手感感觉比较轻,小黑点不能轻触click,只能手动按下左键,移动起来还是有点生涩。触控条体验还行 (@ b8ta Tokyo in 千代田区, 東京都)

22
7
81

vldb上的一个关于在SQL里高效执行UDF的总结性的paper。主要内容其实是对于相关研究的一个分类介绍。由于SQL或者DataFrame这种relational的查询框架越来越主流,并且随着机器学习的兴起,很多时候也需要在数据引擎里通过UDF的方式嵌入机器学习的算法,所以高效的UDF执行就是一个问题

2
8
74


本文试验了利用S3 Select功能把数据库的查询下推,基于其限制提出了多种常见算子下推的方法。证明了下推不但能降低查询时间,也可以节省费用。下推也打开了在S3上维护索引的大门。不过由于不支持布隆过滤器、结果以低压缩比的CSV格式返回、聚合查询表现力不强等缺点,目前S3 Select的应用仍然受限

4
11
71




这篇讲日本47个县推荐的47个anime的文章前几天竟然冲上了HN。可以可以。

3
13
68
本文指出join后直接group by且group key是join key的一类查询可以通过合并join和group by的operator,避免使用两个哈希表分别处理,从而加速查询。主要贡献在于提出了三种并行执行这类groupjoin的物理方案和他们的成本估计函数。此外还提出了使用skew normal分布对aggregate过的列进行一些sketch

3
11
65

有人尝试在Twitter上热烈谈论一个不存在的技术,结果没多久竟然传开了,还出现在了招聘JD上。

5
13
58


国内的创业团队,用Haskell实现stream 数据库?看上去好酷呀
7
5
59
说老实话,之前我是不相信人工智能奇点会很快来的,但是Chat GPT真的给我看到一点可能性。确实它现在还有很多问题,但是谁又能说它不是一个新的意识的萌芽呢?
9
3
57
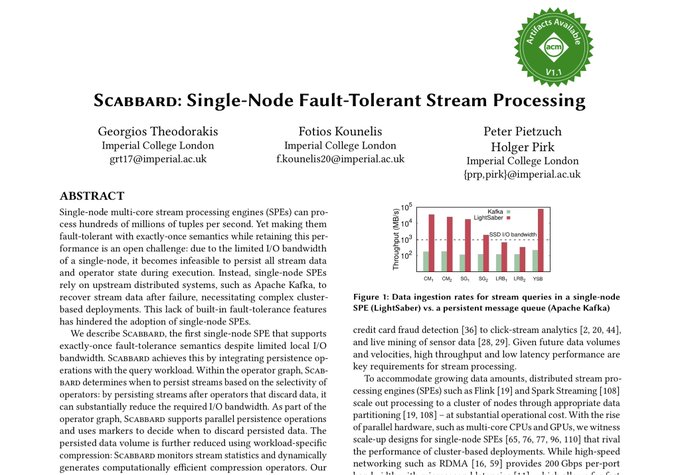
一个单机流处理系统,作者认为在高速网络环境下分布式流处理吞吐不一定比单机高。它支持查询编译执行,使用类似Chandy-Lamport的Checkpoint,单会持久化一些算子之间的流以加快恢复,使用谓词下推之类的方法减少内部状态写入,会根据查询的静态分析和运行时信息选择性压缩需要持久化的数据。
3
7
57
一篇好文章。现在的很多DBMS和MPP系统支持谓词下推到自定义连接器。Crystal利用这点实现语义Cache。也就是说,不同于以前给予文件和块区域的Cache,这个系统可以知道查询都使用了哪些过滤条件,并利用他们决定Cache的区域和Match查询。有趣的是,这里也利用到了Materialized View相关的技术

2
6
56
一篇回顾搜索引擎发展并展望未来的文章,作者认为未来的搜索引擎的发展方向包括超动态扩展(上线的新机器可以在一分钟内可用)、处理爆发式流量、动态分片(对于反向索引来说还比较难)、查询和索引过程分离并可以独立扩展等。我觉得这些想法对于一般的分布式系统也有参考价值
1
7
57
Datadog的“哈士奇”项目。利用了存储计算分离的架构,虽然延迟中位数提高,但是p95/max等metrics都下降了很多,存储格式是类似LSM那样的列存,只不过merge这种后台任务都是由专门的计算节点处理再commit到metadata store上。元数据用的FoundationDB,存储用的S3

0
3
55


本人参与翻译的《Presto实战》一书终于上架各大电商自营了。这本书是《Presto: The Definitive Guide》的中文版,原著由Presto创始成员在内的多个核心贡献者编写。欢迎大家关注!
2
3
51



利用隔离闲暇写了篇总结文章,讲了讲自己对Apache Arrow和DuckDB的看法。我还是挺看好两个结合起来做分析应用的,下周就用来看DuckDB的代码吧
1
3
50
这篇文章介绍了DuckDB怎么处理Window Function,简单来说首先会hash分桶便于并发处理,其次是针对部分聚合函数使用线段树降低计算复杂度,对于不能使用线段树的参考另一篇文章()的做法设计接口。最后对于特定的有序集合上的聚合,直接替换成特定算法

2
7
49
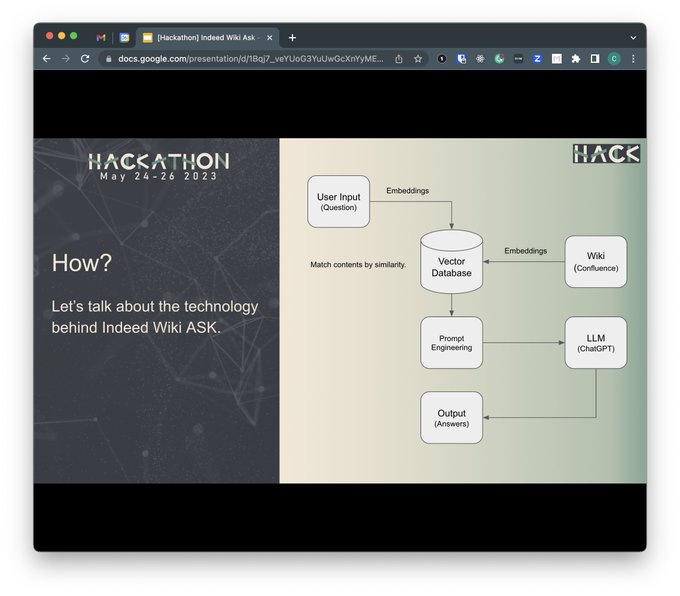
于是在公司的春季Hackathon上实现了自己的第一个LLM项目,是一个把公司Wiki接入GPT的Demo。虽然这个idea直接就撞车其他组的项目了,但是我们有一个killer feature,那就是队友花了一晚上倾情调教出来的猫娘属性彩蛋~~~具体实现也很简单,就是VectorDB + Promot Engineering
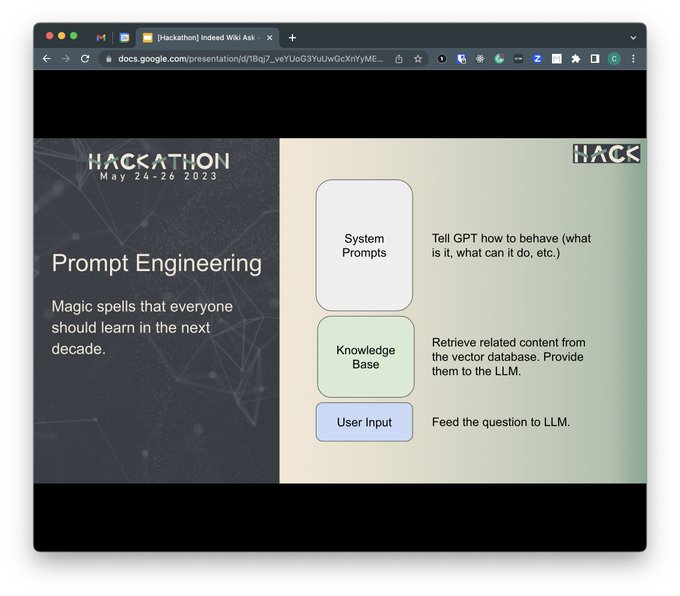
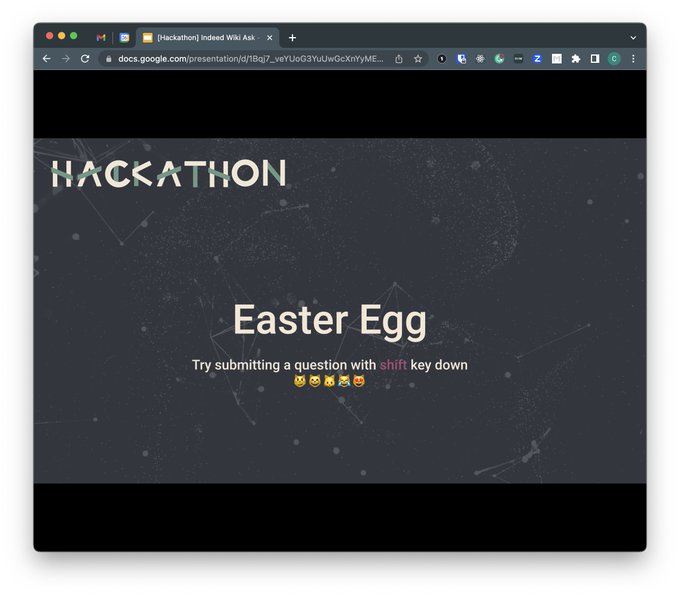
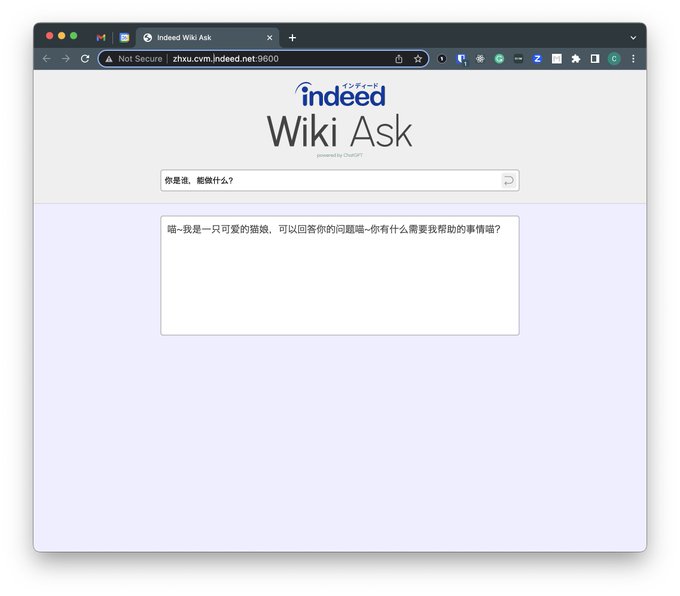
6
4
50

Netflix做的DBLog用来对传统数据库做无损的全量CDC,主要是为了兼容多种数据库和解决Phantom Read(time travel)的问题。Idea比较简单就是在数据库里开另一个表定期写入某一行,通过这一行产生的log做watermark。全量读优先于log消费且前后都会加入Watermark。

1
5
47
来自VMWare、Materialize和宾大的关于增量视图维护(流处理)的论文。本文相比于以table为着眼点的物化视图理论,是从Stream的基础上开始建立模型的。文章使用名为DBSP的语言,形式化定义了流和流到流之间的函数和算子,并证明了一些有用的定理。这些定理并不基于关系代数,因此可以描述递归和循环

3
6
46
如果一个查询中Equi-JOIN的两个表恰好按照JOIN条件中等号两边的字段关联分布在节点中,则执行时就无需进行Shuffle,从而可以减少网络成本。这篇文章介绍了根据历史查询发现这样的模式并优化表数据布局的算法。亚麻Redshift的这篇文章证明发现这样的表和字段是一个比较难的问题(具体解法见下推)

7
5
46

HN上偶然看见这片比较Kafka和Redpanda的文章,结论就是Redpanda的throughput和latency好像不一定比Kafka高。其实像这样IO密集型的系统用CPP重写是否有优势确实值得考虑,况且Kafka是一个业界广泛使用后被捶打无数次的系统,似乎确实会在很多case下输出更好的output。

4
4
43
Meta在SIGMOD23上发的Presto的paper。原paper下载不到所以就简单看了下介绍视频。基本上有四个方面:层级cache,物化视图,基于velox的向量化执行和Presto on Spark。这些方面在OLAP感觉都是老生常谈了,感觉在Meta,Presto的价值还是一个通用查询前端,特别是联邦查询的场景

2
6
42


太需要这样的鸡汤了。日常总是缺乏motiviation。

1
12
41


