
Andrew Wang
@andrewwnlp
Followers
64
Following
41
Media
3
Statuses
15
📢 New Preprint:. 🤔 Humans often reason using elaborate analogies, but can LLMs do the same? 🧵1/5. We introduce AnaloBench, a benchmark of semantically rich analogies that challenges SOTA LLMs 🤖. 📄

1
15
34
RT @Dongwei__Jiang: 🧵 Recent studies show LLMs can self-improve their responses when given external feedback. But how effectively can they….
0
25
0
RT @jieneng_chen: Introducing Genex: Generative World Explorer. 🧠 Humans mentally explore unseen parts of the world, revising their belief….
0
47
0
RT @jackjingyuzhang: 🤖 LLMs are powerful, but their "one-size-fits-all" safety alignment limits flexibility. Safety standards vary across c….
0
40
0
RT @Dongwei__Jiang: Process supervision for reasoning is 🔥! While previous approaches often relied on human annotation and struggled to gen….
0
38
0
RT @nikhilsksharma: Are multilingual LLMs ready for the challenges of real-world information-seeking where diverse perspectives and facts a….
0
18
0
RT @jackjingyuzhang: Thanks @elvis for sharing our work!. 🤔 LLMs often generate fluent but hallucinated text. How can we reliably ✨verify✨….
0
14
0
RT @DongweiJiang8: Can LLMs 🤖 continually improve **their** previous generations to obtain better results?. - Our experiments indicate the….
0
39
0
RT @KevLXu: Ever wondered how LLMs stack up against human crowdsource workers? I'm thrilled to share "TurkingBench", a benchmark of web-bas….
0
14
0
Thank you to my collaborators at @jhuclsp Xiao Ye, Jacob Choi, @YiningLu610, Shreya Sharma, @Lingfeng_nlp, @VijayTiyyala, Nick Andrews, and @DanielKhashabi for their invaluable work and insight.
0
0
4
We are releasing our benchmark on Hugging Face - links to code and data below:. Hugging Face: Code (coming soon): Paper:

github.com
This project focus on curating a robust analogical reasoning dataset for research and development. - JHU-CLSP/AnaloBench
1
0
1
(🧵5/5) While analogical thinking in LLMs can benefit domains such as science and law, elaborate analogies still pose a challenge for LLMs. We look forward to seeing how future research can address this challenge.
1
0
2
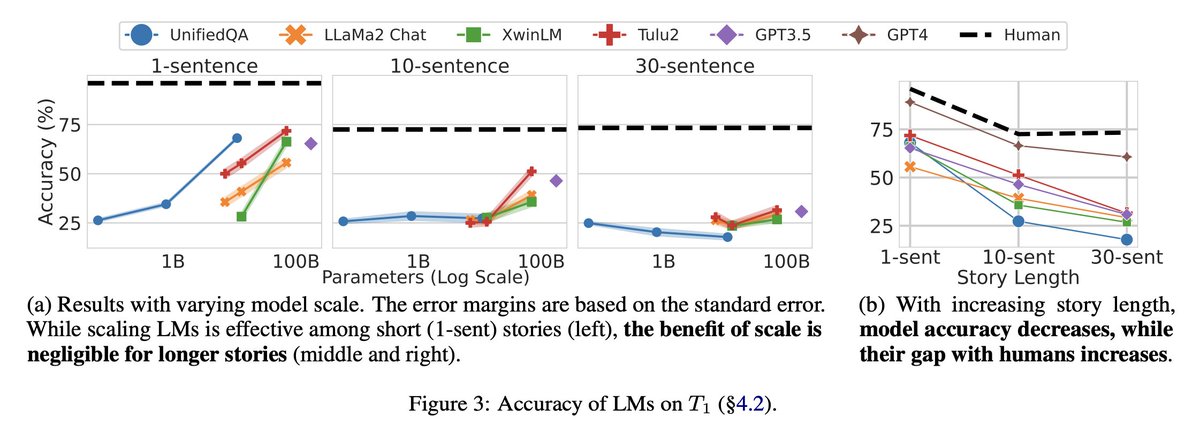
(🧵4/5) To get a better sense of analogical thinking in LLMs, we reduce the collection to four stories. We find that performance decreases with story length (right), and scaling LLMs does not improve performance on longer stories (left). Humans outperform all LLMs tested
1
0
2
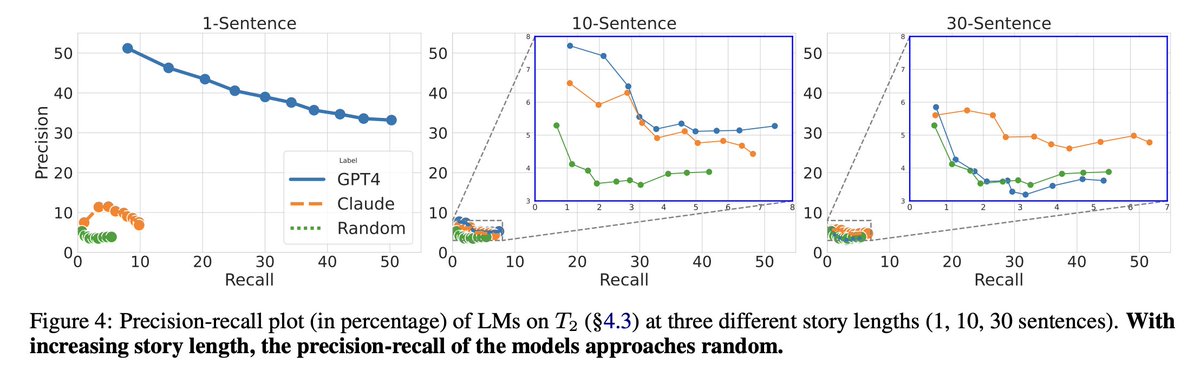
(🧵3/5) Given a story, AnaloBench measures how well an LLM can identify analogous stories from a vast collection. This is akin to how humans can draw on experience to make analogies. In practice, LLMs generally achieve trivial performance, especially on longer stories
1
0
1
(🧵2/5) We collected 340 pairs of analogous, human written stories. These story pairs underwent multiple rounds of review.
1
0
1