

Andrew Liao
@andrewliao11
Followers
293
Following
2K
Media
49
Statuses
491
****Seeking research roles in AI/CV for 2025 Final-yr Ph.D. at CS @UofT @VectorInst 🇨🇦. I make dataset creation less painful. Prev. @nvidia @amazon intern
🇹🇼🇨🇦
Joined January 2016
🚀 New work: LongPerceptualThoughts. We introduce a synthetic data pipeline to fine-tune VLMs with Long Chain-of-thoughts. 𝐆𝐨𝐚𝐥: Help VLMs “think longer” on vision tasks. 3 pts on 5 Vision tasks. 11 pts on V* Bench. 2 pts on MMLU-Pro (text-only). 🌐
1
5
17
🚀 New work: LongPerceptualThoughts. We introduce a synthetic data pipeline to fine-tune VLMs with Long Chain-of-thoughts. 𝐆𝐨𝐚𝐥: Help VLMs “think longer” on vision tasks. 3 pts on 5 Vision tasks. 11 pts on V* Bench. 2 pts on MMLU-Pro (text-only). 🌐
0
3
12
RT @MingyuanWu4: Research with amazing collaborators @JizeJiang, @MeitangLi, and @JingchengYang, guided by great advisors and supported by….
0
14
0
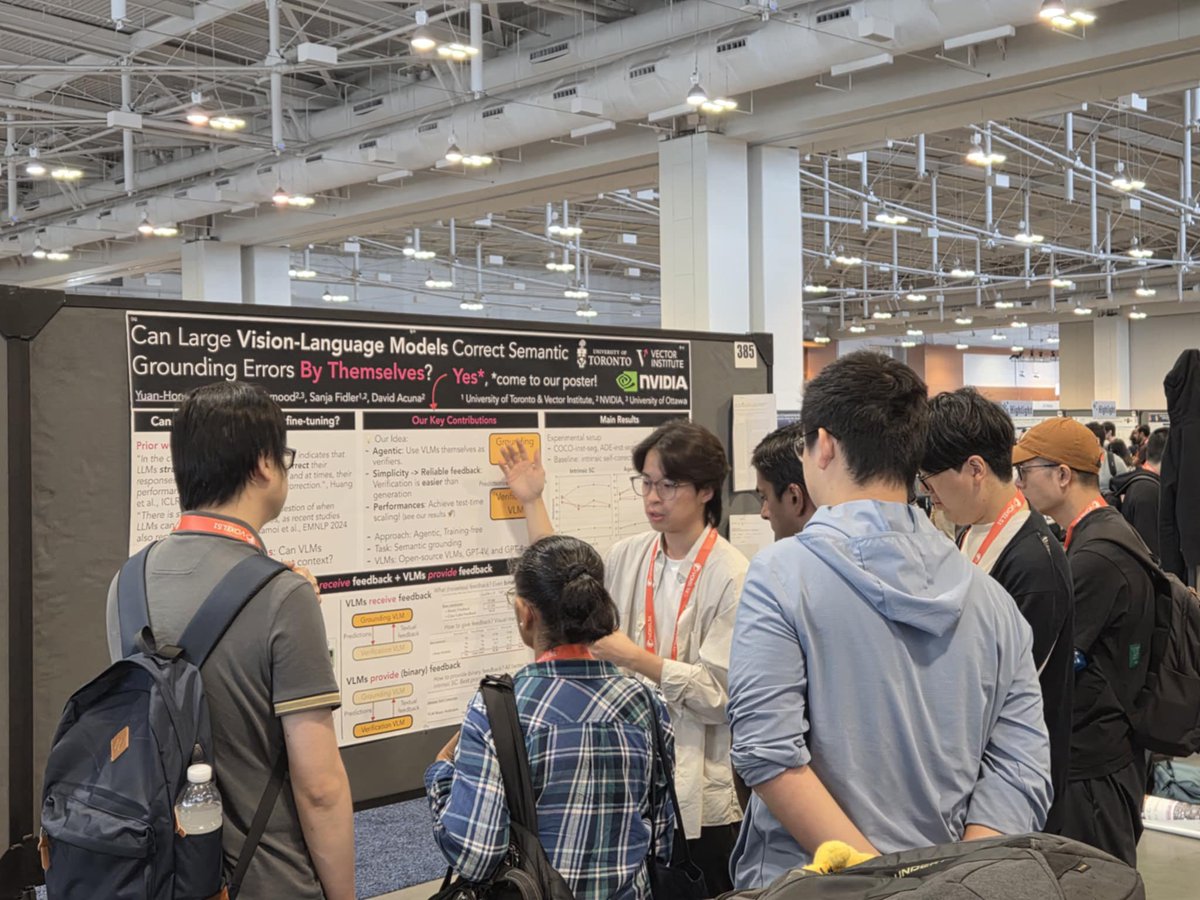
Appreciate the great crowd despite locating at the very end of the boardroom 🤗
0
0
3
RT @BaldassarreFe: DINOv2 meets text at #CVPR 2025! Why choose between high-quality DINO features and CLIP-style vision-language alignment?….
0
103
0
RT @anneouyang: ✨ New blog post 👀: We have some very fast AI-generated kernels generated with a simple test-time only search. They are perf….
0
135
0
Get ready for an exciting morning at CVPR 2025! Our poster session is TODAY.Time: 10:30 a.m. to 12:30 p.m. CDT.Location: ExHall D, Poster #385. Come by to dive into our latest on system-2 thinking in Vision-Language Models! Let's connect and chat! #CVPR2025 #Nashville #VLMs.
Excited to share our CVPR paper next week in Nashville 🎶! Looking forward to connecting with old/new friends. Also, I'm on the job market NOW. Let's discuss system-2 thinking in VLMs! 🤔🤓💡.#CVPR2025 #Nashville #VLMs #reasoning.
1
0
7
RT @JunGao33210520: This year, we have 3 papers in CVPR, discussing the connection between 3D and video models:. GEN3C [Highlight] 3D groun….
0
13
0
RT @DonglaiXiang: 🚨Excited to announce the 1st Workshop on Vision Meets Physics at @CVPR2025!. Join us on June 12 for a full-day event expl….
0
14
0
Excited to share our CVPR paper next week in Nashville 🎶! Looking forward to connecting with old/new friends. Also, I'm on the job market NOW. Let's discuss system-2 thinking in VLMs! 🤔🤓💡.#CVPR2025 #Nashville #VLMs #reasoning.
👉 Vision-Language Models (VLMs) can answer tough questions, but when they make mistakes, can we give them feedback to help revise their answers?. Links:. w/ @rafidrmahmood @fidlersanja @davidjesusacu
0
4
26
RT @lschmidt3: Very excited to finally release our paper for OpenThoughts!. After DataComp and DCLM, this is the third large open dataset m….
0
213
0
RT @ShenzhiWang_THU: 🧐Two papers, opposite opinions. Ours: High-entropy tokens drive all performance gains in LLM RL. Another: Don’t let….
0
70
0
RT @YungSungChuang: 🚨Do passage rerankers really need explicit reasoning?🤔—Maybe Not!. Our findings:.⚖️Standard rerankers outperform those….
0
17
0
Released the code!.Go generate your own Long Perceptual Thoughts. 🧑💻Code:
🚀 New work: LongPerceptualThoughts. We introduce a synthetic data pipeline to fine-tune VLMs with Long Chain-of-thoughts. 𝐆𝐨𝐚𝐥: Help VLMs “think longer” on vision tasks. 3 pts on 5 Vision tasks. 11 pts on V* Bench. 2 pts on MMLU-Pro (text-only). 🌐
0
1
2
When developing this project, it keeps reminding of DAgger (classic imitation learning algo). We first let the model to free generate the imperfect data. Once we detect something wrong, we hand it over to an expert model to fix errors.
🚀 New work: LongPerceptualThoughts. We introduce a synthetic data pipeline to fine-tune VLMs with Long Chain-of-thoughts. 𝐆𝐨𝐚𝐥: Help VLMs “think longer” on vision tasks. 3 pts on 5 Vision tasks. 11 pts on V* Bench. 2 pts on MMLU-Pro (text-only). 🌐
0
0
3
RT @cindy_x_wu: Introducing COMPACT: COMPositional Atomic-to-complex Visual Capability Tuning, a data-efficient approach to improve multimo….
0
44
0
Thanks to my awesome collaborators @s_elflein @riverliuhe @lealtaixe @YejinChoinka @FidlerSanja @davidjesusacu 🔥.
0
0
1
Takeaway:. Structured, reflective reasoning can be taught — even in perception. We show that generating better data can unlock stronger visual reasoning. 🌐Website: 🤗Dataset: 📜Paper:
1
2
2
SOTA reasoning LLMs naturally present cognitive behaviors in reasoning traces. What about 𝐿𝑜𝑛𝑔𝑃𝑒𝑟𝑐𝑒𝑝𝑡𝑢𝑎𝑙𝑇ℎ𝑜𝑢𝑔ℎ𝑡𝑠?. Our 3-stage pipeline significantly injects these behaviors in vision-centric tasks! 📈

1
0
1
Stage 3 – Think Harder:. We prompt a reasoning LLM (e.g., R1-Distill) to expand the short CoTs using cues like “𝑊𝑎𝑖𝑡,” or “𝐻𝑚𝑚,”. This introduces system-2 behaviors like verification, subgoal setting, and backtracking. See the analysis 👇
1
0
1
Stage 2 – Think:. We use the VLM to generate short CoTs — often time shallow reasoning. Why?.Staying close to the VLM’s original output distribution avoids disrupting its learned behavior.
1
0
1