
Andrew Ilyas
@andrew_ilyas
Followers
3K
Following
688
Media
34
Statuses
315
Stein Fellow @ Stanford Stats (current) | Assistant Prof @ CMU (incoming) | PhD @ MIT (prev)
Joined February 2013
“How will my model behave if I change the training data?”. Recent(-ish) work w/ @logan_engstrom: we nearly *perfectly* predict ML model behavior as a function of training data, saturating benchmarks for this problem (called “data attribution”).

11
73
411
RT @JennyHuang99: 🚨Past work shows: dropping just 0.1% of the data can change the conclusions of important studies. We show: Many approxim….
0
8
0
We’re excited to see how MAGIC’s high-fidelity estimates of model behavior can unlock better model debugging, improved data quality, and efficient unlearning. More details in the paper:

1
1
34
In our paper we introduce MAGIC (Metagradient-based Attribution via Ground-truth Influence Computation). MAGIC leverages recent advances in metagradient calculation to achieve near-"perfect" data attribution at the cost of only 2-3x that of model training!

1
1
19
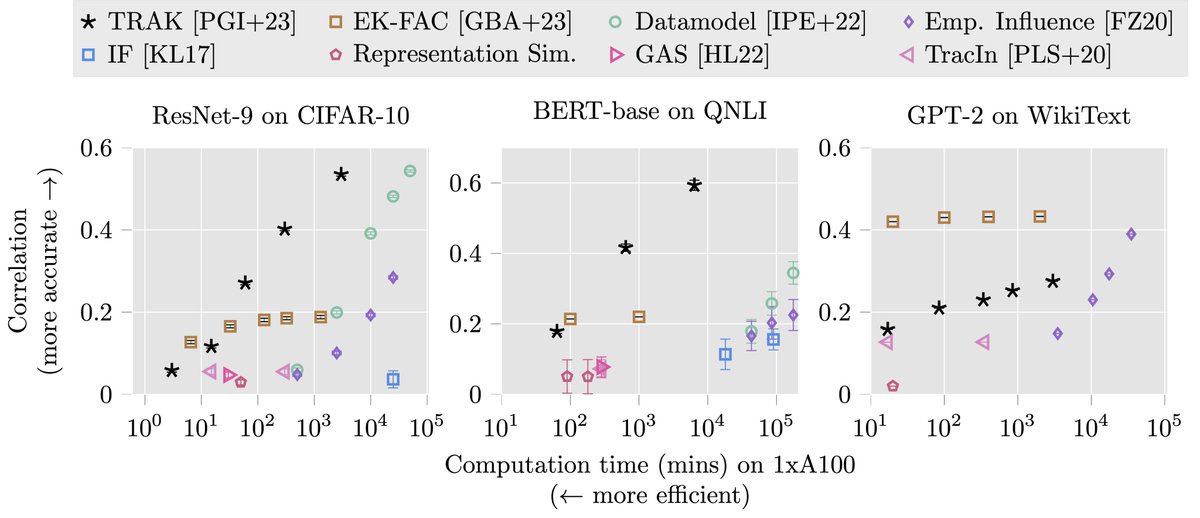
Now, predictive data attribution methods for deep learning are okay but not great: . On standard evals (e.g., predicting changes to model loss on CIFAR-10 examples), data attribution methods' predictions get about ~40% correlation with ground truth and use lots of compute.
1
0
8
Data attribution is the problem of understanding how specific training points affect ML predictions. It has applications across safety, efficiency, data valuation. (For more, see our ICML tutorial w/ @kris_georgiev1 and @smsampark:

1
1
20
RT @YiweiLu3r: (1/2) Successfully defended my thesis today! I was incredibly fortunate to work with my amazing supervisors Yaoliang Yu, Sun….
0
2
0
RT @cen_sarah: 📢Sign up to attend and present a poster/spotlight talk at the Summer Workshop on Collaborative Learning and Data Sharing!….
0
3
0
RT @ShivinDass: Ever wondered which data from large datasets (like OXE) actually helps when training/tuning a policy for specific tasks?. W….
0
28
0
RT @cen_sarah: This work has been a long time coming and I'm so grateful to my collaborators for helping make this work possible. Main tak….
0
5
0
RT @aleks_madry: Building AI systems is now a fragmented process spanning multiple organizations & entities. In new work (w/ @aspenkhopkin….
0
24
0
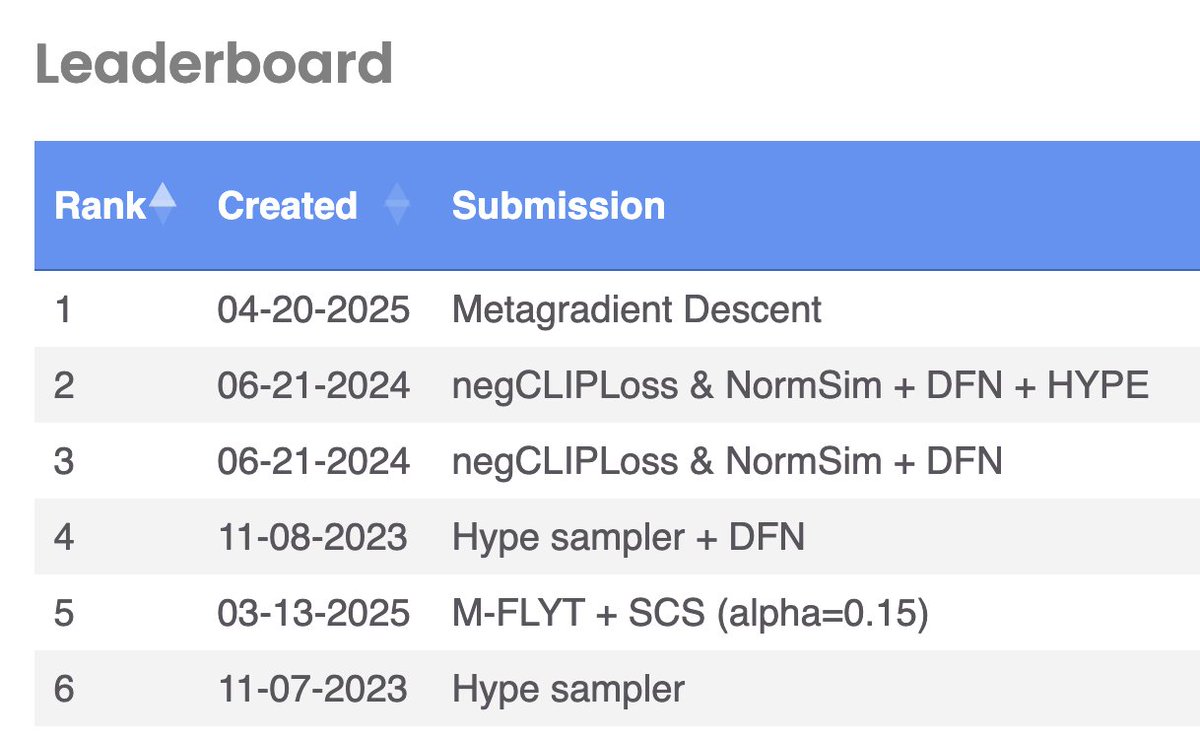
Metagradient descent is #1 on the DataComp small *and* medium leaderboards!. Really excited about the potential to design training routines by "just doing gradient descent.". w/ @logan_engstrom Ben Chen @wsmoses @axel_s_feldmann @aleks_madry. More exciting results coming soon :)


Want state-of-the-art data curation, data poisoning & more? Just do gradient descent!. w/ @andrew_ilyas Ben Chen @axel_s_feldmann @wsmoses @aleks_madry: we show how to optimize final model loss wrt any continuous variable. Key idea: Metagradients (grads through model training)

2
2
31
Really big thanks to @srush_nlp and @swabhz for the invitation & for putting together such a fun workshop. My talk: The paper: Joint work with @logan_engstrom, Ben Chen, @axel_s_feldmann, Billy Moses, and @aleks_madry.
0
2
12
Had a great time at @SimonsInstitute talking about new & upcoming work on meta-optimization of ML training. tl;dr we show how to compute gradients *through* the training process & use them to optimize training. Immediate big gains on data selection, poisoning, attribution & more!.
Want state-of-the-art data curation, data poisoning & more? Just do gradient descent!. w/ @andrew_ilyas Ben Chen @axel_s_feldmann @wsmoses @aleks_madry: we show how to optimize final model loss wrt any continuous variable. Key idea: Metagradients (grads through model training)
1
3
32
Was really fun working on this project, and not just because of the results: huge shoutout to @logan_engstrom (who is graduating soon 👀) and our amazing **undergraduate student** Ben Chen!.
Want state-of-the-art data curation, data poisoning & more? Just do gradient descent!. w/ @andrew_ilyas Ben Chen @axel_s_feldmann @wsmoses @aleks_madry: we show how to optimize final model loss wrt any continuous variable. Key idea: Metagradients (grads through model training)
0
0
15
RT @logan_engstrom: Want state-of-the-art data curation, data poisoning & more? Just do gradient descent!. w/ @andrew_ilyas Ben Chen @axel_….
0
31
0
@sanmikoyejo @SadhikaMalladi @coallaoh @baharanm After another very lively poster session, our final talk of the day from @coallaoh - who is talking about the interactions between ML, attribution, and humans!

2
1
9
@sanmikoyejo @SadhikaMalladi @coallaoh @baharanm Our second-last talk of the day - Robert Geirhos on “how do we make attribution easy?”

1
1
7
@sanmikoyejo @SadhikaMalladi @coallaoh @baharanm One great poster session (and lunch) later - @baharanm on data selection for large language models!
1
1
6