
Amey Agrawal
@agrawalamey12
Followers
577
Following
3K
Media
49
Statuses
222
Systems for AI | Forging @ProjectVajra | CS PhD candidate @gtcomputing, visiting scholar @MSFTResearch
Atlanta, GA
Joined January 2016
A few of us at Georgia Tech are building Vajra, an open‑source inference engine built for the next wave of serving problems:. * Multimodal streaming first – Low‑latency realtime video, audio pipelines.* Highly distributed computing - Managing 1000s of GPUs.* Hierarchical Graph.
0
4
15
AI coding agents are changing the tech debt equation fundamentally. It has never been easier to do iterative abstraction design.
1
0
2
Easiest way to burn your claude code context window -- feeding it gcc error logs.
0
0
2
RT @ramaramjee: Evaluation of LLM serving systems is tricky because several factors influence performance (prefill length, decode length, p….
0
2
0
After hitting evaluation puzzles like this in our own work, we analyzed patterns across LLM inference papers and identified 8 systematic evaluation issues that can make performance comparisons misleading. We have compiled a practical evaluation checklist to help avoid these.
0
3
5
When sequence lengths vary wildly (10 tokens to 100K+), normalizing by length seems like the obvious approach. But normalizing data results in loss of critical information. Let's calculate how those normalized latency numbers translate to user experience:. 📊 At 0.1 s/token ×.
1
0
3
The bitter lesson of AI infra: The hardest part about building faster LLM inference systems is not designing the systems, but rather it is evaluating if the system is actually faster! 🤔. This graph from a recent top systems venue paper about long-context serving shows average

1
10
23
Interesting work on long context inference from @nvidia, where they scale KV parallelism on gb200-nvl72 systems! To learn more about accelerating long context inference and trade-offs between different parallelism dimensions checkout out our paper, Medha:

arxiv.org
As large language models (LLMs) handle increasingly longer contexts, serving long inference requests of millions of tokens presents unique challenges. We show that existing work for long context...

What if you could ask a chatbot a question the size of an entire encyclopedia—and get an answer in real time?. Multi-million token queries with 32x more users are now possible with Helix Parallelism, an innovation by #NVIDIAResearch that drives inference at huge scale. 🔗
0
5
14
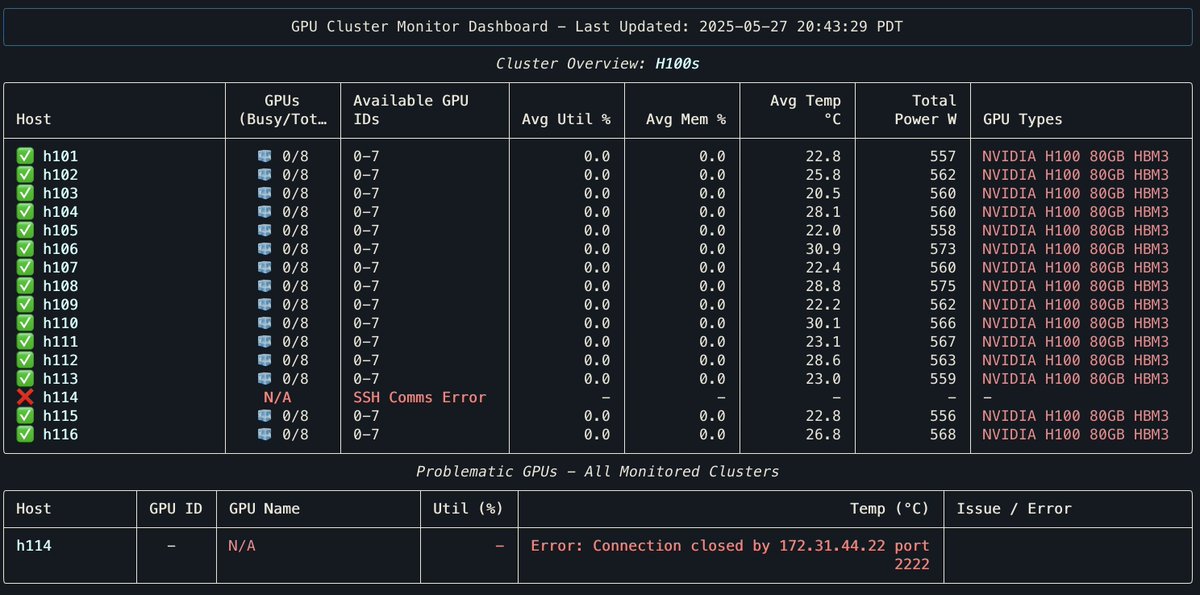
Built a gpu cluster monitor cli dashboard, because code is apparently cheap now. pip install gpu-cluster-monitor. Github:
1
1
20
Super cool paper, deepseek style communication-computation overlap on steroids! Deepseek creates separate microbatches to overlap communication and communication --- thus hiding the EP communication overhead. TokenWeave splits existing batch into smaller microbatches to overlap.

TokenWeave is the first system that almost fully hides the ~20% communication cost during inference of LLMs that are sharded in a tensor-parallel manner on H100 DGXs. Check out the thread/paper below!.
0
1
9
RT @agrawalamey12: Super excited to share another incredible systems that we have built over the past two years! Training giant foundation….
0
13
0
Maya offers a transparent, accurate, and efficient way to model and optimize large-scale DL training without needing expensive hardware clusters for exploration. A crucial step towards sustainable AI!. Read the paper: Work done with @Y_Srihas , @1ntEgr8 ,.

arxiv.org
Training large foundation models costs hundreds of millions of dollars, making deployment optimization critical. Current approaches require machine learning engineers to manually craft training...
0
1
2
Maya's lightweight emulation enables rapid exploration of the vast configuration space. We built Maya-Search on top, using techniques like Bayesian Optimization to automatically find near-optimal training recipes in under an hour on a single CPU node! ⚡.
1
0
2
The Impact: Accurate prediction means better optimization choices! Maya consistently identifies training configurations within 2% of the optimal cost, while baseline modeling errors led to choices up to 56% more expensive. That's potentially millions saved! 💸.
1
0
1
Benefits of Emulation:.✅ Transparency: Works with YOUR code, YOUR framework. No manual translation needed. Low adoption barrier. ✅ Generality: Not tied to specific models or optimization techniques. ✅ Accuracy: Captures real behavior, eliminates the semantic gap. Our eval.
1
0
1
The Maya Pipeline:.1️⃣ Emulate: Run unmodified code, capture API traces on CPU. 2️⃣ Predict: Use pre-trained models to estimate runtimes for the captured kernels/collectives on the target hardware. 3️⃣ Simulate: Replay the annotated trace in an event-driven simulator, modeling.
1
0
1