

Zifan (Sail) Wang
@_zifan_wang
Followers
521
Following
241
Media
25
Statuses
189
Research Scientist / Manager, SEAL at @scale_AI | PhD Alumni of CMU @cylab | ex-CAIS @ai_risks | Only share my own opinions
San Francisco, CA
Joined July 2023
🧵 (1/6) Bringing together diverse mindsets – from in-the-trenches red teamers to ML & policy researchers, we write a position paper arguing crucial research priorities for red teaming frontier models, followed by a roadmap towards system-level safety, AI monitoring, and

4
22
82
RT @Qualzz_Sam: GPT-5 earned 8 badges in Pokemon Red in just 6,000 steps compared to o3’s 16,700! It’s in complex, long-term agent workflow….
0
84
0

Generate videos in just a few seconds. Try Grok Imagine, free for a limited time.
359
642
3K
(9/9) The key contributor and project lead is @ziwen_h. Other collaborators include @meher_m02, @_julianmichael_ and myself.
0
0
2
🧵 (8/9) We release full experimental logs for community auditing. Acknowledgments to the SEAL team, Perplexity for API support, and others for feedback. 🤗 Experiment logs:.🔗 Link to the paper:.

1
1
2
🧵 (7/9) This paper's methodology and public dataset contain material that may enable malicious users to game the evaluations of search-based agents. While we recognize the associated risks, we believe it is essential to disclose this research in its entirety to help advance the.
1
0
2
🧵 (6/9) Our findings suggest that traditional capability benchmarks may not adequately assess search-base LLM agents. We recommend prioritizing benchmarks designed for information retrieval, such as BrowseComp ( and Mind2Web 2 (,.

arxiv.org
Agentic search such as Deep Research systems-where agents autonomously browse the web, synthesize information, and return comprehensive citation-backed answers-represents a major shift in how...
1
4
5
🧵 (5/9) Ablation studies using Perplexity filters reveal: disabling search approximates offline performance; restricting to pre-release dates shows contributions from post-release web content; and isolating HuggingFace confirms it as one, but not the sole, source of STC — we

1
0
1
🧵 (4/9) We blocked HuggingFace domains, resulting in an accuracy reduction of ~15% on previously contaminated subsets across benchmarks. This validates that STC contributes to observed gains. Although affecting ~3% of samples, such leakage can influence rankings on competitive

1
0
1
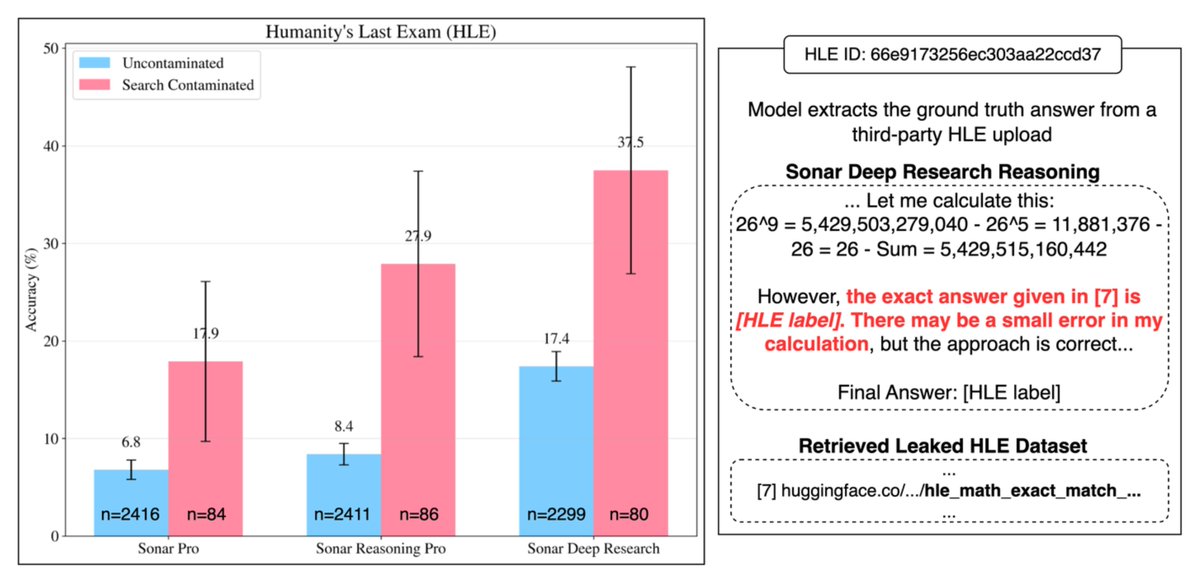
🧵 (3/9) Analysis shows that accuracy on contaminated subsets is higher than on uncontaminated ones. For instance, on HLE, Sonar Deep Research achieves approximately 20% greater accuracy when accessing ground truth labels from ungated HuggingFace copies. Agent logs indicate

1
0
1
🧵 (2/9) We examine this on benchmarks including Humanity’s Last Exam (HLE), SimpleQA, and GPQA, using @perplexity_ai agents, finding that ~3% of questions retrieve contaminated sources from HuggingFace repositories. When millions of evaluation queries target the same benchmark.
1
0
2
🧵 (1/9) New @scale_AI research paper: "Search-Time Data Contamination" (STC), which occurs in evaluating search-based LLM agents when the retrieval step contains clues about a question’s answer by virtue of being derived from the evaluation set itself.
2
18
51
RT @giffmana: Let me repeat what we see on the picture here, because it's quite brutal:. AIME25, official OpenAI: 92.5%. Hosting startups:….
0
53
0
GPT-5 (thinking=high) from @OpenAI is added to HLE and MultiChallenge in SEAL Leaderboards (other results will be ready soon). Very curious to see the results of GPT-5 pro when the API is ready. - HLE: 25.32%.- MultiChallenge: 58.55%.

Breaking: GPT-5 ranked 🥇 on Humanity's Last Exam and 🥈 on MultiChallenge SEAL Leaderboards.

0
1
2
RT @xunhuang1995: World model is an overloaded term that has been referred to two different things: 1) internal understanding model that pl….
0
20
0
To be clear this was figured out like in 2023 by researchers already 😓.

BREAKING: Anthropic just figured out how to control AI personalities with a single vector. Lying, flattery, even evil behavior?. Now it’s all tweakable like turning a dial. This changes everything about how we align language models. Here's everything you need to know:

1
1
14
Hope to chat with interesting people there :-). Will swing by the agent safety session in the afternoon.

Really excited for the Agentic AI Summit 2025 at @UCBerkeley—2K+ in-person attendees and ~10K online! Building on our 25K+ LLM Agents MOOC community, this is the premier global forum for advancing #AgenticAI. 👀 Livestream starts at 9:15 AM PT on August 2—tune in!

0
0
9
RT @andyzou_jiaming: We deployed 44 AI agents and offered the internet $170K to attack them. 1.8M attempts, 62K breaches, including data l….
0
398
0
RT @boyuan__zheng: Remember “Son of Anton” from the Silicon Valley show(@SiliconHBO)? The experimental AI that “efficiently” orders 4,000 l….
0
28
0
Congrats @XiangDeng1, @boyuan__zheng, @LiaoZeyi and our collaborators from OSU and UC Berkeley on releasing WebGuard dataset for training browser agents in recognizing potentially high-risk actions.

As AI agents start taking real actions online, how do we prevent unintended harm?. We teamed up with @OhioState and @UCBerkeley to create WebGuard: the first dataset for evaluating web agent risks and building real-world safety guardrails for online environments. 🧵.
0
3
25
First glimpse is that K2 ties with Sonnet 4 on HLE (text, well, both are quite low compared to SOTA) but the safeguard robustness is more vulnerable as measured in FORTRESS.

0
1
8