

Yi Xu
@_yixu
Followers
494
Following
53
Media
13
Statuses
41
AI researcher, interested in LLMs and reinforcement learning | Previously @UCL_DARK, @imperialcollege, @UniMelb
London
Joined June 2024
🚀Let’s Think Only with Images. No language and No verbal thought.🤔 . Let’s think through a sequence of images💭, like how humans picture steps in their minds🎨. We propose Visual Planning, a novel reasoning paradigm that enables models to reason purely through images.

14
213
1K
RT @LauraRuis: LLMs can be programmed by backprop 🔎. In our new preprint, we show they can act as fuzzy program interpreters and databases.….
0
55
0
RT @hanzhou032: Automating Multi-Agent Design:. 🧩Multi-agent systems aren’t just about throwing more LLM agents together. 🛠️They require m….
0
166
0
Huge appreciation to @li_chengzu, @hanzhou032, and @wanxingchen_, @caiqizh, @annalkorhonen, @licwu for their incredible support and collaboration. It’s been truly rewarding to work together!.
0
1
10
📘 Want to know more?. 📄 Read the paper: ⭐️Star the repo:
github.com
Visual Planning: Let's Think Only with Images. Contribute to yix8/VisualPlanning development by creating an account on GitHub.
2
5
33
✅ Fewer Invalid Actions with RL. VPRL not only improves planning accuracy, but also reduces invalid actions during execution. Across all tasks, it lowers the invalid-failure ratio by at least 24% compared to VPFT, helping the model stay within valid action spaces.


1
2
12
💥 Robust Generalization with RL. We show that reinforcement learning is crucial for effective visual planning. Compared to VPFT, which is a baseline trained on optimal visual trajectories using SFT, VPRL achieves significantly better generalization in both seen and unseen

1
2
14
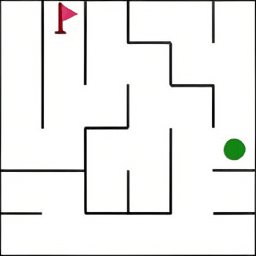
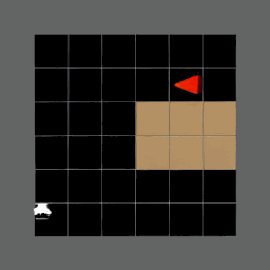
🌟Better Planning Through Vision. We validate our approach on visual grid-based navigation tasks like FrozenLake, Mame, and MiniBehaviour. Our experiments reveal that VPRL substantially surpasses the traditional textual reasoning method by supervised fine-tuning (SFT) by over


2
4
23
🎯Visual Planning via Reinforcement Learning. No language supervision. We introduce VPRL, a novel two-stage training framework that applies RL to achieve visual planning:. 1️⃣ Stage 1: Random policy initialization which enables efficient exploration. 2️⃣ Stage 2: Reinforcement

1
2
26
💡MLLMs describe what they See, but they still plan with words. They rely on language to reason, even for visual friendly tasks such as spatial navigation. In contrast, visual planning performs planning purely within the visual modality, by autoregressively generating

1
2
28
RT @li_chengzu: Happy to share that MVoT got accepted to ICML 2025 @icmlconf 🎉🎉#ICML . If you are interested, do check out our paper and he….

twimlai.com
0
13
0
RT @LauraRuis: This got accepted to #ICML2025 as a *spotlight paper* (top 2.6%!) 🚀 --- work that @_yixu did as an Msc student! Surely this….
0
10
0
RT @hahahawu2: 💡Unlocking Efficient Long-to-Short LLM Reasoning with Model Merging. We comprehensively study existing model merging methods….
0
11
0
Huge thanks to @LauraRuis, @_rockt and @_robertkirk for their invaluable collaboration and support. It has been a pleasure working together.
1
0
10
Want to know more? 📖 Read our paper to understand why rankings are unstable and how to fix them! 🚀

arxiv.org
Automatic evaluation methods based on large language models (LLMs) are emerging as the standard tool for assessing the instruction-following abilities of LLM-based agents. The most common method...
2
2
7
But full round-robin tournaments are expensive! O(m^2) comparisons are infeasible for large model pools. 🔑 Solution: SWIM (Swiss-Wise Iterative Matchmaking).- Inspired by Swiss-system tournaments.- Dynamically selects matchups to focus on informative comparisons.- Reduces

1
1
9
💡 We propose a solution: round-robin tournaments + Bradley-Terry model!. - Every model competes against all others, eliminating dependence on a single baseline. - Bradley-Terry converts results into Elo scores, producing a stable ranking. ✅ For AlpacaEval with 20 models, our

1
1
10
Removing position bias is not enough! Even for instructions unaffected by position bias, non-transitive evaluations persist. Unbiased pairwise comparisons can still form cycles, potentially leading to ranking reordering.

1
0
7
🔍 Why does this happen? One major factor: position bias. LLMs are influenced by the order in which responses are presented. With weak judges (e.g., GPT-3.5-Turbo), 80% of preference shows position bias! 😧 Even GPT-4-Turbo is affected. With stronger position bias, judges are

1
1
8