
Aaron Dharna
@_aadharna
Followers
356
Following
2K
Media
21
Statuses
208
PhD student @UBC_CS. Interested in reinforcement learning, generative models, open-endedness, and the intersection of games and machine learning.
Joined June 2017
The first big part of my PhD research is out! Infinite thanks to @jeffclune and @cong_ml for all their guidance on this project.

Thrilled to introduce Foundation Model Self-Play, led by @_aadharna. FMSPs combine the intelligence & code generation of foundation models with the curriculum of self-play & principles of open-endedness to explore diverse strategies in multi-agent games, like the one below 🧵👇
5
12
60
I'll be presenting FMSPs @RL_Conference in room 140 today!.
Thrilled to introduce Foundation Model Self-Play, led by @_aadharna. FMSPs combine the intelligence & code generation of foundation models with the curriculum of self-play & principles of open-endedness to explore diverse strategies in multi-agent games, like the one below 🧵👇
1
4
28
I'm really excited to be presenting FMSPs at @RL_Conference later this year!.
Thrilled to introduce Foundation Model Self-Play, led by @_aadharna. FMSPs combine the intelligence & code generation of foundation models with the curriculum of self-play & principles of open-endedness to explore diverse strategies in multi-agent games, like the one below 🧵👇
0
2
25
@jeffclune @cong_ml @robray1 At Neurips we talked about this project so I just wanted to let you know it's officially out!.
0
0
4
@jzl86 This is the project we talked about at Neurips, and your autocurricula paper was one of my big inspirations!

arxiv.org
Multi-agent interactions have long fueled innovation, from natural predator-prey dynamics to the space race. Self-play (SP) algorithms try to harness these dynamics by pitting agents against...
0
0
5
RT @cong_ml: Really excited to share our recent work combining open-ended foundation model innovation with the compeititive dynamics of sel….
0
10
0
RT @jennyzhangzt: Our work OMNI-EPIC (w/ @maxencefaldor, @CULLYAntoine, and @Jeffclune) will have an ✨oral presentation✨ at #NeurIPS2024 wo….
0
7
0
Our in-progress work Quality-Diversity Self-Play (w/ @cong_ml and @Jeffclune) will have a poster presentation at #NeurIPS2024 workshops (@IMOLNeurIPS2024 Sunday West meeting room 217 - 219 and OpenworldAgents Sunday East Meeting Room 1-3, Foyer). Please come visit us!

4
6
25
RT @SakanaAILabs: Introducing The AI Scientist: The world’s first AI system for automating scientific research and open-ended discovery!. h….
0
2K
0
It's been so much fun to read these as they come in -- please send more!
We have a lot of great submissions for this project that we are excited to share with you when ready. Last call if anyone else wants to submit. Please share with anyone you think has a story, or just let us know about it and we'll track it down. Thanks!.
0
1
3
This is a great example of some of the types of stories we're looking for in our AI Finds A Way call:

Fun story from our internal testing on Claude 3 Opus. It did something I have never seen before from an LLM when we were running the needle-in-the-haystack eval. For background, this tests a model’s recall ability by inserting a target sentence (the "needle") into a corpus of
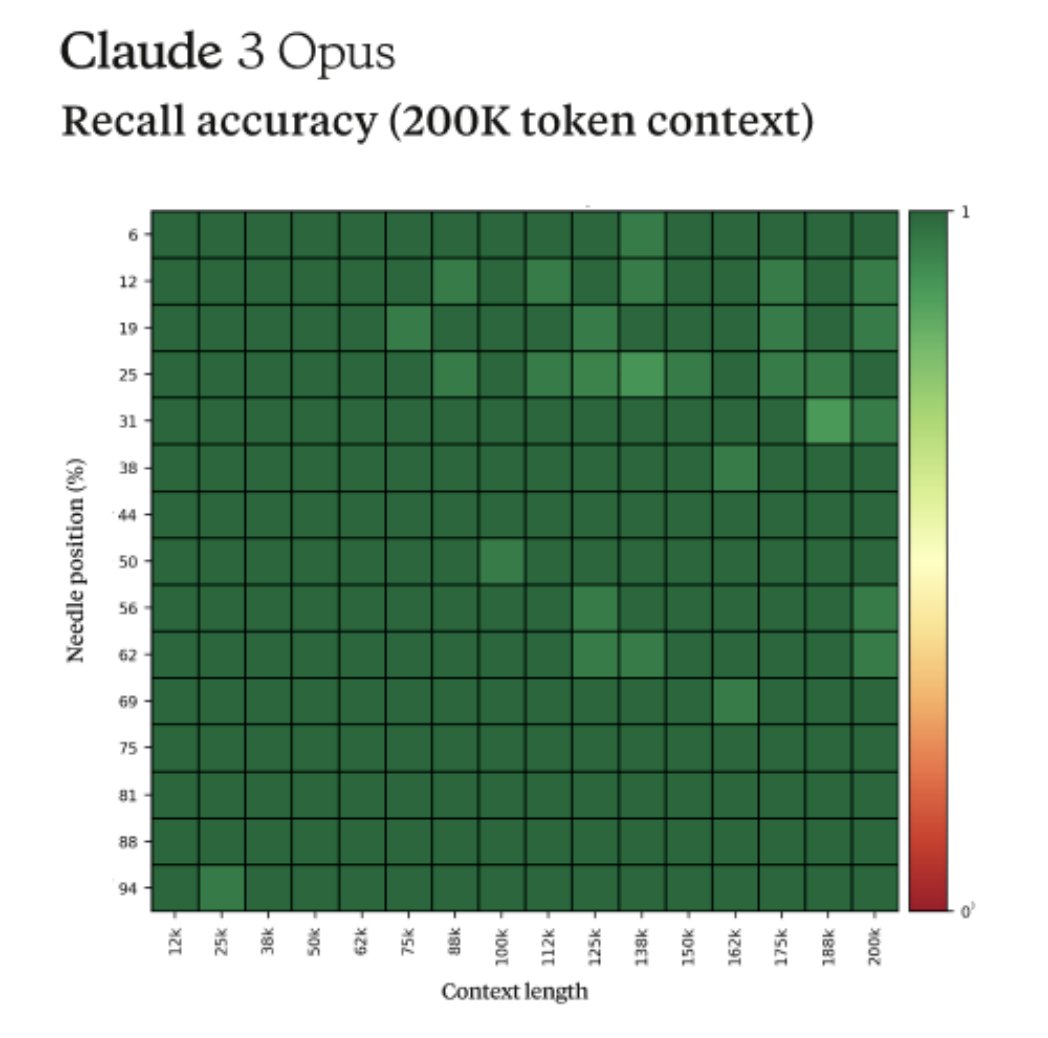
0
0
1
RT @jeffclune: What are your favorite examples of AI outsmarting us, being creative, surprising us, escaping the confines we try to place i….
0
1
0
@togelius @FilipoGiovanni @Amidos2006 jokingly called this a superstition as the model thought it needed to stand in a particular square to receive a reward when the square wasn’t important. (4/4).

arxiv.org
Deep reinforcement learning has learned to play many games well, but failed on others. To better characterize the modes and reasons of failure of deep reinforcement learners, we test the widely...
0
0
2
The agent ended up learning to pull the lever and then run to the other side of the board to receive the reward because the time to cross the board happened to match up with the delay in receiving the reward. (3/4).
1
0
0
The point of the paper was to investigate how RL handled environments with deceptive rewards. In one of the scenarios, the agent had to learn to pull a lever and they’d get a reward after a delay. (2/4).
1
0
0
A great example of agents learning the wrong goals from rewards was a recent submission -- “Superstition in the Network.” The paper was named after a “superstition” the model learned. (1/4).
Our soft deadline (March 1st) to gauge initial community interest is coming quick. We've gotten some cool submissions and I can't wait to see what else is out there. I know some people are still writing up anecdotes, so fret not, this isn't a hard cutoff
1
0
1
Our soft deadline (March 1st) to gauge initial community interest is coming quick. We've gotten some cool submissions and I can't wait to see what else is out there. I know some people are still writing up anecdotes, so fret not, this isn't a hard cutoff
We design experiments/safeguards, only to learn AI often finds a way to cheat or escape. Like Midas' Touch, we get what we asked for, not what we want. It is important to share such stories (once verified). Please submit any stories you know of. Details:

0
2
7
Instead of learning to race, the RL agent maximized its score by farming powerups in the game because the win/lose reward function was augmented with a bonus point for every powerup picked up. (2/2).
1
0
1
A modern classic of RL finding surprising solutions that maximize what we asked for instead of what we really wanted is the speedboat example by @jackclarkSF and Dario Amodei. This is a great example of a reward hacking story we are looking for. (1/2).
To kickstart the conversation, here are a few of my favorite stories already in the public discourse -- please feel free to add yours to the list!.
1
0
1