

Mandi Zhao
@ZhaoMandi
Followers
5K
Following
2K
Media
31
Statuses
157
PhDing @Stanford, AI & robotics. Interning @MetaAI. Prev. @NVIDIAAI, @berkeley_ai
Joined May 2017
How to learn dexterous manipulation for any robot hand from a single human demonstration?. Check out DexMachina, our new RL algorithm that learns long-horizon, bimanual dexterous policies for a variety of dexterous hands, articulated objects, and complex motions.
19
105
618
The task environment in the video is built in Genesis, with state-based policy input (object pose, robot joint states). The full reward is a weighted sum of keypoint distance reward and another term that rewards higher object height (hence the lifting up motion), plus an action.
0
0
8
Another detail here is how to compute distance-based reward in batched setting: a common equation you will see in papers is ‘rew = exp(-beta * dist)’, but when you have multiple keypoints, i.e. dist has shape (B, N) where B is number of environments and N is number of keypoints,.
4
1
21
One amusing takeaway from doing RL in these massively parallelized sim environments is that reward engineering matters more so than ever. A small detail in reward function could make a huge difference: with 10k+ parallel threads to explore in, the policy Will exploit any caveat
5
24
390
I’m a big fan of this line of work from Columbia (also check out PhysTwin by @jiang_hanxiao: they really make real2sim work for the very challenging deformable objects, And show it’s useful for real robot manipulation. So far it seems a bit limited to.

Can we learn a 3D world model that predicts object dynamics directly from videos? . Introducing Particle-Grid Neural Dynamics: a learning-based simulator for deformable objects that trains from real-world videos. Website: ArXiv:
2
9
57
RT @du_maximilian: Normally, changing robot policy behavior means changing its weights or relying on a goal-conditioned policy. What if the….
0
34
0
just realized twitter cropped the images :( here's the full list:


0
2
9
The recipes are twists from classic drinks like Palomas and Martinis. The names are inspired by the drink tastes: 'reviewer#2' is spicy with jalapeños, 'in-between-projects' because it's chill and relaxing. shout out to my co-host @du_maximilian!

1
0
21
Our lab at Stanford usually do research in AI & robotics, but very occasionally we indulge in being functional alcoholics -- Recently we hosted a lab cocktail night, and created drinks with research-related puns like 'reviewer#2' and 'make 6 figures', sharing the full recipes


9
11
272
I'm giving a spotlight talk 10AM tomorrow, Room 213 at the agents-in-interactions workshop at #CVPR. Poster session is 11:45-12:15 at ExHall D #182-#201. Come say hi! . Workshop schedule:
How to learn dexterous manipulation for any robot hand from a single human demonstration?. Check out DexMachina, our new RL algorithm that learns long-horizon, bimanual dexterous policies for a variety of dexterous hands, articulated objects, and complex motions.
2
7
72
RT @priyasun_: How can we move beyond static-arm lab setups and learn robot policies in our messy homes?.We introduce HoMeR, an imitation l….
0
53
0
Single view reconstruction for cluttered scenes!.

Imagine if robots could fill in the blanks in cluttered scenes. ✨ Enter RaySt3R: a single masked RGB-D image in, complete 3D out. It infers depth, object masks, and confidence for novel views, and merges the predictions into a single point cloud.
0
0
7
thank you @Michael_J_Black ! The name DexMachina came from Deus ex machina (“god from the machine"): when a seemingly unsolvable problem is conveniently solved by an external force - like how our algorithm moves an object by itself before the policy gradually learns to take over.

@ZhaoMandi This wins for "best method name"! These are nice results and I'm happy that ARCTIC was useful. I believe that human demonstration is the path to rapid progress in dexterous, task-driven, manipulation.
1
0
21
RT @GuanyaShi: Great work - Robot/object/contact co-tracking and curriculum via virtual object controllers are really good ideas. We will s….
0
7
0
With the recent surge in new dexterous hand hardwares, we hope this work provides a useful platform for identifying desirable hardware capabilities and lower the contribution barrier for future research. Project website: arXiv:

arxiv.org
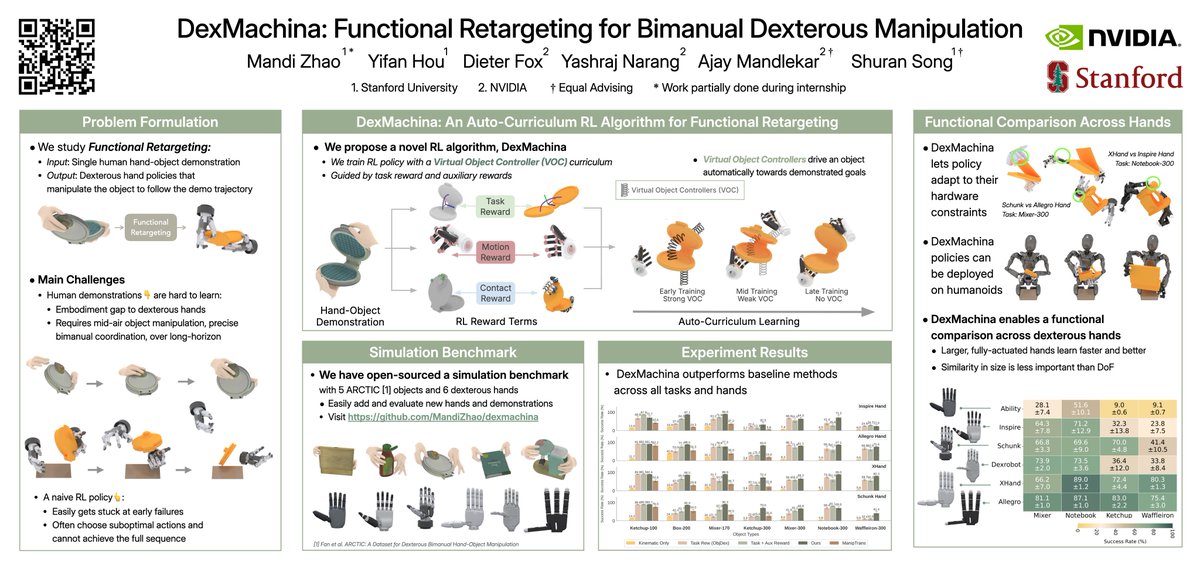
We study the problem of functional retargeting: learning dexterous manipulation policies to track object states from human hand-object demonstrations. We focus on long-horizon, bimanual tasks with...
1
3
29
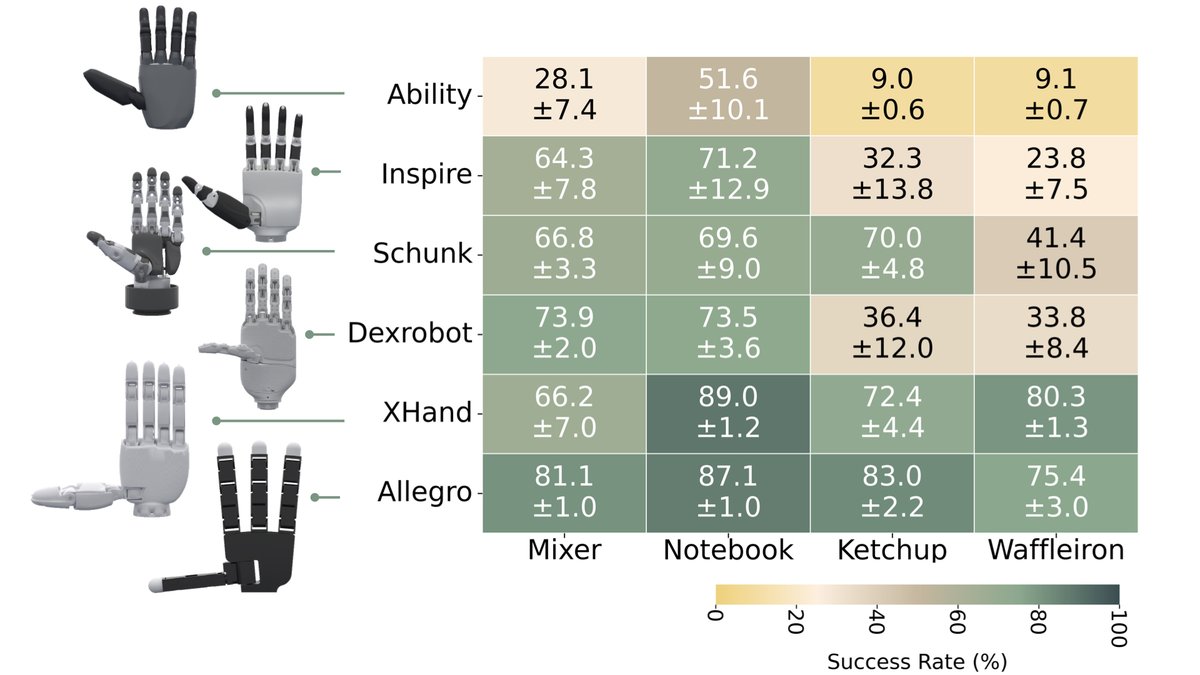
DexMachina lets us perform a functional comparison between different dexterous hands: we evaluate 6 hands on 4 challenging long-horizon tasks, and found that larger, fully actuated hands learn better and faster, and high DoF is more important than having human-like hand sizes –
1
3
22
For evaluation, we built a simulation benchmark with 5 articulated objects and 7 demo clips from ARCTIC, and curated 6 open-source dexterous robot hand models, with varying sizes and kinematic designs. We show DexMachina significantly outperforms baseline methods, by 21% on
1
1
9
Our key idea is a novel curriculum using "virtual object controllers": using the demonstration trajectory, they can drive the object to follow the targets on its own, such that the RL policy can learn through the entire demo sequence without worrying about dropping the object.
1
1
14
Our method, DexMachina, is a curriculum-based RL algorithm guided by a task reward and auxiliary rewards. Each human demo defines an RL task: we use the object states and human hand data to define the reward terms and residual wrist actions.
1
5
19
We study the problem of "functional retargeting": with one human demonstration, learn a dexterous hand policy to manipulate the object to follow the demonstrated trajectory. In contrast to kinematic retargeting which does not produce feasible actions, we use human hand guidance
1
1
44