

Tim Pearce
@Tea_Pearce
Followers
2K
Following
2K
Media
60
Statuses
250
Reseaching AI at @Microsoft Research. Previously found at @Tsinghua_Uni, @Cambridge_Uni.
Joined December 2012
1/ Remember when LLMs were huge but undertrained? OpenAI's original scaling-laws told us parameters scale N ∝ C^0.73. Two years later Chinchilla corrected this with N ∝ C^0.50. Mysteriously, no full explanation was given. until now!😊.@jinyeop_song

9
24
235
Neural scaling Laws: Fundamentals and Frontiers. A talk summarizing some things I've learned about (+ contributed to) scaling law research over the past ~1 year.

3
50
344
Imagine waking up to find the CEO of your company chatting about your research with your favorite podcaster—as it's being featured on Nature’s homepage. Not a bad start to the day. 🤩.

1
1
36
5/ Work with amazing co-authors from the @MSFTResearch Game Intelligence team: Tabish Rashid*, Dave Bignell, @ralgeorgescu @smdvln @katjahofmann .
0
0
4
4/ But we care about online performance, not pre-training loss. Forget small-scale intuitions! In the infinite data regime, pre-training loss seems to be a strong predictor of performance.

1
0
3
3/ Tokenization matters. The tokenization scheme of image observations affects the coefficient of the optimal model size.

1
0
2
2/ As a consequence, for a given compute budget, models can be optimally sized and their loss reliably predicted.

1
1
3
1/ Does scaling pre-training 📈 improve embodied AI 🤖as effectively and predictably as it is does LLMs? Yes! 👍 Our paper studies behavior cloning & world modeling tasks in the infinite data regime ♾️on human data🎮

1
23
122
sota video tokenizer now opensource 🥳.

🚀Excited to introduce VidTok, a cutting-edge family of video tokenizers that excels in both continuous and discrete tokenizations. VidTok offers:.⚡️ Efficient Architecture: Separate spatial and temporal sampling reduces computational complexity without sacrificing quality. 🔥
0
0
5
RT @EloiAlonso1: Try 💎 DIAMOND’s Counter Strike world model directly in your browser!. → ←. How long can you stay i….
0
12
0
4/ also my first experience with @TmlrOrg. fast high-quality reviews focused on improving the paper. 5⭐would recommend!.
0
0
0

2/ .Recommend 1 -- when measuring model size. ✅count total parameters.❌don't use only non-embedding parameters.Recommend 2 -- when predicting loss from compute, use an offset in the fitting equation. ✅L = const. aC^b .❌L = aC^b.
1
0
0
1/ our analysis reconciling the conflicting LLM scaling laws of Kaplan (N ∝ C^0.73) and Chinchilla (N ∝ C^0.50) accepted to TMLR 🥳 .we explain this long-standing discrepency, with two concrete recommendations for anyone running scaling law analyses.
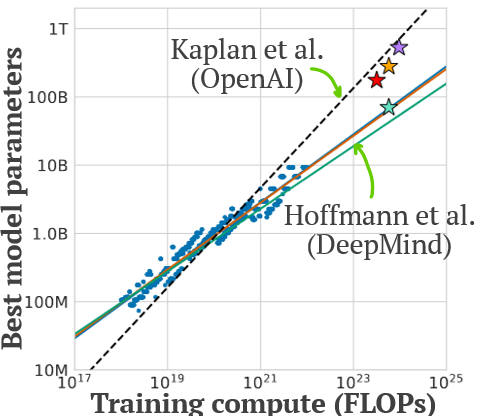

1
1
7
2/ .Recommend 1 -- when measuring model size. ✅count total parameters.❌don't use only non-embedding parameters.Recommend 2 -- when predicting loss from compute, use an offset in the fitting equation. ✅L = const. aC^b .❌L = aC^b.
0
0
0
DIAMOND world model now in MarioKart! 💖 awesome to see the community already trying new things with the code base (. Dere did a nice writeup of his experiences here: . tagging @EloiAlonso1 @AdamJelley2
0
7
29
very cool to see the latent action space of world models can transfer between human arms <-> robot arms!💫.

We introduce Image-GOal Representations (IGOR), a framework that learns latent actions from Internet-scale videos that enable cross-embodiment and cross-task generalization. IGOR can migrate the movements from human to robots only through the extracted latent actions, opening new
0
0
2
Awesome to see so many people getting excited about the CSGO dataset coming to life 💖 ( 3 yrs ago making a decent BC agent was a battle. Now we're modeling the whole engine! So proud of @EloiAlonso1 & @AdamJelley2 for their open-source efforts 💫.

Ever wanted to play Counter-Strike in a neural network?. These videos show people playing (with keyboard & mouse) in 💎 DIAMOND's diffusion world model, trained to simulate the game Counter-Strike: Global Offensive. 💻 Download and play it yourself → 🧵
4
7
47
RT @smdvln: Our team @MSFTResearch is hiring for a 2-year AI Residency role in the area of learning to control embodied agents, with the go….
0
35
0
All lead authors are ML stars of the future (if not already!)⭐-- go follow them!. More details to follow. .
0
0
5
Super proud to be part of two accepted NeurIPS papers 🥳.1) Stabilizing GAIL with Control Theory - led by @tianjiao_luo .2) Diffusion for World Modeling (spotlight 💫) - led by @EloiAlonso1 @AdamJelley2.
2
2
21