

中 翔吾
@StackPilesKK
Followers
23
Following
1K
Media
11
Statuses
1K
株式会社StackPiles 代表取締役社長、生成AIプロダクト開発、OCR開発、Web開発、スマホアプリ開発、業務ウェア開発など幅広いソフトウェア開発を行っております。 お問い合わせは 🔝: https://t.co/ovtIqN4G9d
Shinjuku,Tokyo,Japan
Joined May 2023


RT @OfficialLoganK: Today we are making URL Context, my favorite Gemini API tool, ready for scaled production use 🔗. The model can now visi….
0
329
0

RT @sesame: Maya and Miles are learning new languages!. This week, we deployed a new voice model to our web demo with improved support for….
0
183
0
RT @UnslothAI: Qwen3-30B-A3B-Instruct-2507 is here!✨. The 30B model rivals GPT-4o's performance and runs locally in full precision with jus….
0
93
0
RT @googleaidevs: Get started with Gemini Embedding using @weaviate_io, which supports over 100+ languages and flexible dimensions for perf….
0
41
0
RT @kwindla: You don't need a WebRTC server for voice agents. If you're deploying your own voice AI infrastructure, you should almost cer….
0
20
0
RT @jandotai: Audio search without transcription: ColQwen-Omni embeds 30 minutes of audio in 10 seconds across documents, audio, and video….

huggingface.co
0
35
0
RT @AdinaYakup: Qwen3-235B-A22B-2507 is here 🔥. Qwen team is sunsetting hybrid thinking mode. From now on, they wi….

huggingface.co
0
26
0
RT @ai_database: LLMが生成するコードをより高速・安全・高精度に実行するための新しいプログラミング言語「QUASAR」が提案されています。. 実験では、実行時間が(並列化可能なタスクで)最大42 %短縮し、全体平均でも16 %短縮しています。ユーザー承認回数は….
0
30
0
RT @Wauplin: Big update: Hugging Face Inference Providers now work out of the box with the OpenAI client!. Just add the provider name to th….
0
7
0
RT @kwindla: Smart Turn v2: open source, native audio turn detection in 14 languages. New checkpoint of the open source, open data, open t….
0
75
0
RT @kazunori_279: 音声AIエージェントの現状と展望. 1. 現状認識:デモと実用化の乖離.OpenAIやGoogleが提供する高度な音声AI機能は、まだ「デモ」の段階にあり、製品としての安定性やユーザー体験は発展途上です。Kwindla….
0
2
0
RT @erogol: XTTS is still being downloaded almost 5m times every month and 2.1m only on HF. It is greater than many recent hyped models.….
0
10
0
RT @deedydas: Google DeepMind just dropped this new LLM model architecture called Mixture-of-Recursions. It gets 2x inference speed, reduc….
0
449
0
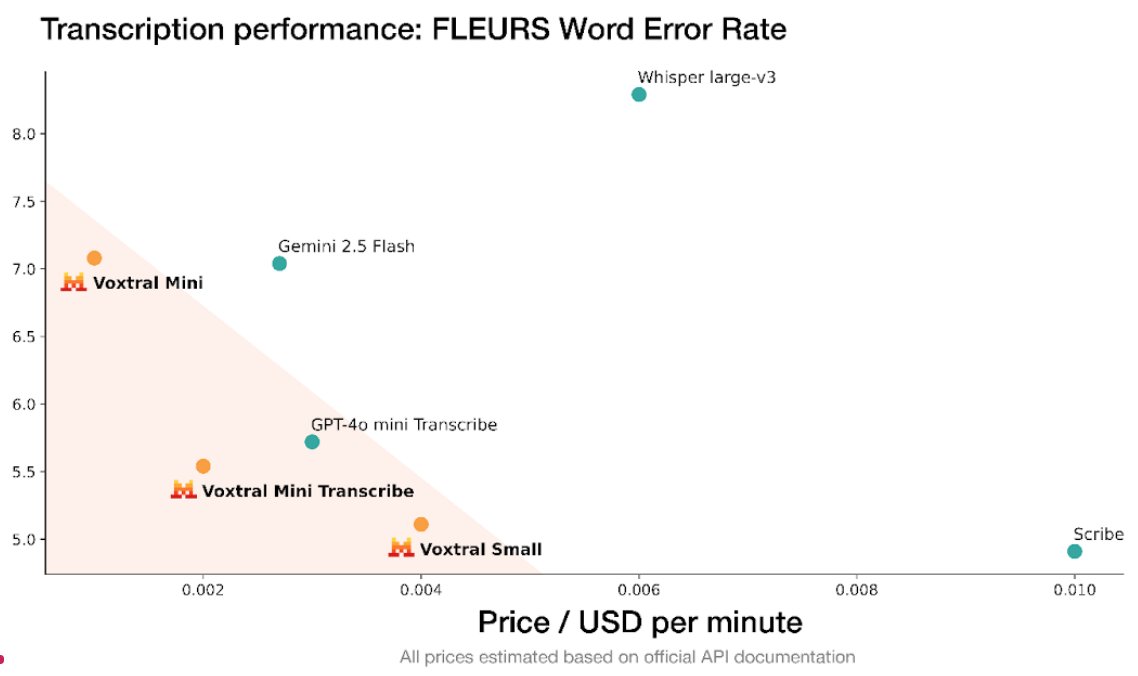
RT @kyutai_labs: If you're at #ICML2025 this week, come check out these 3 posters from our lab🟢!.- Aligning Spoken Dialog Models from User….
0
3
0
RT @UnslothAI: You can now run Kimi K2 locally with our Dynamic 1.8-bit GGUFs!. We shrank the full 1.1TB model to just 245GB (-80% size red….
0
265
0
RT @reach_vb: BOOM! We just shipped our open source robot Reachy Mini 🔥. Smol size at fraction of the cost - for AI builders across borders….
0
48
0