

はまなすなぎさ
@RosaRugosaBeach
Followers
2,033
Following
3,721
Media
407
Statuses
12,285
全ての呟きは私個人のささやかな気づきや興味に基づくものです。
Tokyo
Joined September 2016
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#KAZZAWARDS2024
• 355580 Tweets
SAROCHA REBECCA IN KAZZ
• 292738 Tweets
スタンプ
• 151968 Tweets
NORAWIT WITH PAUL SMITH
• 68834 Tweets
Varane
• 30958 Tweets
インプレゾンビ
• 28041 Tweets
B1NI TOPS SPOTIFY
• 22061 Tweets
#うたコン
• 13154 Tweets
モグコレ
• 12443 Tweets
#MAZZEL
• 12390 Tweets
名誉毀損
• 11507 Tweets
風の行方
• 10330 Tweets




















Pinned Tweet

昨年から爆発的な流行を見せているAI画像生成について、網羅的かつ多角的なメタサーベイを執筆しました。
核となる拡散モデルの基礎、一般層への浸透、浮き彫りとなった問題点、および加速度的に発展する手法群をまとめています。
多分どこより情報量多いです。皆読んでね。

10
944
3K
日本では超有名なミームになってる『ヒンメルはもういないじゃない』、英語吹き替えだと "Because Himmel is rotten in the ground." っていうえっぐい訳になっており、フリーレンを静かに激昂させるに至ったのがよりわかりやすい直裁的な表現になってると同時に非常にいい意訳であると思った
131
6K
30K
西洋的価値観のファンタジーの中で、日本のように火葬せず土葬してる描写があったのも踏まえて「人々から敬われ世界を救った高潔なヒンメルも今や土の中で腐ってるわよ」っていう人間にとってはこれ以上ない侮辱をアウラが澄ました顔で言ってるのがガチでポイント高い、ここで描写すべき事をわかってる
2
1K
6K
勉強したい、時間が欲しい、みたいなことを口では言いながら実際に時間があってもほとんど何もしない自分を観測するたびに魂が擦り減って、人はだんだん自分を諦めてさらに何もしなくなっていくんだろうな そういう時に何かに励む他者は刺激になる、それ以外に自身で起爆剤を作る難易度は結構高い
2
871
4K
これ耳を澄ませたらis rottenよりis rottingと言ってる気もしてきて、魔族やエルフのような長命種にとってヒンメル没後のたかだか30年程度は一瞬のように感じられる(=腐敗が進行中)みたいな解釈もでき、面白いなと思うと同時に、まあいずれにしても侮辱度高くて最高だなと感じた
2
335
3K
侮辱なんだけど、アウラはそれを侮辱だと思って言ってなさそうなところが、このシーンを人類と魔族を分つ精神性の違いを描く上でこの上なく細やかで重要なものにしているんですよね
2
301
2K
SD系手法を用いたアニメ風動画への変換、かつての黎明期の取り組みもすごく感動した記憶がありますが、一貫性が一気に上がってて久しぶりにかなりの衝撃を受けました
ControlNetは納得としてVideo Loop Backてなんだろうと思ったらまた何か出てたっぽい


2
397
1K
AI界隈、「とりあえず手を動かして試す」が他の専門分野と比べて遥かに簡単かつ確かに重要ではあるので、背景知識や理論、アルゴリズムのいろはも理解してない人がその手数によって実際にそれなりに有益な情報を生み出し、幅を利かせ、その実少し踏み込んだ発言をすると間違う、ということがよく起きる
1
168
1K
これはおっしゃる通りだと思っていて、だからこそ日本語でいう「もういない」と同じくらいの気軽さで「土中で腐っている」と言い放ててしまう、という面も含めて上手い意訳だなと個人的に感じた部分でした

いうて向こうじゃ土中で腐るのは常識なんじゃないか?
日本だとだいぶ忌避感の強く感じるが土葬が基本のキリスト教国じゃ「そらそうよ」ってなるのでは
1
9
87
0
200
1K
誰がどう見ても長続きしないビジネスモデルすぎて、先行者利益だけ掻っ攫って未整備の土壌を荒らすだけ荒らして消えてく焼畑タイプで心底迷惑だし、そもそもちゃんとしたプレスリリースの場で他人のツイート黒塗りして使うとかいう広報意識の欠片もないことしてるのありえない

3
535
927
Transformerを超えるんじゃないかと言われてる新たな系列モデル(と理解してる)S4とその更なる発展であるH3、数理背景が難すぎて理解を放置してたのでちゃんと勉強したい
理解できてないけどS4はこの資料が超詳しかった記憶
積読してるH3の解説

1
128
811
いずれ出てくると思ったけど、Any2Anyの拡散モデルが提案されたみたい。言語、画像、動画、音声の任意の組み合わせ(訓練データになかったものでさえ)から、任意の組み合わせを出力できる。単一モダリティのSOTAとすら並んだり凌駕する(画像はImagenとかと比べてないけど)

1
184
761
寄せられた色々な意見を眺めていると、「腐っている」は攻撃的すぎて元々の無邪気さのある発言にはそぐわない気がするという意見も多く、それも共感できるなあと思う一方で、個人的には「魔族にとって魔族以外の生物が死後腐敗するのは自然現象の一部(=当たり前で感情を伴う事象ではない)であり、
1
74
653
それが人間の神経を逆撫でる機微を含む言葉であるとは理解していない」ことを反映した表現なのかなーと思ったりもしました
そうであるならば、もういないをただの事実として述べたアウラとそこに憤りを覚えたフリーレンの対比描写の訳出としては意外とそぐうものではあるんじゃないかなーとも感じたり
1
61
615
純粋な機械学習系の記事でここまでわくわくさせられたのは久しぶりな気がする
実際今後自分がこれを応用できるか、実践的に効果を得られるかを置いておいて、とりあえず理解しておきたい欲に駆られる
1
81
607
サイバーが日本語モデル出してきた矢先にrinnaも公開してくるのアツい
3.6Bなので7Bにはパラメータ数は及ばないが、対話用に調整したモデルも公開された模様(サイバーの7Bモデルが補完でさえ結構厳しい感じだったのに比べてこちらはどれほどのものなのか期待感がある)

1
169
545
エグすぎてなんとも言えない感情になった
動画の一貫性がどうとか、fpsがどうとか、長尺がどうとか、動きの滑らかさがどうとか、これまでの界隈の議論を全部吹っ飛ばす勢いで完全に『もうOpenAI(あの人)一人で良くないですか?』状態だ

1
71
413
Transformerの後継となるべく新たに提案されたRetentive Network、面白い
並列処理と再帰構造をうまく組み合わせた仕組みで、メモリ消費や推論効率が改善しているほか、2B以上の規模になると精度も上回り始める(昨今のLLMとしてのベンチマークがどうなるかは気になるが)

3
64
387
なんかほぼ私の記事を無断転載したQiita記事を見つけてしまったんだが……(ちょろっと2月以降の差分を載せたりして転載じゃないと言いたいのかもしれないが、普通に記述や図が丸パクリなので心象は良くない)(しかも私の記事への言及はない)(図の引用も明記されてない)
3
30
331
適切に選択したたった1000件の学習データでLLaMa 65BをFTすると、RLHFとか使わずともAlpaca 65B〜GPT4までと比較して競合できるくらいの性能に到達するという研究
興味深い
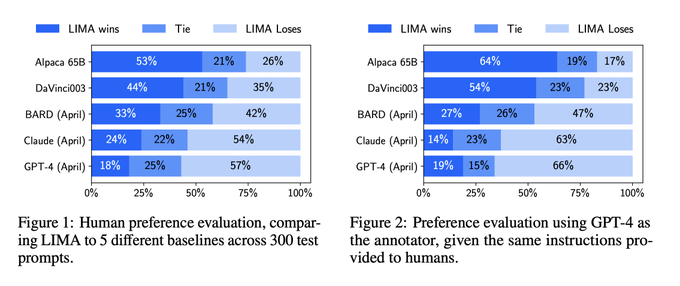
3
55
327
恵vs甚爾の英語吹き替え、最期の「良かったな」が「That makes me glad.」になっててそう訳したかぁ、という感じ。元の台詞は、五条が彼の遺言を汲んで恵を禪院家から遠ざけて守ってくれたであろうことを察し、恵にとって良かったと語りかけてると解釈できるが、英語版は主体が甚爾の感情になっている
3
52
309
Transformerの後継を謳ってたRetNetがViTに適用されてちゃんと結果が出ましたよ論文
PixelCNN系みたいに画像を左上から読み取る形式かと思ったらRetNetをちゃんと平面+双方向に拡張していて偉い(自己回帰で過去しか見れないのは画像認識とかには適してないと言ってる)
1
46
310
津波や地震に際する緊急避難報道が今回どの局もかなり強烈だったことに対して腐してる(恐らく被災地にいない)人の意見を見て、安全地帯のお茶の間で突然あれらを見たら茶番とかやりすぎとか感じる気持ちも理解はできたが、現場にいた者の感じ方はかなり違っていて、私は素直にありがとうと思っている
1
41
253
DeepFloyd IFが学習画像まんまの生成結果を簡単に出せることがわかってきて、拡散モデルのヤバさ認識フェーズが一段上がった気がする今日この頃
(SDでもたまに出ちゃうことが示された研究はあったが、それ以上に多分遥かに出しやすい、特に固有名詞の組み合わせ系は)
1
125
249
ちなみにLLMに興味あるけど詳しいこと何もわからんよって人はこちらをご覧になるといいです すでに知っている方にとってはこれまでのおさらいという感じ

0
33
249

ものすごく強気かつミステリアスに主張すれば "なにやら凄そう" というだけで人が群がってくるのマジで本邦のAI界隈とその重厚な取り巻きの良くないところだと思っており、ここ数日でそういうのを何度か目撃しているので完全に食傷している
1
35
219
1000件の良質なデータでFTすればいいよ!っていうLIMAが出たと思ったら、良質な指示対話形式のデータ(1.5M)でスケールさせたら強くなったぜ!っていうUltraLLaMaが出てきた LIMAは65Bだったけどこっちは13Bみたい
1
35
202
光栄なことに、この度の資料をITmediaさんにご紹介いただきました。執筆を頑張った自分をちょとだけ褒めてあげると共に、これもひとえにご覧いただいた皆様の反応あってこそのことだと感じています。改めて心よりの謝意を。
修正点については対応中ですので、今しばらくお待ちいただけましたら。


0
27
193
チラシ裏のつもりだったので超驚いていますが、たまーに類型の呟きをします。最近だとこれとか。
今回の引用でも「私には解釈違いだ」って方もいて、その気持ちもよくわかるというか、私も普段別に全肯定感想botをやってるわけではないので色々な意見が見られて楽しいです
恵vs甚爾の英語吹き替え、最期の「良かったな」が「That makes me glad.」になっててそう訳したかぁ、という感じ。元の台詞は、五条が彼の遺言を汲んで恵を禪院家から遠ざけて守ってくれたであろうことを察し、恵にとって良かったと語りかけてると解釈できるが、英語版は主体が甚爾の感情になっている
3
52
309
0
18
198
拡散モデルが訓練データを単に複製してしまう既知の問題を緩和するための手法っぽい
実応用上この観点は特に大事なんじゃなかろうか

1
34
194
軽い気持ちで読み始めたけど知見が多くて面白い

1
17
168
NNsは勾配降下の非明示的な正則化効果で一般化すると思われているが、実は勾配不使用型optimizerでSGDと同程度の汎化性能が得られたのでそんなことないんじゃね?という研究。「平坦な局所極小値」に辿り着くことが大事だとしてパラメータ空間を一様分布から繰り返しサンプリングするだけの手法を提案


It is widely thought that neural networks generalize because of implicit regularization of gradient descent. Today at
#ICLR2023
we show new evidence to the contrary. We train with gradient-free optimizers and observe generalization competitive with SGD.
15
119
683
1
25
166

例えば実験系の多くの科学分野は実験器具を扱うために「理解していないといけないことのハードルが高い」が、AI系はPCに少々明るければ「押せば動く」ので、他分野のように言説の質を担保する作用が働きづらいのだと思う 故に多様性が多く均衡が下で落ち着いて、バズりを誘発させやすいから群がる
1
30
163
StableDiffusionを使えるお馴染みの公式webアプリであるDreamStudioがOSS "StableStudio" として提供されたみたいだ
こっちのいわゆるモダンなUIで拡張機能開発の機運が高まったらすごく面白いけどどうなるかな

1
31
160

1B(10億)トークン処理可能とかいうぶっ飛んだTransformer派生が出てきたけど、セグメント分割して指数関数的に飛び飛びな領域を注意させるdilated attentionを考案したらしい(WaveNetのdialated convの使い方を彷彿とさせる)
短い系列でも長い系列でもちゃんと精度出てる
0
45
154
なんかSchrodinger Bridgesとかいう新しい生成モデルのスキームが生えてる気がするなあと思ったら、ありがたい解説記事が
Part IIが出る予定らしいがまだ見当たらない

0
28
155
生きてて楽しいという気持ちが薄れてる時の大体の原因は文化資本の薄さだなーと感じる 趣味、遊び、熱中できること、好きな食事処や飲み屋、家で時間を潰す時の選択肢……等々への圧倒的な知識不足や造詣の浅さ、知りにいくEnergyのなさ、生物としての格の低さが自分で自分をつまらない環境に置いてる
1
11
153
LLaMA2、ネット上のデモだとあんま日本語強くない印象だけど、ローカルでggml 4bit版の13B chat動かした感じ想像以上にまともに会話できるな、という印象
2
19
140
今のLLMって大量のテキストの煮凝りを食わせることでよしなに知識が手に入ることを期待してやってて、実際それが上手くいってるけど、そういう不確かなやり方じゃなくて知識グラフとかを別軸で保持しつつそれを読み取って適切に言語化できる仕組みにした方が筋がいい気がするな、とかふと思った
1
10
136
RetNetってせっかくsoftmaxを廃してQKVの積を線形に計算できるようになったんだから、積の順序をKVからにするっていう古典的なアイデアでもっと計算量減る気がするけどどうなんだろう(decay_maskも含め効率的に分解できるかという話はあるが)
これは疑似コードだから実際はそうしてるのかもだけど

1
6
131
Transformerのenc-dec間にinformation bottleneckを入れてVAE的に表現の正則化をしよう的なノリの研究、面白そうなので読む

1
24
132
ZENKIGENのテックブログがZenn Publicationに対応したため、私の公開記事を個人アカウントに紐付け直しました。これからも多分ぼちぼち更新していきます。
某Transformer記事も公開から早8ヶ月経過しましたが、畏れ多くも多くの皆様にご覧いただけていることに謝意を。

1
17
127
絵柄そのものに著作権は認められないのでは?とか学習は合法で…とかそんな話をしたいのではなく、なんというかこのマネタイズ仕草のさもしさみたいなものが、クリエイターの方々の悪感情を煽るだけでなく、AI利用領域に対する(ただでさえ悪い)印象をますます悪化させていく点を危惧してるんですよね
1
34
115
CVPR2023にDreamBoothが採択されてたのを知って、学会ですらもう遅すぎるのか…という気持ちになった
DreamBoothとかもう古典だろ(過激)
1
17
119
RetNetのchunkwise retentionのこの式、絶対オリジナルのretentionの厳密な分解になってないだろと思ってトイコード書いたらやっぱり値が一致しなかったので色々暗算してたら厳密にchunkwiseに分解できる式に辿り着いて、実装上分解する場合としない場合が厳密一致することも確認した

2
6
104
今までのVAE潜在空間経由したtext2videoのチラつきはなんだったんだってぐらい安定していてすごい ピクセルベースで学習するImagenVideoとかに近い滑らかさを感じる

Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
turn the publicly available, state-of-the-art text-to-image LDM Stable Diffusion into an efficient and expressive text-to-video model with resolution up to 1280 x 2048
abs: …
26
354
1K
1
26
102
マジじゃん
rinnaさんまでGPT由来のデータ使ったモデルをMITライセンスで公開するなら、実質「競合モデルに出力使用禁止」規約で律儀にデータやモデル非商用にするのアホらしいってことになるのでは 流石にわかっててやってるだろうから少なくともここの見解はokてことなのか

1
22
101
なんかめちゃくちゃ有益なTransformerサーベイがあったので共有しますね(ダイマ)
ブログのくせに143件も論文引用してる異常な記事ですが、ご興味のあるところを適当に拾ってご覧いただければ嬉しいです

躍進を続けるTransformer関連手法について、AI技術開発部の清水(ZENKIGENで業務委託)がメタサーベイ記事を執筆しました。手法群を多角的に俯瞰し、昨年から話題となっている言語モデルの創発性についても簡潔に触れています。
辞書的な記事として是非お立ち寄りください。
0
84
365
2
16
93
論文が出た当初も「いつかちゃんと読みたいなぁ…」と思いつつ目を逸らし続け、実装が公開されてからも「今度読むか…」と放置していた彼の Consistency Models (難しく、つらい)をかなり綺麗かつコンパクトにまとめてくれた良記事で、五体投地して読んでいます
1
8
91
LINEが複数端末からログインできないの令和の時代にあるまじき悪行だと思ってるけどLINEだから許されてる感
LINEに統合されたYahoo!の皆さんはぜひ外部からの圧力によりこれを実現せしめていただきたい
1
8
87
SDやDALLE3の構造をお気持ち的文章で説明した記事が本当にお気持ち以上の情報量がない(そんなことは論文を読んでも多分書いてない)もので、そしてそれがありがたがられているのを見て、結構わかりやすくがっかりした
1
14
84
transformersのVideoMAE実装でqkvの射影を分けた上でkだけbias=False相当にして、qvのbiasはconfigで有無を切り替えられるようにしてるのの裏の意図が謎だったが、この論文を見るとkのbiasは冗長だがそのほかには意味があるらしく、まさにこれじゃんという気持ちになった
1
7
78
NeRF(の派生手法)に関する解説記事を公開しました。
NeRFそのものの説明は割とあっさりめですが、最近にわかに盛り上がりつつある手法だと思うので、NeRFってどんな技術なのかというところにご興味がある方にも面白い内容になっているのではないかなと思います。よかったら見てみてくださいね。

📣ZENKIGEN技術ブログを更新📣
『NeRF-RPN:NeRF上で物体検出する技術』
NeRF という空間表現の中で構築された初の物体検出手法について解説しました!📸
最近流行りの NeRF 関連手法にも薄く広く触れているので、ご興味のある方はぜひご覧ください。
#NeRF
#物体検出
0
27
98
0
17
79
参考までに私の記事ですが……
こういうのどこに報告すればいいんだろう。Qiita公式?
1
11
77
AIの出自の怪しさを問われたら高圧的で偉そうに振る舞うAI使用者、痛いところを突かれて今すぐ反論せずにはいられないみたいな無意識の防御機構が顕になってて痛々しいし、自身に正当性があると思うならなおさら穏便な口調を心がけるべきだと思うのだけど、なぜ喧嘩腰になるのか
1
26
71
Hyena(S4やH3と同じ状態空間モデルの系譜)のコンテキスト長 1k~1Mのモデルが出たらしい!!
今はなぜか遺伝子コードで事前学習したモデルが公開されてるけど、モデルだけ転用してどこかお金持ってるとこがLLMにしてくれることを期待(実装が出てきたことに価値がある)

1
22
69
Transformerの発案に関わった著者らがGoogleを辞めてることは知られてたけど、かの伝説論文にて著者欄のメアド欄を棒消しにするアプデが入ったらしくパフォーマンスみがある

Looks like the Transformer authors updated the "Attention is all you need" paper with e̶m̶a̶i̶l̶s̶

9
26
293
0
17
68
LLMを2倍早く収束させるという触れ込みの新しいSophiaでも読むか Adamファミリーの牙城を崩すoptimizerって今後現れるのかなあ…(性能だけでなく誰もが使ってるとか使用が容易とか色々あるし、汎用的に強いの(脳死で代替できるか)も大事なので普及のハードルは高い)
0
10
67
ところで、界隈の中で氷山の一角である多少以上発信している人間から特につつきやすそうな(話はできそうな)人間を選んで煽ったり批判したりするのは、単に「大勢の発信しない側に戻るか、辛いし」という心理的遷移を生むだけでお互いに損なので、会話やエアリプはできるだけ穏便にお願いしたいです
1
5
67
この先しばらくは「Geminiって英語ではジェミナイって読むんですよ」「いや、公式にジェミニってお触れが出てるので」の会話が発生し続けそう
1
18
67
この図がとてもわかりやすいのだが、しれっと書いてある「任意から任意への生成を線型オーダの数の訓練目的関数で達成できる」というのが地味に凄いよな 愚直にやると組み合わせの数だけちゃんと訓練設計しないといけないので、それがCoDiで提案されたAlignment方法の良さなのだと思う
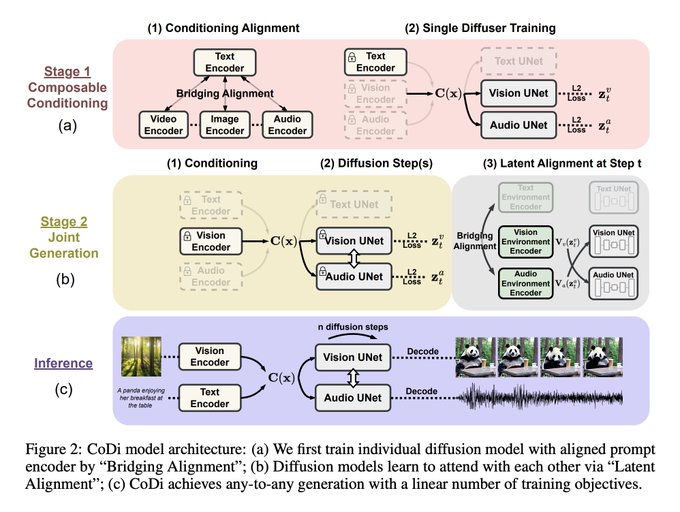
0
17
66
ツイートを引用する際の決まり事を調べるところからやってどうぞ(問題の本質はもちろんそこではない)(が、そういう低レベルなところすら適当なので全く信用に値しない)
1
30
66
LLMにClassifier-free guidanceを適用して出力制御する論文、面白い
0
6
63
$40あればGPT-4ライクな画像テキストマルチモーダルモデルが3時間程度で学習できるという触れ込みのLLaVA Lightning、そんなうまい話あるか???と思ったがVicuna-7Bから追加学習する前提らしくて納得 それでもかなり効率的な気がする
仕組みを理解すれば他のLLMにも同様の知見を適用できそう

🚀Introducing LLaVA Lightning: Train a lite, multimodal GPT-4 with just $40 in 3 hours! With our newly introduced datasets and the efficient design of LLaVA, you can now turbocharge your language model with image reasoning capabilities, in an incredibly affordable way.🧵
12
108
469
0
12
60
SD~SDXLまでVAEの潜在次元数が4なのどう考えても再構成の観点からは小さすぎるけど大きくすると拡散モデルの訓練がより難しくなるからトレードオフなんだろうなと思ってたらSD3の論文にまさにそう書いてあったし、拡散モデルのキャパがデカくなるぶんSD3では16次元になるらしくそうだよねぇの気持ちに
0
6
59
1週間ゆっくりしてる間に色々な情報がTwitterを駆け巡っていたけど、pixivさん槍玉にあげられて気の毒に…という気持ちになった pixivは元からスクレイピングを禁止してるので対策が後手になったはちょっと違うし、大手のイラストレーターの方に「信用がなくなった」と言われてるの胸がきゅっとなる
1
8
58
QuIPっていう、重み行列のHessianを使ったLLMの2 bit量子化手法が提案されたらしいので読む
数十B程度になれば、perplexityだけじゃなくて特定タスクの精度でfp16と遜色ないとこに落ち着くのかなりすごいのでは?
arxiv:
github:
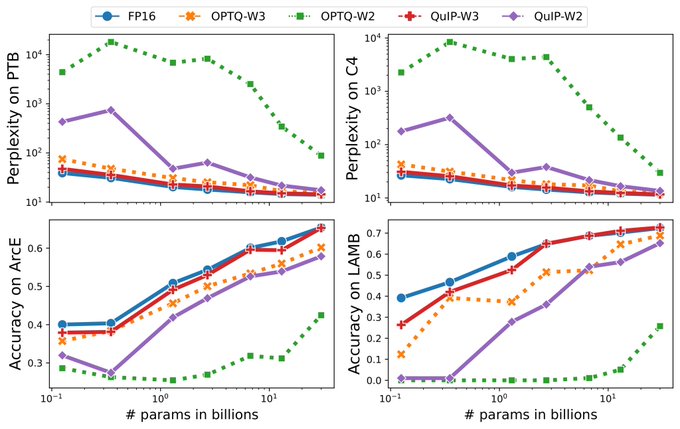
1
14
59
院試ですが、無事合格するとともに、第一志望である研究室への配属が決まったようです。期間中応援してくださった皆様、見守り激励してくださった皆様、また、恥ずかしながら荒れた呟きの群れを寛大にも見過ごしてくださった皆様へ、厚く御礼申し上げます。
春からまた同じになるみんなもよろしくです
4
0
56
3.5-turbo-16kを調教するために工夫しまくってたスキームをそのまんま4-8kに与えたら「これが欲しかったんだよ……」になった例です
内容はlatexソースから読んでるので数式とかも内容としては反映できてる
(Twitterにあげると文字どれだけ潰れちゃうかわからないけど)
arxiv-summarizer、試行錯誤で山ほどトークン消費するから3.5-16k系でずっと実験してるけど、3.5は本当に指示を聞いてくれないので疲弊し続けてて、気まぐれで任意モデル対応できるよう拡張してgpt4-8kに変えたら回答安定性と精度が爆上がりして感涙した
感涙したが、常に4を選択する余裕はねぇんだ…
1
3
31
1
5
56
Whisper, TTS, Assistant API, function callingの組み合わせで披露したデモが超洒落てる
「聴講者からランダムに5人選んで$500のOpenAIクレジットを付与してあげて!」と音声入力、対話的にアシスタントAIが自動で抽選して音声応答する様を見せた後、場の全員にクレジット付与してあげる太っ腹ぶり
1
10
55


著者の方に修正した式と計算内容を確認する簡単なnotebookを共有するメールを送ってみたので、せっかくですし該当部分だけこちらでも共有しようと思います 何かお気づきのことがあればご意見いただけると私としても嬉しいです(何もないに越したことはないが)

RetNetのchunkwise retentionのこの式、絶対オリジナルのretentionの厳密な分解になってないだろと思ってトイコード書いたらやっぱり値が一致しなかったので色々暗算してたら厳密にchunkwiseに分解できる式に辿り着いて、実装上分解する場合としない場合が厳密一致することも確認した
2
6
104
2
7
53
データが非商用かなんて気にせず使えばいいじゃん論、そうできたら最高だがレピュテーションリスクとか色々あるからみんな慎重になっているのであり、あとそもそも著作権法がカバーする領域というよりOpenAIの規約に触れる別軸の話なので、想像よりややこしいんですよね
参考:

1
5
53
少し前に一部界隈でやたら絶賛されてた『出会って4光年で合体』が気になって初めてFANZAで買い物したけど、ここ十数年で一番衝撃的な読み物だった、というかまだ6割と少ししか読み終わってないけど、間違いなくそうなる確信がある このボリュームと内容で1,100円なのは何かのバグな気がする……
2
9
51
社会人になってから、V100 8枚挿どころかA100 8枚挿のGPUマシンが複数台あった出身研究室の凄さに改めて気づくな…
1
4
50
この要求がそのまま実現することはおそらくないと思うけど、こういうことを組織立って主張する人の声が目立ち始めることに、影響力という意味での一定以上の価値があるんだろうなあと感じたりしますね とはいえどういうところに落ち着くんだろうなあこの泥沼の問題

機械学習に著作物を使う場合に許可を取る、というのは今の情報解析を無条件許可してる著作権法と真っ向から衝突するし、政府は AI の方を優先する方針っぽいから分かりあえなさそうだよなぁ この規定を廃止したら実質日本で GPT みたいな LLM は作れなくなるので
#nhk
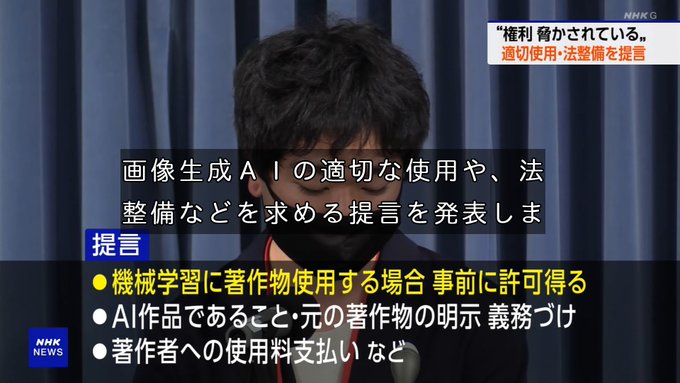
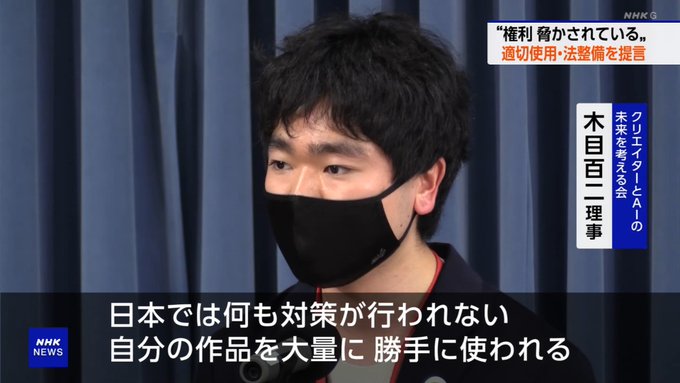
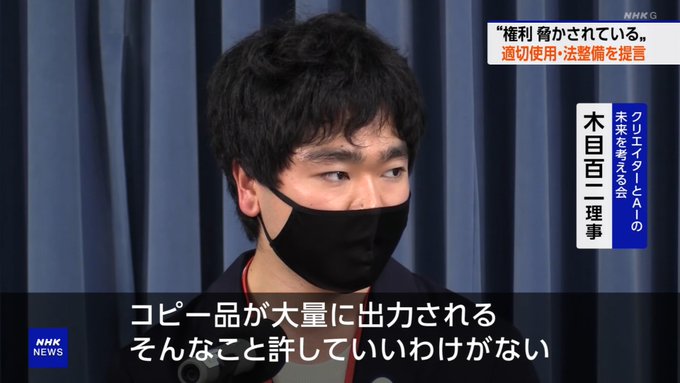
36
396
883
1
25
48
報道や町内放送の激しさも受け、念の為家族で山の方に移動することになりました 何もなければ夜には普通に帰れるはずですが……
1
2
49
多視点ビデオを入力とした4K解像度での動的な3次元再構成で、RTX 4090だと80FPSで動いたりするらしい
NeRF系かと思ったら点群処理に基づくようで、その辺追ってないからこんなに綺麗にいくのに驚いた(点群からのレンダリング研究が既に発展してるのか提案手法の貢献かは門外漢なのでこれから読む)

4K4D: Real-Time 4D View Synthesis at 4K Resolution
Proposes a 4D point cloud representation that supports hardware rasterization and enables unprecedented rendering speed
proj:
abs:
6
92
486
0
11
47
こちらLLaMA2が実質商用可能なのでこのように発信されたのだと思いますが、LLaVAはもともと研究用途限定ですし、LLaMA2 based LLaVAに用いられたLLaVA-Lightningデータセットも非商用なので注意が必要かなと思いました
1. LLaVA license
2. LLaMA2 based LLaVAの概要
3, 4. LLaVA Lightning

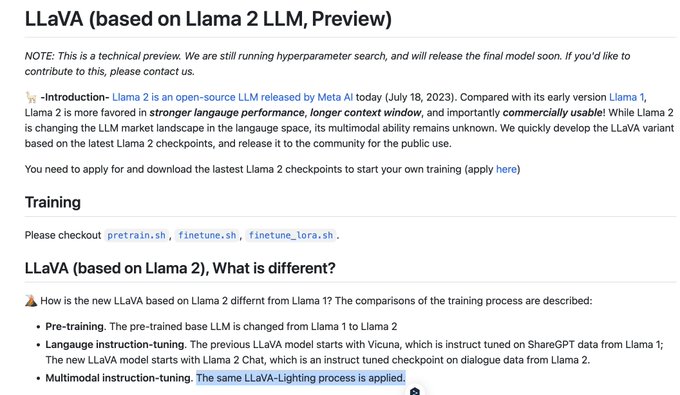



1
5
47
自分の能力を伸ばすことの面白さ以上に面白いことってあんまりないと思うんだけど、別にリアルってゲームのように簡単にステータスが向上するわけじゃないから基本億劫さが勝ってあんまり伸びずに漠然としたつまらなさを抱える、っていうのが実際は何にもマイナスじゃないのに勝手に鬱屈とする脳のバグ
1
5
45
研究関連の話題で恐縮なのですが、このたび私の初主著がAIの国際会議ICLR 2021に採択されました。
・主著をトップカンファに通す
・M1でトップカンファに通す
・卒論の延長をどこかの会議に通す
を同時に実績解除できて気持ちがふわふわしています。やったね。
6
0
46
GPT4 Turbo 128k(gpt-4-1106-preview)を雑に試してみた感じ、従来より賢くて視野が広くて速くて安いです。今までありがとうございました。
1
1
46
pytorchのDDP中にDataLoaderが不可解な場所で突然deadlockする現象が永久に付き纏っていて辛い、num_workers=0にすれば解決するとかそういう苦し紛れの妥協案が欲しいのではなく、ちゃんとnum_workers>0の状態で安定稼動するpytorchをください……
1
3
43
👀
あのGeminiの衝撃的なデモが、descriptionに書いてあったように単に「応答速度を短縮し、応答を簡潔にした」だけのverではなさそうなことを指摘していて、それはGoogle公式のブログ()を見ればよくわかる つまりデモはあくまでデモってこと

1
8
41

メタ的なことを考えると、こういうロビー活動的なことをしないとTVはちゃんと取り上げてくれないし、TVが取り上げてくれないと知らないままでいる人が大量にいて、そうするとTwitterという狭き世界を飛び出した先での世論はAI万歳のままになっちゃうので、議論を加速させる意味で重要な歩みだとは思う
0
19
37
rectified flowとかいう拡散モデルと関わりが深く重要そうな概念を今まで全然知らなかった…
0
6
39
このブログ流し見してたけど思ったより重要なこと書いてある気がしてきた
確かにAttentionの残差接続でAttentionから必ず何かしらの値が加算されるようになってる(実質的にsoftmaxで必ず何かしらのvalueが選択されなければならない)のはcoolじゃないのかも
1
2
39
実用性は置いといて画像生成技術も今のLLM水準に巨大化させたら「学んだ画像もそっくり出せるしその概念混合も人間と遜色ないレベルでできる」ところまでいずれいくだろうし、その発展は多分不可逆なので、やはり「出てきた結果をどう扱うか」が今後ますます重要な議題になってくのだろうなという感じ
0
15
38
新しく出るらしい生成AIの本、中身がいいものだとしても帯見た時点で敬遠しちゃう系のやつだったのでとても残念だし、まあそういうキャッチーなコピーに興味を持たない・喜ばない層は元からある程度分野観を知ってるものとして想定読者層からは弾かれてるものと思うことにしよう(本当か?)
2
3
36