
Pulse
@Pulse__AI
Followers
613
Following
224
Media
2
Statuses
55
Production-grade unstructured document extraction
San Francisco, CA
Joined June 2024
The @Pulse__AI team just published "The Precision Tax" - why "99% accuracy" fails in finance. One percent error in financial document processing means broken valuations, failed covenant tests, and regulatory exposure. The real benchmark isn't accuracy, it's determinism. Same

1
2
8
Culture building is everything when you're asking engineers to solve the hardest problems for enterprises. The entire @Pulse__AI team is usually in the office 12 hours a day - everyone needs to be in one place, building together. Having an immediate feedback loop is incredibly

0
2
4
@pulse__ai just launched formula recognition. trained on 10m+ formula/latex pairs from papers + handwritten notes. traditional ocr breaks on math (α, β, fractions, matrices). our model treats formulas as structured objects → clean latex. built on pulse’s production-grade

7
5
29

Join us!

almost 700m pages processed so far. we’re hiring engineers + ops in sf. $10k referral bonus. join us - link in comment.

0
0
6
Pulse (@Pulse__AI) just launched their state-of-the-art document extraction platform. It turns complex PDFs, scans, decks, and images into LLM-ready data. No training required. https://t.co/ZkO6uB55FB Congrats on the launch, @sid_mnk and @ritvikpandey21!
18
26
286
@pulse__ai team just dropped why "98% accurate" document extraction still breaks in production with 4000 errors per 1000 pages. single accuracy scores miss broken reading order, shifted table columns, and lost cross page context that silently corrupt entire datasets. we’ve

2
3
7
the team at @Pulse__AI put bytedance's dolphin OCR to the test against complex documents that matter for real business use cases. while it shows improvements in reading order detection, we found critical limitations across key areas: - 7.7% structured data extraction from

5
3
17
we're super excited to be launching Meridian publicly! no more analysts having to manually copy numbers from pdfs into spreadsheets at 2 am before a board deadline if you're interested in trying it out give me a DM! 🫡

Pulse (@Pulse__AI) has just launched Meridian, an AI-powered financial document processor that can automatically convert any PDF, Word doc, PowerPoint presentation, or image into a structured Excel export with charts and graphs. https://t.co/GlQUIcWmGh Congrats on the launch,
3
4
24
Pulse (@Pulse__AI) has just launched Meridian, an AI-powered financial document processor that can automatically convert any PDF, Word doc, PowerPoint presentation, or image into a structured Excel export with charts and graphs. https://t.co/GlQUIcWmGh Congrats on the launch,
25
26
306
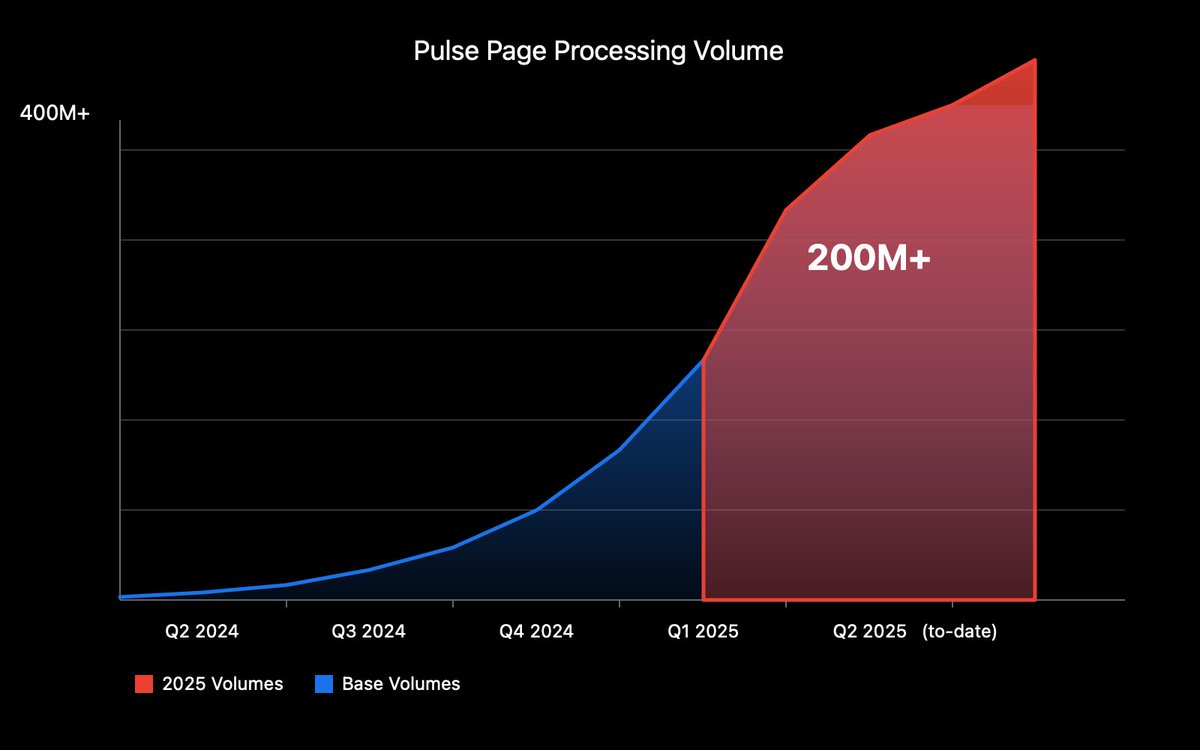
After processing nearly 500M pages, we discovered the biggest challenge in document AI isn't OCR accuracy - it's semantic understanding across page breaks and column boundaries. 🧵 (1/8)

2
2
20
After processing 400M+ pages for the world's largest investment firms, AI startups, and Fortune 500s, @Pulse__AI is launching Ultra: their new hybrid reasoning model. It's the most accurate document extraction model in the industry. Live for all customers today.
18
31
257
we got @pulse__ai's infrastructure and initial training done in just 14 days. that was impressive, but that final 1% meant tackling hundreds of edge cases - especially skewed pdf scans. our solution: we detect bounding boxes, calculate skew angles, apply transformation matrices,
1
3
14
Announcing @Pulse__AI's YC deal @ycombinator X25 founders get Pulse free of charge throughout the batch! Use the most accurate document extraction API for free - the same tech used by leading multibillion dollar public enterprises, top AI companies, and many in the recent YC

1
4
14
good times

one thing about startups is how short iteration time becomes. we're building a completely new feature from 0-1 with a strict 10 day deadline for a 100B enterprise. not sure how long this would at a large co
0
0
4
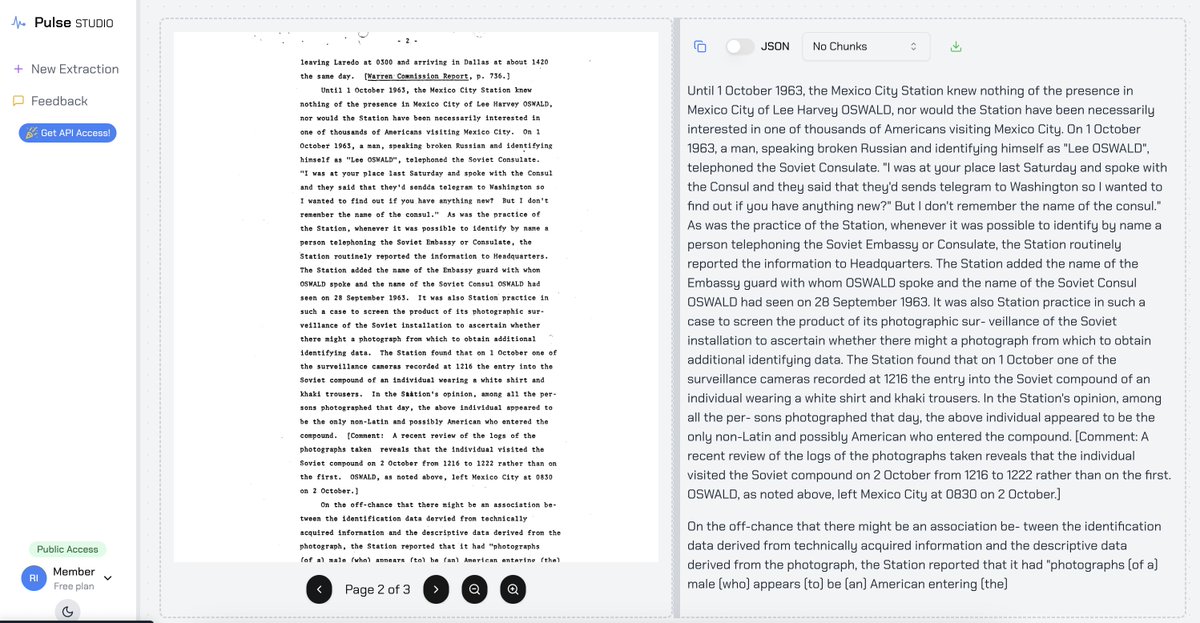
the rate of information absorption in 2025 is truly unfathomable. it would take humans approximately 50 days to read through the 70,000+ pages of jfk assassination documents (at 300 wpm or 1 page/min). with @pulse__ai's models we processed these in parallel just overnight - we
0
2
10
cool weekend experiment our team wanted to implement: building a quick rag frontend with @pulse__ai ocr on the recent jfk files. extraction quality on these old redacted pages is p perfect, even got the handwritten notes. dm me for some credits if anyone’s interested in building

1
2
10
. @grok explain why @pulse__ai’s ocr found "MARILYN CALLED AGAIN" in jfk’s "official schedule”
2
2
8