

Bradley Love
@ProfData
Followers
6K
Following
2K
Media
157
Statuses
1K
Senior research scientist at @LosAlamosNatLab. Former prof at @ucl and @UTAustin. CogSci, AI, Comp Neuro, AI for scientific discovery Also @profdata on Bluesky
London, UK
Joined September 2014
"Large language models surpass human experts in predicting neuroscience results" w @ken_lxl and https://t.co/YOhCmQlJsu. LLMs integrate a noisy yet interrelated scientific literature to forecast outcomes. https://t.co/49WYirBdBv 1/8
15
167
671


Intuitive cell types don't necessarily play the ascribed functional role in the overall computation. This is not a message the field wants to hear as it suggests better baselines, controls, and some reflection. https://t.co/l0aedcRrnM... w @ken_lxl , @robmok.bsky.social @ 2/2
0
0
0
"The inevitability and superfluousness of cell types in spatial cognition". Intuitive cell types are found in random artificial networks using the same selection criteria neuroscientists use with actual data. https://t.co/l0aedcRrnM... 1/2
1
0
2
Working with monkey data, we found neural representations stretched across brain regions to emphasize task relevant features on a trial-by-trial basis. Spike timing mattered over spike rate. Deep nets did the same. https://t.co/P3v6oB1LtA 2/2
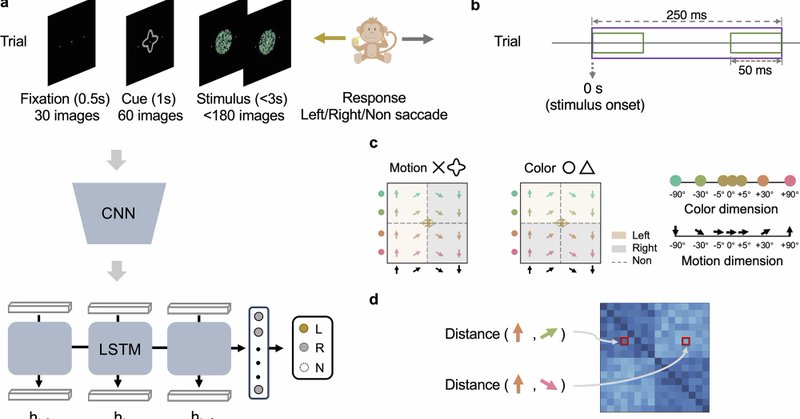
nature.com
Nature Communications - How the brain adapts its representations to prioritize task-relevant information remains unclear. Here, the authors show that both monkey brains and deep learning models...
0
2
5

Ep. 3 of Nationwide Amplified: Tai McNeely, co-founder of His & Her Money, shows how purpose + determination turn obstacles into opportunities—and inspire community along the way.
2
2
54
Exciting "new" work illustrating our broken publishing system. @seb_bobadilla presented this work online at neuromatch 2.0 at the height of the pandemic. Then, @xinyazhang_ worked years on addressing reviewer comments, which added some rigor but didn't change the message. 1/2
1
2
3
We developed a straightforward method of combining confidence-weighted judgments for any number of humans and AIs. w @yanezlang, Omar Minero, @ken_lxl 2/2
0
0
0
When AI surpasses human performance, what's left for humans? We find that human judgment boosts performance of human-AI teams because humans and machines make different errors. https://t.co/6yHm4dCBwq 1/2

cell.com
When AI surpasses human performance, what can humans offer? We demonstrate that the performance of teams increases by integrating human judgments with those of machines. Integration is achieved by a...
1
0
1

Researchers are using LLMs to analyze the literature, brainstorm hypotheses, build models and interact with complex datasets. Hear from Martin Schrimpf @martin_schrimpf, Kim Stachenfeld @neuro_kim, Jeremy Magland, Bradley Love and others. https://t.co/HHAOg4BUOD

thetransmitter.org
Eight researchers explain how they are using large language models to analyze the literature, brainstorm hypotheses and interact with complex datasets.
0
3
19

🧵🎉 Our mega-paper is finally published in TMLR! We're "Getting Aligned on Representational Alignment" - the degree to which internal representations of different (biological & artificial) information processing systems agree. 🧠🤖🔬🔍 #CognitiveScience #Neuroscience #AI
5
37
151

What futures could, and should, we create with advanced AI? Today we are announcing two possible paths – Tool AI and d/acc – with contributors like @VitalikButerin @owocki @AdamMarblestone and @AnthonyNAguirre
6
10
29
New blog w @ken_lxl, “Giving LLMs too much RoPE: A limit on Sutton’s Bitter Lesson”. The field has shifted from flexible data-driven position representations to fixed approaches following human intuitions. Here’s why and what it means for model performance
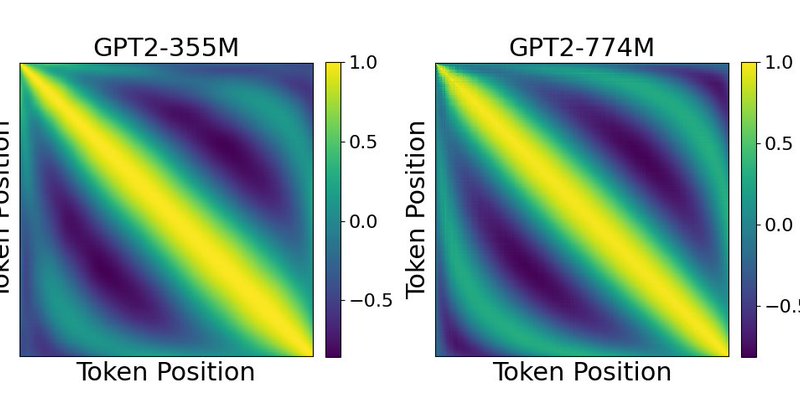
bradlove.org
Introduction Sutton’s Bitter Lesson (Sutton, 2019) argues that machine learning breakthroughs, like AlphaGo, BERT, and large-scale vision models, rely on general, computation-driven methods that...
0
2
10
New blog, "Backwards Compatible: The Strange Math Behind Word Order in AI" w @ken_lxl. It turns out the language learning problem is the same for any word order, but is that true in practice for large language models? paper: https://t.co/SSU3WwfC94 BLOG: https://t.co/PQBEVnPIeu
0
2
4
When LLMs diverge from one another because of word order (data factorization), it indicates their probability distributions are inconsistent, which is a red flag (not trustworthy). We trace deviations to self-attention positional and locality biases. 2/2

arxiv.org
Can autoregressive large language models (LLMs) learn consistent probability distributions when trained on sequences in different token orders? We prove formally that for any well-defined...
1
0
3
"Probability Consistency in Large Language Models: Theoretical Foundations Meet Empirical Discrepancies" Oddly, we prove LLMs should be equivalent for any word ordering: forward, backward, scrambled. In practice, LLMs diverge from one another. Why? 1/2
arxiv.org
Can autoregressive large language models (LLMs) learn consistent probability distributions when trained on sequences in different token orders? We prove formally that for any well-defined...
1
3
13

🧠 We speak with Prof. Bradley Love about BrainGPT—an AI model helping researchers process neuroscientific data faster than ever. 🔍 How does BrainGPT work? 🚀 Where is AI taking brain research next? 🎧 https://t.co/uFnarK8BHD
@ProfData
0
1
3
"Coordinating multiple mental faculties during learning" There's lots of good work in object recognition and learning, but how do we integrate the two? Here's a proposal and model that is more interactive than perception provides the inputs to cognition.
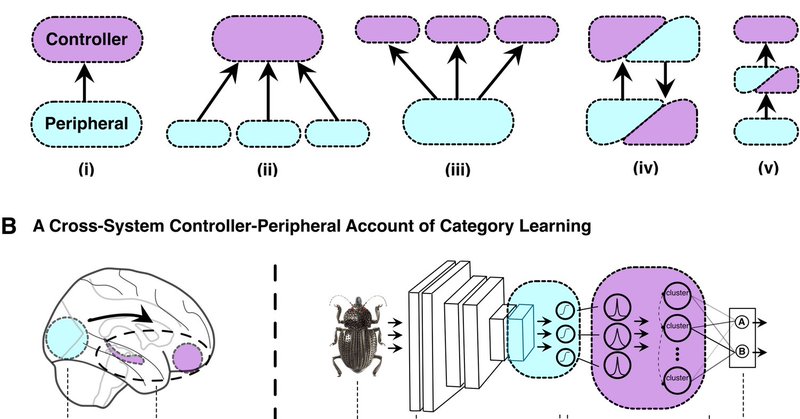
nature.com
Scientific Reports - Coordinating multiple mental faculties during learning
1
19
66

Last year, we funded 250 authors and other contributors to attend #ICLR2024 in Vienna as part of this program. If you or your organization want to directly support contributors this year, please get in touch! Hope to see you in Singapore at #ICLR2025!

Financial Assistance applications are now open! If you face financial barriers to attending ICLR 2025, we encourage you to apply. The program offers prepay and reimbursement options. Applications are due March 2nd with decisions announced March 9th.
2
13
73
🚨Call for Papers🚨 The Re-Align Workshop is coming back to #ICLR2025 Our CfP is finally up! Come share your representational alignment work at our interdisciplinary workshop at @iclr_conf
https://t.co/taAxgAwaT1
3
16
64