
Brace(Hanyang) Zhao
@OptionsGod_lgd
Followers
81
Following
247
Media
7
Statuses
63
PhD student at @Columbia working on post training generative models | MLR intern @Netflix, ex LLM intern at @CapitalOne
Manhattan, NY
Joined April 2021
Find something in common: I was a Divine 5 Dota2 player!.



0
0
1
Why IRCC is soooo slow? Can not make any plans for #ICML2025 since my Canada visa application has been processed for more than a month. .
1
0
0
RT @robinphysics: Maybe to one's surprise, taking KL estimates as `kl_loss` to minimize does *not* enforce the KL. This implementation, ho….
0
52
0
RT @DavidAnugraha: ⚠️New Paper Alert⚠️.Introducing R3: Robust Rubric-Agnostic Reward Models 🎉. TL;DR: R3 is a novel reward modeling framewo….
0
5
0
RT @SFResearch: We're thrilled to announce BLIP3-o, a breakthrough in unified multimodal models that excels at both image understanding and….
0
8
0
BTW, people are talking about Goodhart's law for RLHF, i.e. the model could be over-optimized to imperfect reward models. Sometimes, I feel like many phd students ourselves are also optimizing us for better publications. .
0
0
0
Joint work with @RainChe64681275, Ji Zhang and my advisors Wenpin Tang and David Yao. See everybody in Vancouver this summer!.
0
1
1
Maybe a bit late, but I am thrilled to announce that our Scores as Actions ( paper is accepted by #icml2025 🎉 We propose a continuous-time RL method for diffusion models RLHF (which are naturally continuous time) and perform better than discrete-time RL!.
2
0
6
it's horrible to imagine that there will be likely more than 7500 even neurips 2025 *accepted* papers. .

🤯NeurIPS 2025 might break records as the most submitted-to academic conference ever. One of our submission IDs is already ~23,000 — final count could hit 30,000. Absolute madness. #NeurIPS2025 #AI.
1
0
1
Disclaimer: 95% poster presenters, not matter which company or institute, were super great!.
0
0
0
When attending #ICLR2025 poster sessions, it is a super rewarding and nice experience when talking to authors who not only make nice posters and are also more than happy to showcase their work and contributions detailed and vividly, exchange ideas, even to the audience who might.
1
0
5
RT @gentaiscool: ⭐️We're thrilled to share that our paper WorldCuisines has been selected for the Best Theme Paper Award at NAACL 2025 @naa….
0
15
0
Will also present a diffusion models RLHF paper at DeLTa Workshop. Would love to chat about any emerging post training recipes for diffusion models!.
0
1
1
Will 🛩️ to Singapore to attend ICLR this coming week! More than thrilled to present two accepted poster papers both on LLM RLHF, on behalf of my amazing collaborators! . Looking forward to meet old and new friends!

2
2
3
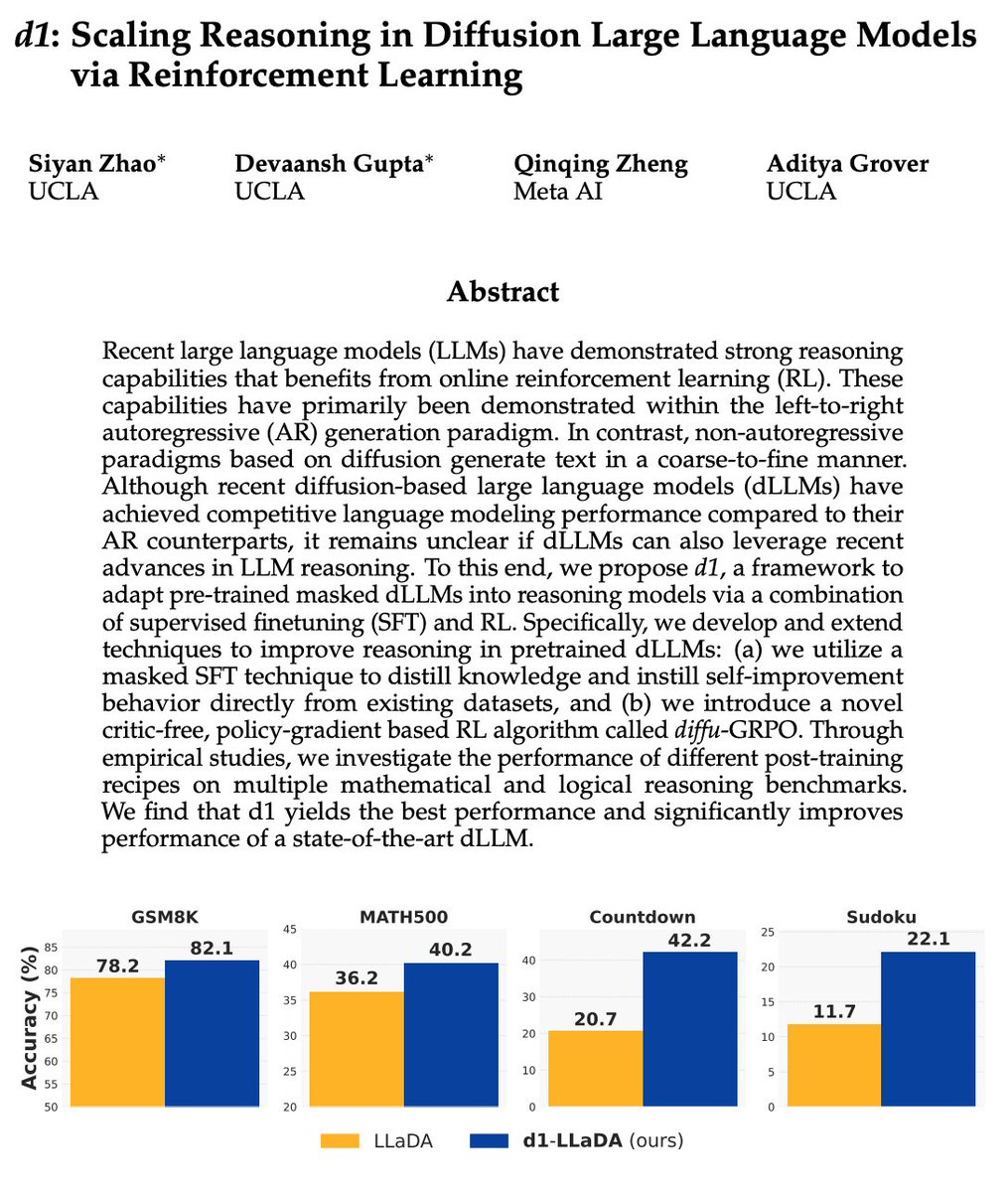
R1 style of post-training for dLLM! I was discussing with my summer internship mentor that there would be more than 10 paper submissions possibly at this year's NeurIPS for post training discrete diffusion LLMs. Now I feel that I was way tooo conservative.

Introducing d1🚀 — the first framework that applies reinforcement learning to improve reasoning in masked diffusion LLMs (dLLMs). Combining masked SFT with a novel form of policy gradient algorithm, d1 significantly boosts the performance of pretrained dLLMs like LLaDA.
0
0
2