

FAIR Chemistry
@OpenCatalyst
Followers
3K
Following
69
Media
46
Statuses
212
AI for chemistry and material science @AIatMeta. Previously known as Open Catalyst Project.
Joined June 2021
Introducing fairchem - our revamped codebase consolidating our AI modeling efforts in chemistry and materials science. fairchem makes it easy to interface with our data, models, demos, and applications - including an easy to use ASE calculator:.
2
29
99
RT @SamMBlau: The Open Molecules 2025 dataset is out! With >100M gold-standard ωB97M-V/def2-TZVPD calcs of biomolecules, electrolytes, meta….
0
103
0

Introducing the newest members to the family - OMol25 and UMA. Check them out below!.

Excited to share our latest releases to the FAIR Chemistry’s family of open datasets and models: OMol25 and UMA! @AIatMeta @OpenCatalyst . OMol25: UMA: Blog: Demo:
1
12
58
RT @xiangfu_ml: For existing MLIPs, lower test errors do not always translate to better performance in downstream tasks. We bridge this gap….

arxiv.org
Machine learning interatomic potentials (MLIPs) have become increasingly effective at approximating quantum mechanical calculations at a fraction of the computational cost. However, lower errors...
0
23
0
Today we're excited to introduce OCx24 - an experimental catalyst dataset aimed to help bridge the gap between computational and experimental results. Read more below!. Paper: Dataset: Blogpost:
ai.meta.com
Meta FAIR is releasing a large-scale dataset of experimental results on various materials, providing valuable insights for the development of new catalysts.

Excited to unveil OCx24, a two-year effort with @UofT and @VSParticle! We've synthesized and tested in the lab hundreds of metal alloys for catalysis. With 685 million AI-accelerated simulations, we analyzed 20,000 materials to try and bridge simulation and reality. Paper:.
0
11
55
RT @anuroopsriram: I’m excited to share our latest work on generative models for materials called FlowLLM. FlowLLM combines Large Language….

arxiv.org
Material discovery is a critical area of research with the potential to revolutionize various fields, including carbon capture, renewable energy, and electronics. However, the immense scale of the...
0
43
0
RT @bwood_m: Our team at FAIR is looking for research interns in 2025. We work on a range of AI for chemistry topics from applied projects….
0
30
0
Work by @lbluque, @mshuaibii, @xiangfu_ml, @bwood_m, @csmisko, Meng Gao, @ammarhrizvi, C. Lawrence Zitnick, @zackulissi . Get in touch to share your experience and feedback!.
1
0
13
This work builds upon open research, notably Alexandria and the Materials Project, and wouldn’t have been possible without those efforts!. Alexandria:. Materials Project:. 6/x.
1
1
18
When training EquiformerV2 (31M) on only MPtrj we found that adding an auxiliary denoising objective (see DeNS substantially improved performance due to effective data augmentation and by preventing overfitting on a smaller dataset. 5/x

2
0
13
Our EquiformerV2 (86M) model pre-trained on OMat and fine-tuned on MPtraj and a subset of Alexandria, is state-of-the-art on Matbench discovery across all metrics with an F1 score > 0.9 and an accuracy of 20 meV/atom. 4/x

1
2
26
Data diversity was achieved by sampling relaxed structures from Alexandria followed by one of three different processes:. - Rattled Boltzmann Sampling.- Ab-Initio Molecular Dynamics.- Rattled Relaxation. 3/x.
1
0
16
OMat24 contains over 100 million Density Functional Theory calculations focused on structural and compositional diversity. The force and stress distributions are substantially more broad than other open datasets for training ML potentials. 2/x

1
3
20
Introducing Meta’s Open Materials 2024 (OMat24) Dataset and Models! All under permissive open licenses for commercial and non-commercial use!. Paper: Dataset: Models: 🧵1/x

16
174
618
Come work with us on the FAIR Chemistry team!. Roles:.- Postdoc: - Research interns: Reach out if you have any questions and help spread the word!.
0
8
34
0
0
2
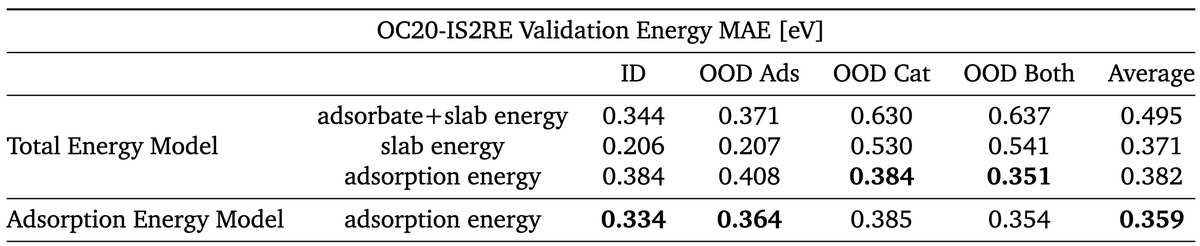
Before using an adsorption energy model, one should be aware of surface reconstructions that can impact results. Alternatively, total energy models are more robust models to surface reconstructions that still work on par with existing adsorption energy models
1
0
1
Perhaps the most notable impact on errors are surface reconstructions. This can pose an ill-defined adsorption energy, making it difficult for models to train and evaluate.

1
0
0
Interestingly, they also show that the performance of models trained on data with the tighter DFT settings is comparable to those trained with the original OC20 settings.

1
0
1
While tighter convergence settings have a considerable impact on DFT total energy; when they look at energy differences like the adsorption energy, they see significantly smaller convergence errors due to a cancellation of errors. Results shown for the OC20-200k dataset.

1
0
1