

NVIDIA AI PC
@NVIDIA_AI_PC
Followers
23K
Following
282
Media
143
Statuses
470
NVIDIA Powers the World's AI. And Yours with RTX AI PCs. 💻🚀 #AIonRTX
Joined November 2024
Hey there! 👋 Welcome to the new NVIDIA AI PC channel! 💻 Whether you are deep into AI or just a little curious, we're here to explore the power of AI on your local PC. Follow along for the latest news, tech, and AI inspiration. 🚀
81
90
439

This was one of my favorite videos to make. I learned about Reinforcement Learning and Verifiable Rewards; enabling a model to get really good at the game 2048. We used @UnslothAI, @OpenAI's GPT-OSS, and @NVIDIA_AI_PC RTX 5090. Full tutorial below.

We teamed up with @NVIDIA and @MatthewBerman to teach you how to do Reinforcement Learning! Learn about: - RL environments, reward functions & reward hacking - Training OpenAI gpt-oss to automatically solve 2048 - Local Windows training with @NVIDIA_AI_PC RTX GPUs - How RLVR
5
5
50

.@nvidia Nemotron 3 Nano is now available on Ollama! Local ollama run nemotron-3-nano Cloud ollama run nemotron-3-nano:30b-cloud

Today, @NVIDIA is launching the open Nemotron 3 model family, starting with Nano (30B-3A), which pushes the frontier of accuracy and inference efficiency with a novel hybrid SSM Mixture of Experts architecture. Super and Ultra are coming in the next few months.
6
26
212
Learn how to get started with fine-tuning on RTX GPUs using Reinforcement Learning in this tutorial hosted by @MatthewBerman. 🤝
We teamed up with @NVIDIA and @MatthewBerman to teach you how to do Reinforcement Learning! Learn about: - RL environments, reward functions & reward hacking - Training OpenAI gpt-oss to automatically solve 2048 - Local Windows training with @NVIDIA_AI_PC RTX GPUs - How RLVR
0
6
36

In collaboration with NVIDIA, the new Nemotron 3 Nano model is fully supported in llama.cpp Nemotron 3 Nano features an efficient hybrid, Mamba, MoE architecture. It's a promising model, suitable for local AI applications on mid-range hardware. The large context window makes it
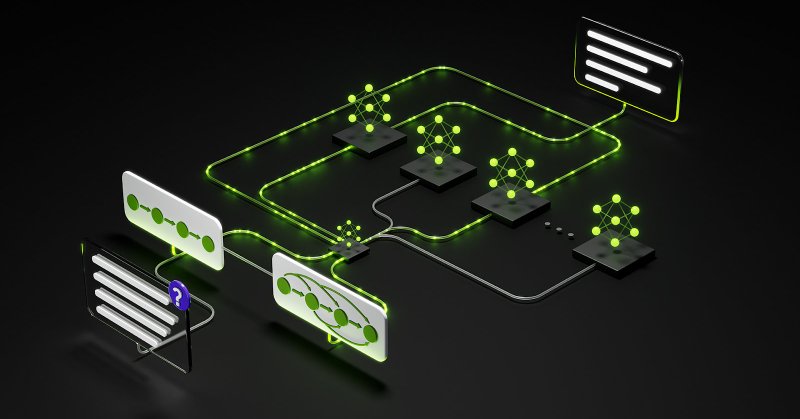
developer.nvidia.com
Agentic AI systems increasingly rely on collections of cooperating agents—retrievers, planners, tool executors, verifiers—working together across large contexts and long time spans.
8
44
398

Nemotron 3 Nano by @nvidia, available now in LM Studio! 👾 > General purpose reasoning and chat model > MoE: 30B total params, 3.5B active > Supports up to 1M tokens context window > Hybrid arch: 23 Mamba-2 and MoE layers, 6 Attention layers Requires ~24GB to run locally.
13
41
457
NVIDIA releases Nemotron 3 Nano, a new 30B hybrid reasoning model! 🔥 Nemotron 3 has a 1M context window and the best in class performance for SWE-Bench, reasoning and chat. Run the MoE model locally with 24GB RAM. Guide: https://t.co/UAHCV8dMNC GGUF: https://t.co/XdmG9ZSnNQ
42
211
2K
What if you could 𝙩𝙚𝙖𝙘𝙝 an AI instead of just prompting it? 🤔 Our #RTXAIGarage blog explains how 𝗳𝗶𝗻𝗲-𝘁𝘂𝗻𝗶𝗻𝗴 𝗮𝗻 𝗟𝗟𝗠 works and why NVIDIA RTX GPUs & DGX Spark make it easy to do locally using @UnslothAI. 🔗: https://t.co/I086DnEv3r
4
15
80


Starting out as a creator this #GeForceSeason? 🎬🖌️ Gavin Herman explored how the @LenovoLegion 5i laptop with a NVIDIA GeForce RTX 5060 GPU handles real creative workflows & is a great choice for beginners:
2
3
12

We worked with @nvidia_ai_pc & @ComfyUI to offer a lighter version of FLUX.2 [dev] with an FP8 quantization version. Read more here

blogs.nvidia.com
Optimized for NVIDIA RTX GPUs the new models are available in FP8 quantizations that reduce VRAM and increase performance by 40%.
2
3
23
Fine-tune Mistral 3 using @UnslothAI on your RTX AI PC to do things like solve Sudoku!
Mistral releases Ministral 3, their new reasoning and instruct models! 🔥 Ministral 3 comes in 3B, 8B, and 14B with vision support and best-in-class performance. Run the 14B models locally with 24GB RAM. Guide + Notebook: https://t.co/MzJlG2l5Qr GGUFs: https://t.co/CqngUmHdTX
0
2
7

Introducing the Mistral 3 family of models: Frontier intelligence at all sizes. Apache 2.0. Details in 🧵
175
833
5K
🎉 We’re excited to partner with @MistralAI on the Mistral 3 family of models, giving researchers and developers access to true frontier-class tech — including 10X better generational performance for Mistral Large 3 mixture-of-experts model. Huge congrats to the Mistral AI team
23
58
357
We joined forces with NVIDIA to unlock high-speed AI inference on RTX AI PCs and DGX Spark using llama.cpp. The latest Ministral-3B models reach 385+ tok/s on @NVIDIA_AI_PC GeForce RTX 5090 systems. Blog:

developer.nvidia.com
The new Mistral 3 open model family delivers industry-leading accuracy, efficiency, and customization capabilities for developers and enterprises. Optimized from NVIDIA GB200 NVL72 to edge platforms…
17
43
428

🎉 Congrats to @MistralAI on the launch of the new Mistral 3 open family of models Mistral Large 3 delivers up to 10× performance on NVIDIA NVL72 by stacking the benefits of large scale expert parallelism, inference disaggregation, and accuracy-preserving NVFP4 low-precision
11
37
218
Cyber Monday is here! ⚡🎁 Score RTX AI PC deals at @Walmart this #GeForceSeason 👉 https://t.co/E35WYsl25L
0
4
18
AI Learning, Wrapped for the Holidays 🎁 Unwrap the power of AI this holiday season. NVIDIA DGX Spark bridges education and innovation, helping students and developers build real-world skills in AI development and research—all with NVIDIA’s trusted software stack. ➡️
39
62
260
Black Friday is here! 🎁 Score RTX AI PC deals at Costco this #GeForceSeason 👉 https://t.co/iFoFDcagXD
1
3
18