
Mohammad Shoeybi
@MohammadShoeybi
Followers
341
Following
91
Media
0
Statuses
79
Director of Applied Research @NVIDIA
Santa Clara, CA
Joined May 2013
Checkout our detailed study on advancing math and code reasoning using SFT and RL.

Introducing AceReason-Nemotron 1.1. Our previous release, AceReason-Nemotron-1.0, introduced a stage-wise RL recipe that was applied sequentially to math-only and code-only prompts, demonstrating both high efficiency and strong effectiveness. Here, we systematically investigate

1
3
12
RT @ychenNLP: 📢We conduct a systematic study to demystify the synergy between SFT and RL for reasoning models. The result? We trained a 7B….
0
44
0
RT @_albertgu: exciting to see that hybrid models maintain reasoning performance with few attention layers. benefits of linear architecture….
0
13
0
We released reasoning models for Nemotron-H 8B and 47B. Great accuracies at 4x inference speed.

👀 Nemotron-H tackles large-scale reasoning while maintaining speed -- with 4x the throughput of comparable transformer models.⚡. See how #NVIDIAResearch accomplished this using a hybrid Mamba-Transformer architecture, and model fine-tuning ➡️

1
6
33
Checkout our recent work on advancing math and code reasoning through RL.
📣 Introducing AceReason-Nemotron: Advancing Math and Code Reasoning through Reinforcement Learning (RL). Starting from the SFT model DeepSeek-R1-Distill-Qwen-14B, our AceReason-Nemotron-14B achieves substantial improvements in pass@1 accuracy on key benchmarks through RL:. AIME
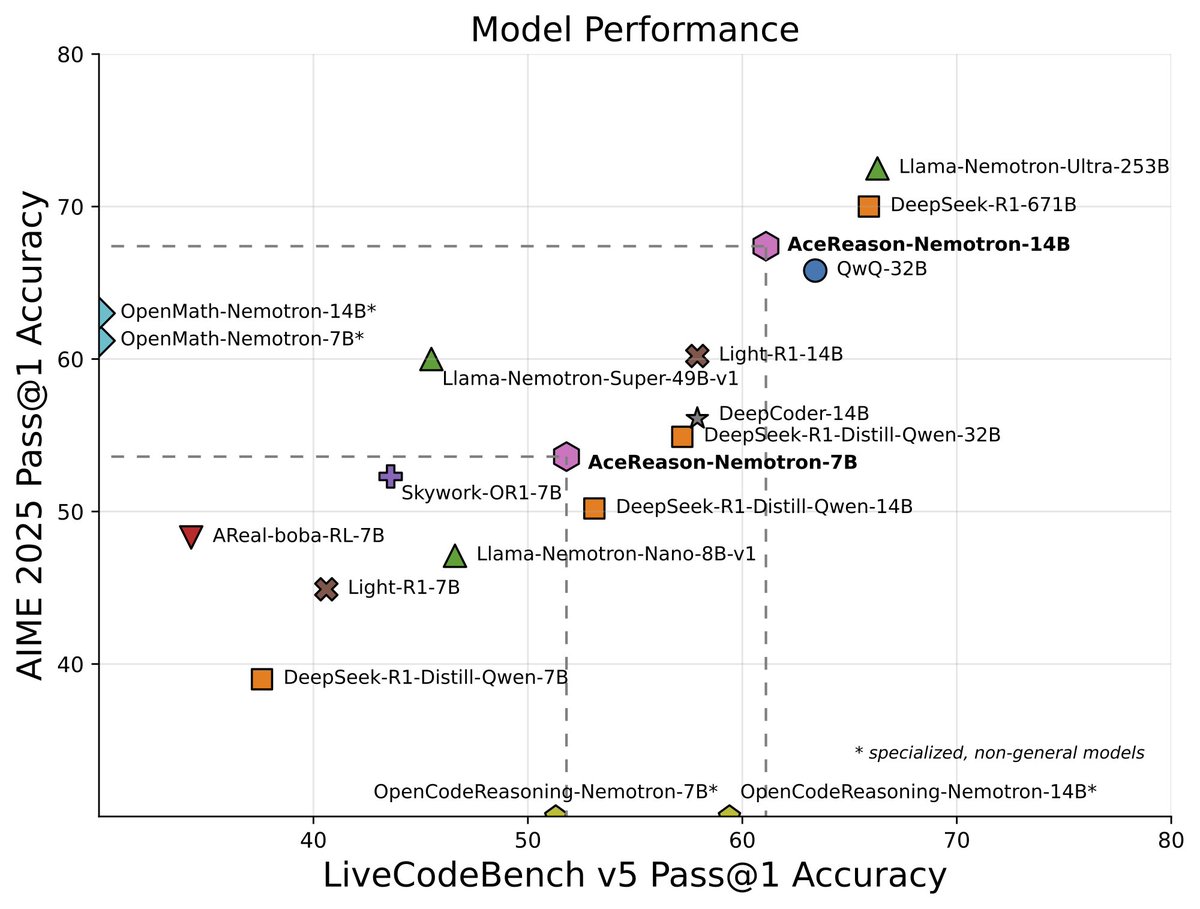
1
1
18
RT @ctnzr: It takes great data to make a great model. We're opening the data curation pipeline for Nemotron models, and we're also posting….
0
29
0
RT @_weiping: Introducing AceMath-RL-Nemotron-7B, an open math model trained with reinforcement learning from the SFT-only checkpoint: Deep….
0
22
0
RT @mapatwary: Nemotron-H base models (8B/47B/56B): A family of Hybrid Mamba-Transformer LLMs are now available on HuggingFace:. https://t.….
research.nvidia.com
Nemotron-H is a series of hybrid Mamba-Transformer models which offer either better or on-par accuracy and improved inference speed (up to 3x) compared to other similarly-sized state-of-the-art...
0
12
0
RT @ctnzr: Base model Nemotron-H weights have been released under a research license:.

huggingface.co
0
18
0
RT @_weiping: Introducing UltraLong-8B:.We extended Llama3.1-8B-Instruct to support 1M, 2M, and 4M context windows by continuing pretrainin….
0
17
0
RT @ctnzr: Nemotron-H: A family of Hybrid Mamba-Transformer LLMs. * Hybrid architecture means up to 3X faster at the same accuracy.* Traine….
0
102
0
RT @_weiping: Introducing AceMath, a cutting-edge suite of math models designed to excel at solving complex math problems, complemented by….
0
22
0
RT @_weiping: We’re at #NeurIPS 2024 in Vancouver, presenting two papers from NVIDIA on advancing state-of-the-art LLM RAG models!. ChatQA:….

arxiv.org
In this work, we introduce ChatQA, a suite of models that outperform GPT-4 on retrieval-augmented generation (RAG) and conversational question answering (QA). To enhance generation, we propose a...
0
11
0
We are very excited to release our Common Crawl based large scale dataset. This 6.3T tokens dataset will help the community develop stronger models. Check it out!.

We are excited to release Nemotron-CC, our high quality Common Crawl based 6.3 trillion tokens dataset for LLM pretraining (4.4T globally deduplicated original tokens and 1.9T synthetically generated tokens). Compared to the leading open DCLM dataset, Nemotron-CC enables to

0
4
16
RT @_weiping: Introducing NVLM 1.0, a family of frontier-class multimodal LLMs that achieve state-of-the-art results on vision-language tas….
0
123
0
RT @_weiping: We are excited to release ChatQA-2 (and its training data!), 128K long-context models that also have exceptional RAG capabili….
0
8
0
RT @_weiping: Our NV-Embed-v2, has achieved a record-breaking score of 72.31 across 56 text embedding / retrieval tasks, reclaiming the top….
0
6
0
RT @PavloMolchanov: 🚀 40x Faster Model Training via Pruning and Distillation! .Permissive Minitron-4B and Minitron-8B models!.🔗 Paper: http….
0
47
0
RT @_weiping: Introducing ChatQA 2, a Llama3-based model with a 128K context window, designed to close the gap between open LLMs and leadin….
0
41
0