

Modular
@Modular
Followers
21K
Following
672
Media
309
Statuses
1K
Building AI’s unified compute layer. We are hiring → https://t.co/cPTAes0HMt 🚀
Joined January 2022
We raised $250M to accelerate building AI's unified compute layer! 🔥 We’re now powering trillions of tokens, making AI workloads 4x faster 🚀 and 2.5x cheaper ⬇️ for our customers, and welcomed 10K’s of new developers 👩🏼💻. We're excited for the future!
14
27
190
Our Modular Meetup kicks off in just one hour! 🚀 Join us virtually at 6:30PM PT for a deep dive into the MAX framework https://t.co/SCQeUwwiwP
1
0
6
From sound to visuals, Mojo is bringing ideas to life! 🎶✨ Catch our latest community meeting recording to see: • MMMAudio by Sam Pluta, a creative audio environment in Mojo • Shimmer by @lukashermann, his cross-platform Mojo → OpenGL experiment Plus, hear from the Modular
0
2
22
By combining MAX software optimizations + AMD MI355's higher GPU memory + @TensorWave's liquid-cooled infrastructure we achieved ~2× greater inference throughput on MI355 clusters and 40-60% reduction in inference costs. Full methodology and benchmarks:
tensorwave.com
In a recent talk, Nikhil Gupta, ML Engineer at TensorWave, walked through two company case studies that show just how far you can push training and inference when you pair modern AMD hardware with...
0
0
2
For organizations running large-scale inference, this combination delivers: → The ability to run larger models or more concurrent requests on the same footprint → More tokens per second per dollar → A clear path away from single-vendor lock-in, without giving up performance
1
0
2
These gains are not theoretical. They come from real usage across multiple workloads, backed by benchmarks that we published together with @tensorwave Watch the video:
1
0
1
The numbers from real enterprise workloads: - ~2× greater inference throughput on MI355 clusters using MAX - 40-60% reduction in inference costs depending on workload - More tokens per second per dollar
1
0
1
MAX just demonstrated something important: you can break AI vendor lock-in without compromising performance. New case study with @tensorwave shows what we achieved on AMD MI355 GPUs in production: 🧵
1
0
14
Organizations running large-scale inference now have a clear path away from single-vendor lock-in—without giving up performance. MAX on AMD MI355 delivered: - 2× throughput - 40-60% cost reduction - More tokens/$ across real workloads Published benchmarks with @tensorwave:
tensorwave.com
In a recent talk, Nikhil Gupta, ML Engineer at TensorWave, walked through two company case studies that show just how far you can push training and inference when you pair modern AMD hardware with...
0
5
36

Please note that in-person space is limited and is first come, first served. Doors open at 6 PM PT and a valid Luma event registration is required for admission. Arriving late may result in being turned away if the venue has reached capacity. We recommend arriving by 6 PM PT, if
1
0
2
This Thursday, we’re breaking down the MAX platform from the inside out. Expect deep dives on JIT graph compilation, model-development APIs, and end-to-end LLM workflows — plus a session from @clattner_llvm on the MAX Framework Vision. Enjoy refreshments and connect with other

luma.com
Join us at Modular’s Los Altos office (or virtually) for a deep dive into the MAX platform. Talks include: Feras Boulala, Modular – MAX’s JIT Graph…
1
8
30
Mojo brings high-performance computing to bioinformatics tooling. @ducktapeprogra1 used Mojo to build Ish, the first composable CLI for index-free alignment-based filtering. Demoed at a Modular community meeting, now peer-reviewed & published👇
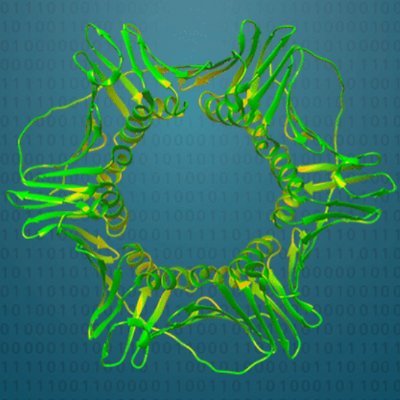
🧬Explore the latest from Bioinformatics Advances: “Ish: SIMD and GPU accelerated local and semi-global alignment as a CLI filtering tool.” Read the full paper here: https://t.co/1iNMdh5PCG
0
7
49

From an idea to powering world-leading AI models and cutting-edge accelerators — Mojo has come a long way. Now, Mojo 1.0 is on the horizon: stability, open-source plans, and new tooling for developers everywhere. Read our latest blog post to explore the road to 1.0 ⬇️
2
16
81

AI is having its Android moment. 🤚🤖 In this episode of The Neuron Podcast, we sit down with @iamtimdavis (Co-Founder & President of @Modular, ex-Google Brain) to unpack why Modular raised $250M to break AI’s GPU lock-in. Reimagine how AI gets built and deployed: 📺 YouTube:
0
3
10
Curious how Mojo🔥 achieves its GPU performance? This Modular Tech Talk covers the architecture, compiler flow, and open-source kernels behind it, and how Mojo🔥 targets CPUs and GPUs in one model.
1
5
56
Unlock high-performance AI with Modular! Watch Abdul Dakkak’s talk on Speed of Light Inference w/ NVIDIA & AMD GPUs and see how Modular Cloud, MAX, and Mojo scale AI workloads while reducing TCO. 📺 Watch here:
1
8
56
Enjoy live demos, Q&A with the team, and networking time. Doors open at 6 PM PT; talks begin 6:30 PM. In‑person space is limited (first‑come) and there will be a livestream available.
0
0
3
You’ll hear from Modular engineers on topics like: • JIT Graph Compiler • Model‑Development API • Build an LLM in MAX
1
0
3