
Minhyuk Sung
@MinhyukSung
Followers
1K
Following
218
Media
37
Statuses
104
Associate professor @ KAIST | KAIST Visual AI Group: https://t.co/mblvQKFc8t.
Joined October 2021
ALL four NeurIPS 2024 submissions from our group have been accepted! We’ve reached a remarkable milestone: EVERY student in our group has published as a first author at top-tier conferences this year, including CVPR, ECCV, SIGGRAPH Asia, and NeurIPS. Congrats to all our students!.
10
13
425
#DiffusionModels.🎓 Our "Diffusion Models and Their Applications" course is now fully available! It includes all the lecture slides, recordings, and hands-on programming assignments. Hope it helps anyone studying diffusion models. 🌐
5
98
394
#SIGGRAPHAsia2024.🔥 Replace your Marching Cubes code with our Occupancy-Based Dual Contouring to reveal the "real" shape from either a signed distance function or an occupancy function. No neural networks involved. Web:
6
55
270
In the past fall semester, I taught the "Machine Learning for 3D Data" course at KAIST. This time, I've added new material on 3D generative models. All the slides, recordings, and assignments are now available on the following course webpage:.
0
51
202
Seeking an alternative to SDS for NeRF **editing**, not generation? Try our PDS, enabling substantial changes in NeRF, surpassing InstructN2N. Transform a human body into Spider-Man, Batman, Steve Jobs, and more!. Project: arXiv:
3
26
146
🚀 I was excited to present a tutorial on "Diffusion Models for Visual Computing" at #Eurographics2024 with Niloy, Danny @DanielCohenOr1, Duygu, Chun-Hao, and Paul. The tutorial website is now live, and you can check out the slides here:.

2
19
141
A huge thank you to Jiaming Song (@baaadas) for delivering a wonderful guest lecture in our "Diffusion Models and Applications" course! He shared valuable insights on video generative models and the future of generative AI. 🎥 📚
2
28
134
🚀 Our SIGGRAPH 2024 course on "Diffusion Models for Visual Computing" introduces diffusion models from the basics to applications. Check out the website now. w/ Niloy Mitra, @guerrera_desesp, @OPatashnik, @DanielCohenOr1, Paul Guerrero, and @paulchhuang.
1
33
107
Deeply honored to receive the 2024 Asiagraphics Young Researcher Award! Grateful to all my collaborators for their support and contributions along the way. Link:

2
2
98
We are currently seeking undergraduate interns to join our team this winter. Our research is centered around 3D generation, reconstruction, and editing, with a specific focus on generative AI. If this opportunity interests you, please visit this webpage:

5
14
97
Check out our recent work on #diffusion synchronization, which can be applied to #panorama generation, 3D #texturing, and more, providing the best quality in mesh texturing and also enabling #GaussianSplat texturing!. SyncTweedies: 🧵(1/5)
1
18
90
I was thrilled to present a talk at the NVIDIA Toronto Lab on my way to NeurIPS 2023, titled "Moving Beyond 3D Generation to Editing with Image Diffusion Priors." Check out the slides using the link below. Slides:

2
23
92

🔍 Our KAIST Visual AI group is seeking undergraduate interns to join us this winter. Topics include generative models for visual data, diffusion models/flow-based models, LLMs/VLMs, 3D/geometry, neural rendering, AI for science, and more. 🌐 Web:

0
12
65
#DiffusionModels.Big thanks to @OPatashnik for the insightful guest lecture in our diffusion models course on using attention layers in diffusion networks for image manipulation. Don’t miss the recording!.🎥:
0
11
56
🔍Our KAIST Visual AI group is seeking undergraduate interns to join us this summer. Join us if you're interested in generative models for visual data, diffusion models, neural rendering, 3D/geometry, and more. Come be a part of our team!. 🌐 Webpage:

0
9
51
Last month, I presented our work on "Visual Content Generation with Image Diffusion Models" at Stanford and Adobe Research, showcasing diffusion synchronization for creating 3D textures, panoramic images, and ambiguous images. Check out the slides:

0
8
50
#NeurIPS2024 .DiT generates not only higher-quality images but also opens up new possibilities for improving training-free spatial grounding. Come visit @yuseungleee 's GrounDiT poster to see how it works. Fri 4:30 p.m. - 7:30 p.m. East #2510. 🌐

🇨🇦 Happy to present GrounDiT at #NeurIPS2024!. Find out how we can obtain **precise spatial control** in DiT-based image generation!. 📌 Poster: Fri 4:30PM - 7:30PM PST. 💻 Our code is also released at:

1
12
52
#NeurIPS2024.We introduce GrounDiT, a SotA training-free spatial grounding technique leveraging a unique property of DiT: sharing semantics in the joint denoising process. Discover how we **transplant** object patches to designated boxes. Great work by @yuseungleee and Taehoon.
🌟 Introducing GrounDiT, accepted to #NeurIPS2024!. "GrounDiT: Grounding Diffusion Transformers.via Noisy Patch Transplantation". We offer **precise** spatial control for DiT-based T2I generation. 📌 Paper: 📌 Project Page: [1/n]

1
3
46
ICCV 2023 trip was a lot of fun with the opportunity to visit UCL and Adobe Research Paris. Thank you, Niloy Mitra and Tamy Boubekeur, for hosting my visit. I gave a talk about shape editability and multi-view coherence in 3D Generation. Slides:

0
7
45
🌟 Recently, I had the wonderful opportunity to present at TUM, ETH, and École Polytechnique (online). My talk focused on our latest works in visual content generation using pretrained image diffusion models. Check out the slides here!. Slides:
2
11
42

#ICCV2023 Introduce SALAD 🥗 @ICCVConference, a 3D diffusion model that leverages a part-level implicit + explicit representation to achieve the best quality in 3D generation and enable multiple applications. @63_days, @USeungwoo0115, @hieuristics.🧵(1/N)

1
9
37
🌟 Check out our SyncTweedies code! We introduce a general diffusion synchronization approach that enables the generation of diverse visual content, such as panoramas and mesh textures, using a pretrained image diffusion model in a zero-shot manner. 🌐

🚀 Code for SyncTweedies is out!.Code: . SyncTweedies generates diverse visual content, including ambiguous images, panorama images, 3D mesh textures, and 3DGS textures. Joint work with @63_days @KyeongminYeo @MinhyukSung .
0
10
37
I presented at the 2nd Workshop on Compositional 3D Vision (C3DV) at CVPR 2024, where I introduced our recent work on 3D object compositionality. Check out the slides at the link below. Slides:

0
3
32
GLIGEN is good at generating layout-aligned images but often fails to reflect the text prompt accurately. Our ReGround approach shows that simply rewiring attention modules in the pre-trained GLIGEN can solve the problem. No training/finetuning required.
Improving layout-to-image #diffusion models with **no additional cost!**. ReGround: Improving Textual and Spatial Grounding at No Cost.📌 🖌️ We show that a simple **rewiring** of #attention modules can resolve the description omission issues in GLIGEN.
0
5
30
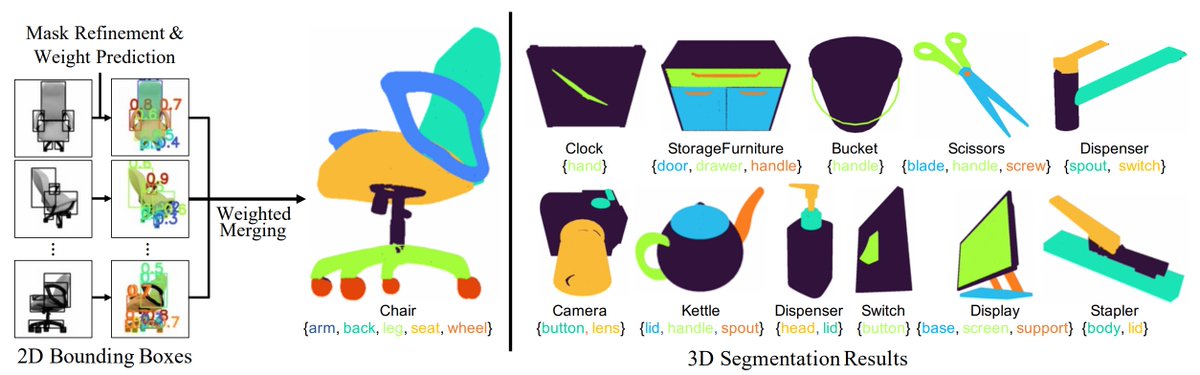
Our PartSTAD introduces the best way (so far) to leverage a 2D image segmentation network (SAM) for 3D part segmentation. If you're at ECCV, come check out our poster!. 📅 10/1 (Tue) 10:30 AM - 12:30 PM.📍 Poster #63.🔗

🎉I'm thrilled that my first-authored paper, “PartSTAD: 2D-to-3D Part Segmentation Task Adaptation”, will be presented at #ECCV2024!. If you are interested, come visit Poster #63 at the morning session tomorrow 10/1 (Tue) 10:30am-12:30pm!. Project Page:
1
7
32
Join us today (Wednesday) for our poster presentations at #NeurIPS2023! . 1. SyncDiffusion: Coherent Montage via Synchronized Joint Diffusions Morning 10:45 a.m., Room #532 . 2.FourierHandFlow: Neural 4D Hand Representation Using Fourier Query Flow Afternoon 5 p.m., Room #312

1
9
29
#ECCV2024 Check out ReGround to see how you can improve GLIGEN performance **for free** by simply rewiring the attention modules during inference. No training or fine-tuning needed. Work done by.@yuseungleee. Webpage: arXiv:
🥳ReGround is accepted to #ECCV2024!. 📌 Crucial text conditions are often dropped in layout-to-image generation. 🔑 We show a simple rewiring of attention modules in GLIGEN leads to improved prompt adherence!. Joint work w/ @MinhyukSung

0
3
31
#CVPR2023 Come to poster 054 and don't miss our 'Im2Hands' this afternoon at CVPR. We are excited to present the first-ever work on learning the neural implicit representation of two interacting hands. Web:

0
3
29
#NeurIPS2024.📣 Check out our SyncTweedies to see how to extend the zero-shot capability of StableDiffusion to generate panoramas, mesh/Gaussian splat textures, ambiguous images, and more! We propose a general framework for diffusion synchronization. 🌐
🎉 Excited to share that our work "SyncTweedies: A General Generative Framework Based on Synchronized Diffusions" has been accepted to NeurIPS 2024. Paper: Project page: Code: [1/8].#neurips2024 #NeurIPS
0
2
29
Check out our APAP, transforming the image diffusion model into a rectifier of implausible 3D deformations. We achieve the best synergy between optimization and score distillation sampling to produce more realistic mesh deformation. Project:
As-Plausible-As-Possible (APAP) is a shape deformation method that enables plausibility-aware mesh deformation and preservation of fine details of the original mesh offering an interface that alters geometry by directly displacing a handle along a direction. Paper:
1
6
27
Our SALAD🥗 is powering the text-to-3D service at.@3dpresso_ai by ReconLabs. Check out this webpage:. SALAD @ICCVConference.Project: arXiv: HuggingFace: #SALAD3D #3Dpresso #ICCV2023

0
4
25

@CSProfKGD Thank you for the shoutout to our course! We've covered diffusion models from the fundamentals to their applications. All lectures are now available at the link below:.🌐

New lecture series alert: Diffusion Models and Their Applications - Fall 2024 (with videos).

0
2
20
#NeurIPS2024.We'll be presenting SyncTweedies on Wednesday morning, a training-free diffusion synchronization technique that enables generation of various types of visual content using an image diffusion model. Wed, 11 a.m. - 2 p.m. PST.East #2605. 🌐
🚀 Excited to share that our work, SyncTweedies: A General Generative Framework Based on Synchronized Diffusions will be presented at NeurIPS 2024 🇨🇦! . 📌 If you are interested, visit our poster (#2605) 11 Dec 11AM — 2PM at East Exhibit Hall A-C.

0
4
18
#CVPR2023 Join our ‘ShapeTalk’ at poster 032 this afternoon. We introduce a new text-to-shape dataset containing 500k+ texts describing 3D shapes and demonstrate a text-driven shape editing application.

0
4
16
InterHandGen is the first diffusion model for generating two interacting hands🤲. It can also be leveraged to improve the reconstruction of two hands. Join our poster at #CVPR2024 on Wednesday. 📌 Poster #34.📅 Wed 10:30 a.m. - noon.🌐

🚨 InterHandGen (#CVPR2024) is one of the first works on the generative modeling of 🤲interacting two hands (with or without an additional object). This diffusion-based prior be incorporated into any existing method via SDS-like loss to boost the estimation accuracy!. (1/🧵)
0
5
16
At #ECCV2024, @yuseungleee Lee will present ReGround, a method to improve pretrained GLIGEN at no extra cost by simply reconnecting the attention modules. 📅 10/3 (Thu) 10:30 AM - 12:30 PM.📍 Poster #104.🔗
🌟 Excited to present our paper "ReGround: Improving Textual and Spatial Grounding at No Cost" at #ECCV2024!. 🗓️ Oct 3, Thu. 10:30 AM - 12:30 PM.⛳ Poster #104. ✔️ Website: ✔️ Slides: (from U&ME Workshop). Details in thread 🧵(1/N)
0
3
14
#NeurIPS2024.Thursday afternoon, don't miss @USeungwoo0115's poster on Neural Pose Representation, a framework for pose generation and transfer based on neural keypoint representation and Jacobian field decoding. Thu 4:30 p.m. - 7:30 p.m. East #2202. 🌐

🚀 Enjoying #NeurIPS2024 so far? . Don’t miss our poster session featuring the paper “Neural Pose Representation Learning for Generating and Transferring Non-Rigid Object Poses” tomorrow!. 📍 Poster Session: Thu, Dec 12, 4:30–7:30 PM PST, Booth #2202, East Hall A-C.

0
3
11
Posterior Distillation Sampling (PDS) takes a step further from Score Distillation Sampling (SDS), enabling "editing" of NeRFs, Gaussian splats, SVGs, and more. Join our poster at #CVPR2024 on Thursday morning. 📌 Poster #358.📅 Thu 10:30 a.m. - noon.🌐

What would be the best optimization method for editing NeRFs, 3D Gaussian Splats and SVGs using 2D diffusion models? 🤔. We present Posterior Distillation Sampling (PDS) at.#CVPR2024, a novel optimization method designed for diverse visual content editing. 1/N
0
3
12
Check out APAP (As-"Plausible"-As-Possible) at #CVPR2024, making mesh deformation outputs more visually plausible using image diffusion priors. Join our poster on Wednesday morning. 📌 Poster #403.📅 Wed 10:30 a.m. - noon.🌐
Can 2D diffusion priors improve the "visual" quality of mesh deformation?🤔. In our #CVPR2024 paper “As-Plausible-As-Possible: Plausibility-Aware Mesh Deformation Using 2D Diffusion Priors”, we employ the SDS loss as a deformation energy for plausible deformations. 1/N
0
3
12
📸 Looking to create stunning panoramic images? Check out SyncDiffusion, generating coherent and seamless panorama images by synchronizing joint running of StableDiffusion. Project: arXiv:
0
2
10
Kudos to Juil Koo ( for passing his MS thesis defense! His thesis is titled "Learning 3D Object Decomposition via. Natural Language Descriptions", which is based on his CVPR 2022 Oral paper, PartGlot (. Check this out!


0
0
8
🚀 Happening in 3 minutes at Bluebird 3A at SIGGRAPH! Join us if you are interested in diffusion models and their applications in graphics and vision.

Come join us at our course "Diffusion Models for Visual Content Generation" at 2 PM today at #SIGGRAPH2024 with an excellent set of contributors including Niloy Mitra, @MinhyukSung, Paul Guerrero, @DanielCohenOr1, @paulchhuang and @OPatashnik !.
0
0
6
In our paper, please check out the details and the best performance of our SyncTweedies in various applications. Web: arXiv: This is a work done by our very own members in our team: @KimJaihoon, @63_days, @KyeongminYeo.
0
1
5
It is a versatile framework applicable to various applications, including ambiguous image generation, 360° image generation, 3D model texture generation, and more. We’ve observed that previous works have explored different versions of synchronization for each case. Our results👇

1
0
5
Co-first-authored by three students in our group:.@63_days, @USeungwoo0115, @hieuristics. It’s the first for our undergrad students @USeungwoo0115 and @hieuristics to publish a paper. Congrats!.(8/8).
0
0
3
#CVPR2022.Check out our three papers at CVPR 2022!. Point2Cyl (Scan-to-CAD).Jun 23 (Thu) Morning. Poster 120a. PartGlot (Language-to-3D).Jun 24 (Fri) Morning. Oral 4.1.3 (Hall B1). Poster 49a. Pop-Out Motion (3D-aware image manipulation).Jun 24 (Fri) Morning. Poster 246a.
0
1
4
#CVPR 2022 (1/3).*Language-to-3D*.Our PartGlot shows how 3D part segmentation can be learned without any supervision but referential language for the entire shape and an attention module. arXiv: (CVPR 2022 Oral).
0
1
3
Diffusion synchronization has been explored to generate various outputs using pretrained image diffusion models. Our SyncDiffusion ( is one such example, generating panorama images by running reverse diffusion across multiple small patches.

1
1
2
The workshop I'm co-organizing at #ICCV2021 has a great lineup of speakers who will talk about 3D & structure!.
0
1
2
#ICCV 2021 (1/2) Session 6. CPFN: Cascaded Primitive Fitting Networks for High-Resolution Point Cloud. We propose a cascaded network to handle high-res 3D point clouds in the primitive fitting problem. webpage: arXiv:
1
0
2
We’ve examined 60 potential scenarios of synchronization and identified that the best is the one that had not been explored before! – Averaging the outputs of Tweedie’s formula in the canonical space while performing reverse diffusion in instance spaces. We named it SyncTweedies.

1
0
2
# ICCV 2021 (2/2) Session 12. We show how Transformers can be more effectively used when predicting camera intrinsic parameters from a single image. CTRL-C: Camera calibration TRansformer with Line-Classification. arXiv: code:
1
0
2
Also, our diffusion model can be extended to include a text condition as an additional input, enabling text-guided generation and text-guided part editing. (7/N)

1
0
0