

Michael Oberst
@MichaelOberst
Followers
2K
Following
5K
Media
19
Statuses
244
Assistant Professor of CS at @JohnsHopkins, Part-time Visiting Scientist @AbridgeHQ. Previously: Postdoc at @CarnegieMellon. PhD from @MIT_CSAIL.
Cambridge, MA
Joined August 2011
RT @niloofar_mire: 🧵 Academic job market season is almost here! There's so much rarely discussed—nutrition, mental and physical health, unc….
0
38
0
For more details, see the paper / poster!. And if you're at UAI, check out the talk and poster today! Jacob (not on social media) and I are around at UAI, so reach out if you're interested in chatting more!. Paper: Poster:
0
0
1
These findings are also relevant for the design of new trials!. For instance, deploying *multiple models* in a trial has two benefits: (1) it allows us to construct tighter bounds for new models, and (2) it allows us to test whether these assumptions hold in practice.
1
0
2
We make some other mild assumptions, which can be falsified using existing RCT data. For instance, if two models have the *same* output on a given patient, then we assume outcomes are at least as good under the model with higher performance.
1
0
0
To capture these challenges, we assume that model impact is mediated by both the output of the model (A), and the performance characteristics (M). This formalism allows us to start reasoning about the impact of new models with different outputs and performance characteristics.

1
0
0
The second challenge is trust: Impact depends on the actions of human decision-makers, and those decision-makers may treat two models differently based on their performance characteristics (e.g., if a model produces a lot of false alarms, clinicians may ignore the outputs).
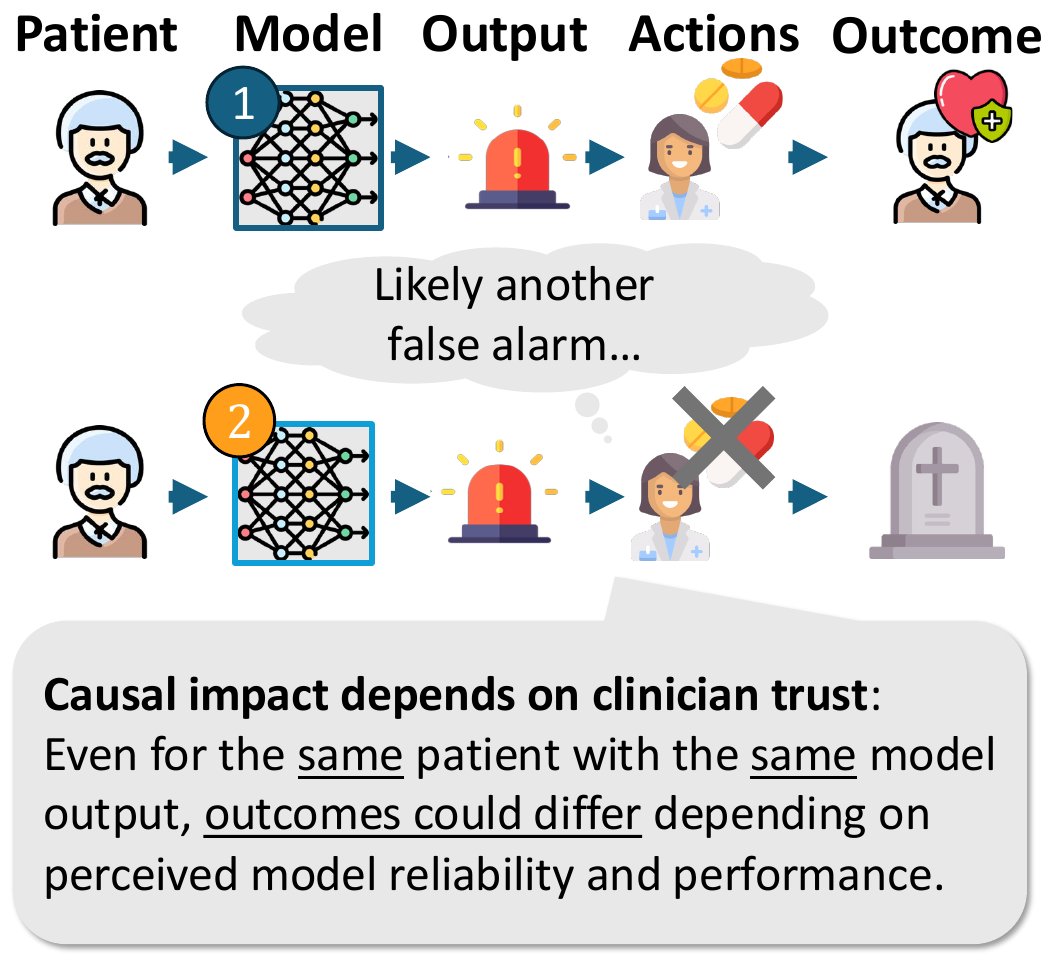
1
0
0
We tackle two non-standard challenges that arise in this setting, *coverage* and *trust*. The first challenge is coverage: If the new model is very different from previous models, it may produce outputs (for specific types of inputs) that were never observed in the trial.

1
0
0
We develop a method for placing bounds on the impact of a *new* ML model, by re-using data from an RCT that did not include the model. These bounds require some mild assumptions, but those assumptions can be tested in practice using RCT data that includes multiple models.
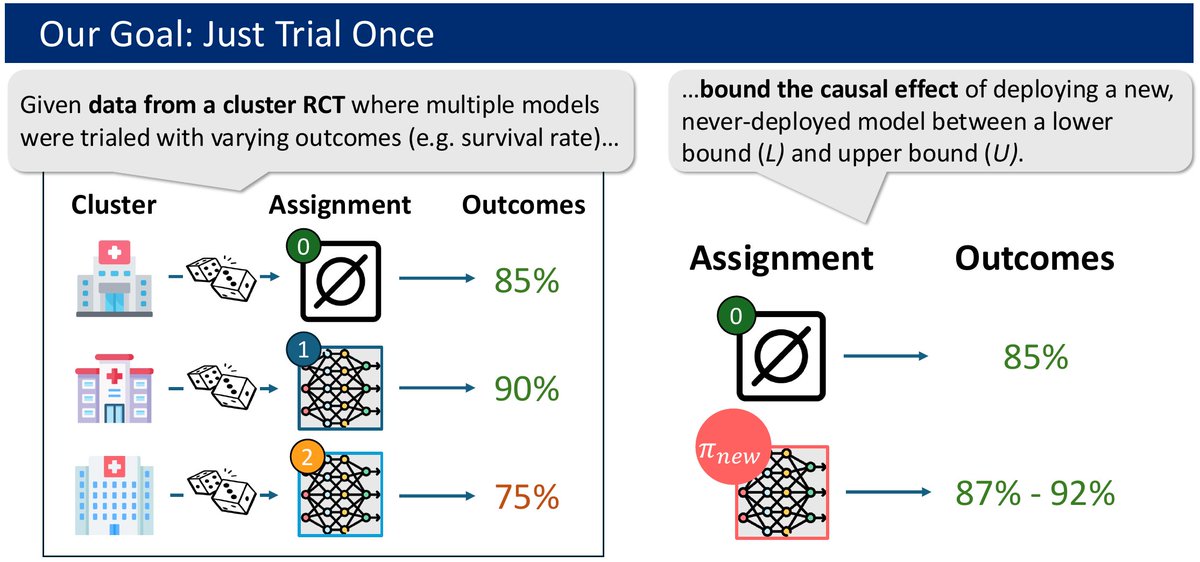
1
0
0
Randomized trials (RCTs) help evaluate if deploying AI/ML systems actually improves outcomes (e.g., increases survival rates in a healthcare context). But AI/ML models can change: Do we need a new RCT every time we update the model? Not necessarily, as we show in our UAI paper!

1
3
25
RT @MonicaNAgrawal: Excited to be here at #ICML2025 to present our paper on 'pragmatic misalignment' in (deployed!) RAG systems: narrowly "….
0
7
0
RT @matthewherper: Layoffs hit FDA’s Center for Devices and Radiological Health

statnews.com
Layoffs at the FDA appear to have hit the AI and digital health staff particularly hard. It also has a strained relationship with Musk’s company Neuralink.
0
7
0
An example of some recent work (my first last-author paper!) on rigorous re-evaluation of popular approaches to adapt LLMs and VLMs to the medical domain.

🧵 Are "medical" LLMs/VLMs *adapted* from general-domain models, always better at answering medical questions than the original models?. In our oral presentation at #EMNLP2024 today (2:30pm in Tuttle), we'll show that surprisingly, the answer is "no".
0
0
7
Application Link: More information on my website:
michaelkoberst.com
Computer Science, Statistics, Causality, and Healthcare
1
0
7
I'm recruiting PhD students for Fall 2025! CS PhD Deadline: Dec. 15th. I work on safe/reliable ML and causal inference, motivated by healthcare applications. Beyond myself, Johns Hopkins has a rich community of folks doing similar work! Come join us!

8
125
433
RT @danielpjeong: 🧵 Are "medical" LLMs/VLMs *adapted* from general-domain models, always better at answering medical questions than the ori….

arxiv.org
Several recent works seek to develop foundation models specifically for medical applications, adapting general-purpose large language models (LLMs) and vision-language models (VLMs) via continued...
0
36
0
RT @yisongyue: Just updated my Tips for CS Faculty Applications. Best of luck to everyone applying!.

yisongyue.medium.com
This article is a collection of tips for improving your faculty application package (tailored to computer science). Most of the time…
0
72
0
RT @mdredze: The early 🦜 gets the 🪱. @JHUCompSci has a great opportunity for faculty hiring. Apply early and you couls interview early and….
0
18
0
RT @anjalie_f: As application season rolls around again, here's your reminder that materials from my successful applications are available….
0
156
0
RT @mdredze: 🚨 Johns Hopkins @JHUCompSci is hiring faculty at all ranks! 1) Data Science and AI 🤖; 2) All other areas of CS 💻. We will doub….
0
45
0
RT @DanielKhashabi: Computer Science @ JHU is hiring in ALL areas:. 🔑 Apply early for flexible scheduling + potenti….
0
17
0