
Chenhao Zheng
@Michael3014018
Followers
75
Following
22
Media
10
Statuses
20
Computer Vision PhD student @uwcse | Student Reseacher @allen_ai | ex Undergrad @UMichCSE and @sjtu1896
Seattle, WA
Joined December 2022
Having trouble dealing with the excessive token number when processing a video? Check out our paper that is accepted by ICCV 2025 with an average score of 5.5! We tokenize video with tokens grounded in trajectories of all objects rather than fix-sized patches. Trained with a

1
25
112
Extremely grateful to work with the amazing team!!.@JieyuZhang20, @mrezasal1, Ziqi Gao, Vishnu Iyengar, Norimasa Kobori, Quan Kong, @RanjayKrishna.
1
0
2
We also connect TrajViT and ViT3D to Llama-3, forming two VideoLLMs. Across six Video-QA benchmarks, TrajViT-LLM delivers +5.24 pp accuracy, trains 4 × faster* and requires 18 × fewer inference FLOPs than the ViT3D counterpart. We also demonstrate in the paper that our model has.
1
0
2
For efficiency,despite the cost of trajectory extraction, TrajViT trains faster, consumes less GPU memory, and performs quicker inference for sequences ≥ 64 frames.

1
0
3
For evaluation, we compare it with standard ViT with space-time patch tokens (ViT3D) and state-of-the-art token merging methods. Task scope: video-text retrieval, spatiotemporal detection, action classification, and VideoLLM QA. TrajViT surpasses ViT3D on all tasks. At our
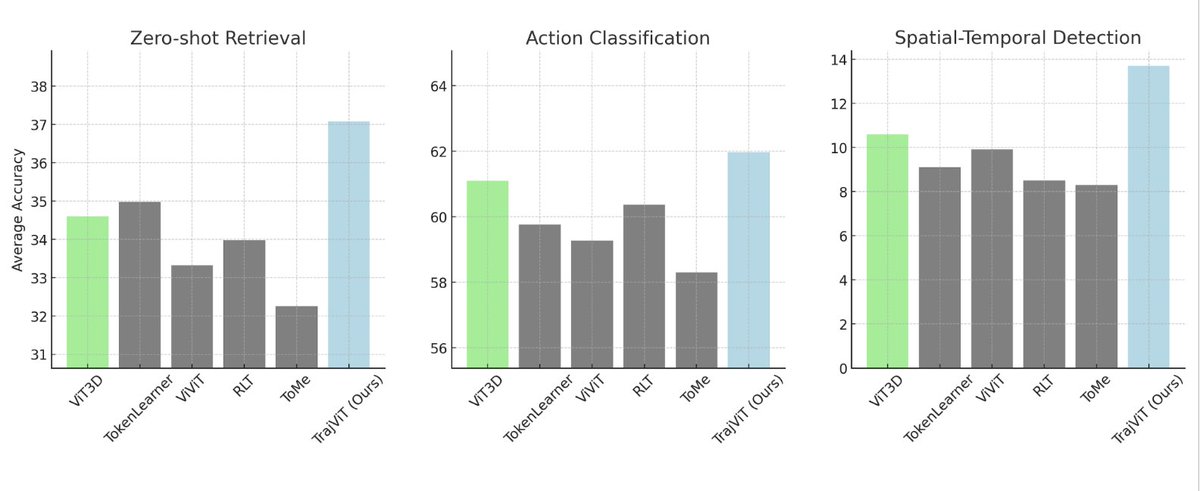
1
0
3
We train a video encoder, TrajViT, using our tokenization paradigm with CLIP objective, on a large scale dataset of 50M image + 10M video. TrajViT can naturally process image data by treating each image segment as a trajectory of length one, allowing seamingless joint training.
1
0
2
Naively splitting the video tensor into patches is known to introduce memory bottleneck, but is still the de-facto way of tokenizing video due to its strong performance. As shown in figure, We fundamentally transform traditional video tokenization by reorganizing video tokens to

1
0
2
RT @jae_sung_park96: 🔥We are excited to present our work Synthetic Visual Genome (SVG) at #CVPR25 tomorrow! .🕸️ Dense scene graph with d….
0
8
0
RT @JieyuZhang20: Calling all #CVPR2025 attendees!. Join us at the SynData4CV Workshop at @CVPR (Jun 11 full day at Grand C2, starting at 9….
syndata4cv.github.io
[“CVPR 2025 Workshop”, “June 11th, 2025, Grand C2”, “Nashville, TN, United States”]
0
8
0
RT @ainaz_eftekhar: 🎉 Excited to introduce "The One RING: a Robotic Indoor Navigation Generalist" – our latest work on achieving cross-embo….
0
36
0
RT @jbhuang0604: The slide is bad, her response to an audience is even worse…. “Maybe there is one, maybe they are common, who knows what.….
0
20
0
This project is led by @zitong_lan , with collaboration of @zhiwei_zzz, and advised by @mingmin_zhao . Thank for everyone’s great efforts!.
0
0
0
In parallel with AVR, we develop AcoustiX, an acoustic simulation platform that generates more physically accurate signals compared to simulators like soundspace. Soundspace exhibits significant errors in signal phases and arrival times, so we develop a version to solve these.
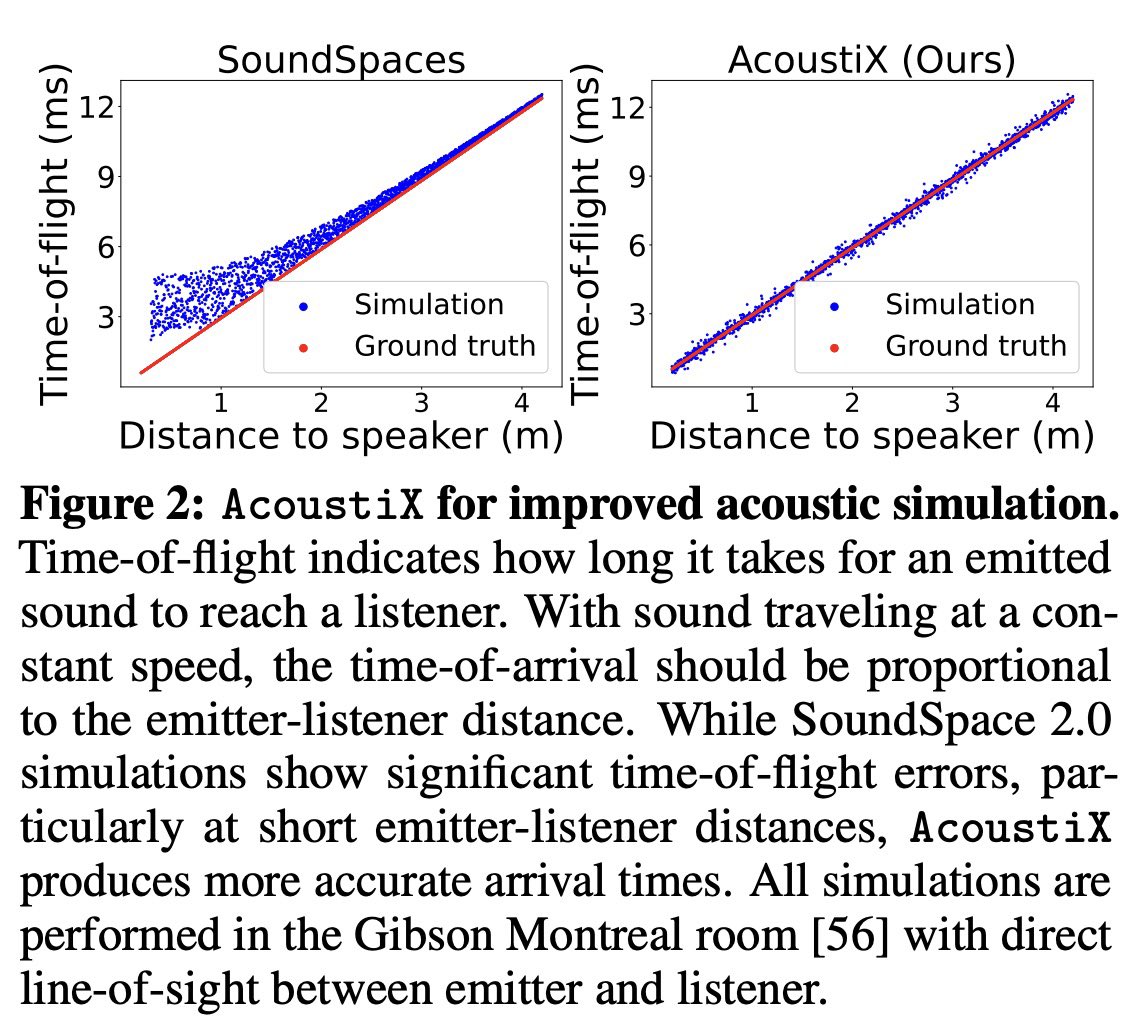
1
0
0
One cool thing: we can generate accurate binaural audio despite being trained only on monaural audio. The existing methods either require training in domain or manually creates signal delays. For us, rendering impulse response at the pos of two ears separately is good enough.
1
0
0
The resulting method surpass the previous state-of-the-art model in a large margin, both in real and simulated benchmarks. Below is the evaluation in a set of real world benchmarks. More results in paper.


1
0
0
In this paper, we for the first time successfully introduce volumetric rendering in audio synthesis. We propose various techniques to solve the challenges mentioned above, by closely follow acoustic wave principle. See our paper for detail.

1
0
0
One may ask, why can’t apply the same NERF techniques for audio? The challenge is sound and light have quite different properties: microphone-captured sound lacks directionality; propagation time of sound can’t be ignored, so different location has different signal delays; etc….
1
0
0
In 3D vision community, novel view synthesis has advanced a lot since NERF comes out. However, people in audio field still struggles to apply similar physics prior in spatial audio synthesis. The figure below shows how prev models except us fails to model the field distribution.

1
0
0
Excited to share our #NeurIPS2024 spotlight: Acoustic Volume Rendering (AVR) for Neural Impulse Response Fields. AVR greatly improve the state-of-the-art in novel view spatial audio synthesis by introducing acoustic volume rendering. Listen with headphone for example below
1
6
17
RT @DJiafei: Humans learn and improve from failures. Similarly, foundation models adapt based on human feedback. Can we leverage this failu….
0
43
0