

KwaiAICoder
@KwaiAICoder
Followers
132
Following
11
Media
26
Statuses
30
Kwaipilot team, illuminating the world with AI and building dreams with code. The official account of the Kwaipilot team (Kuaishou's Large Model for coding).
Joined August 2024
Performance on SWE-bench-verified benchmark, trained with SeamlessFlow framework

0
0
0



⚡ SeamlessFlow’s secret weapon #2:Tag Driven Scheduling Paradigm. We propose a tag driven scheduling paradigm that abstracts hardware into capability tagged resources, unifying colocated and disaggregated architectures. Based on this, SeamlessFlow introduces a spatiotemporal

1
0
0
💡 SeamlessFlow’s secret weapon #1: Introduce A Data Plane. The data plane can decouple the RL trainer from diverse, complex agent implementations while sustaining high throughput. A central trajectory manager maintains complete interaction histories and supports partial

1
0
1
🔥 Introduce 「SeamlessFlow」, a server based reinforcement learning (RL) framework that eliminates pipeline bubbles by spatiotemporal multiplexing, achieving a 100% improvement in token throughput, and a 62% reduction in overall training time. 🚀 Paper:

arxiv.org
We introduce SeamlessFlow, a server based reinforcement learning (RL) framework that addresses two core challenges in industrial scale RL: (1) decoupling RL training from the complex execution...
1
0
1
🚀 Excited to introduce KAT-V1 (Kwaipilot-AutoThink) – a breakthrough 40B large language model from the Kwaipilot team!. KAT-V1 dynamically switches between reasoning and non-reasoning modes to address the “overthinking” problem in complex reasoning tasks. Key Highlights:.📌 40B

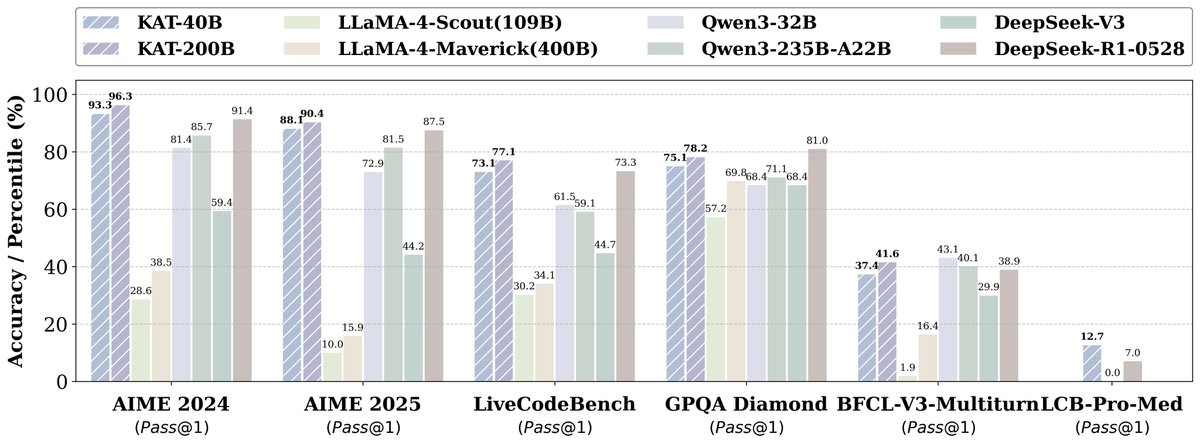
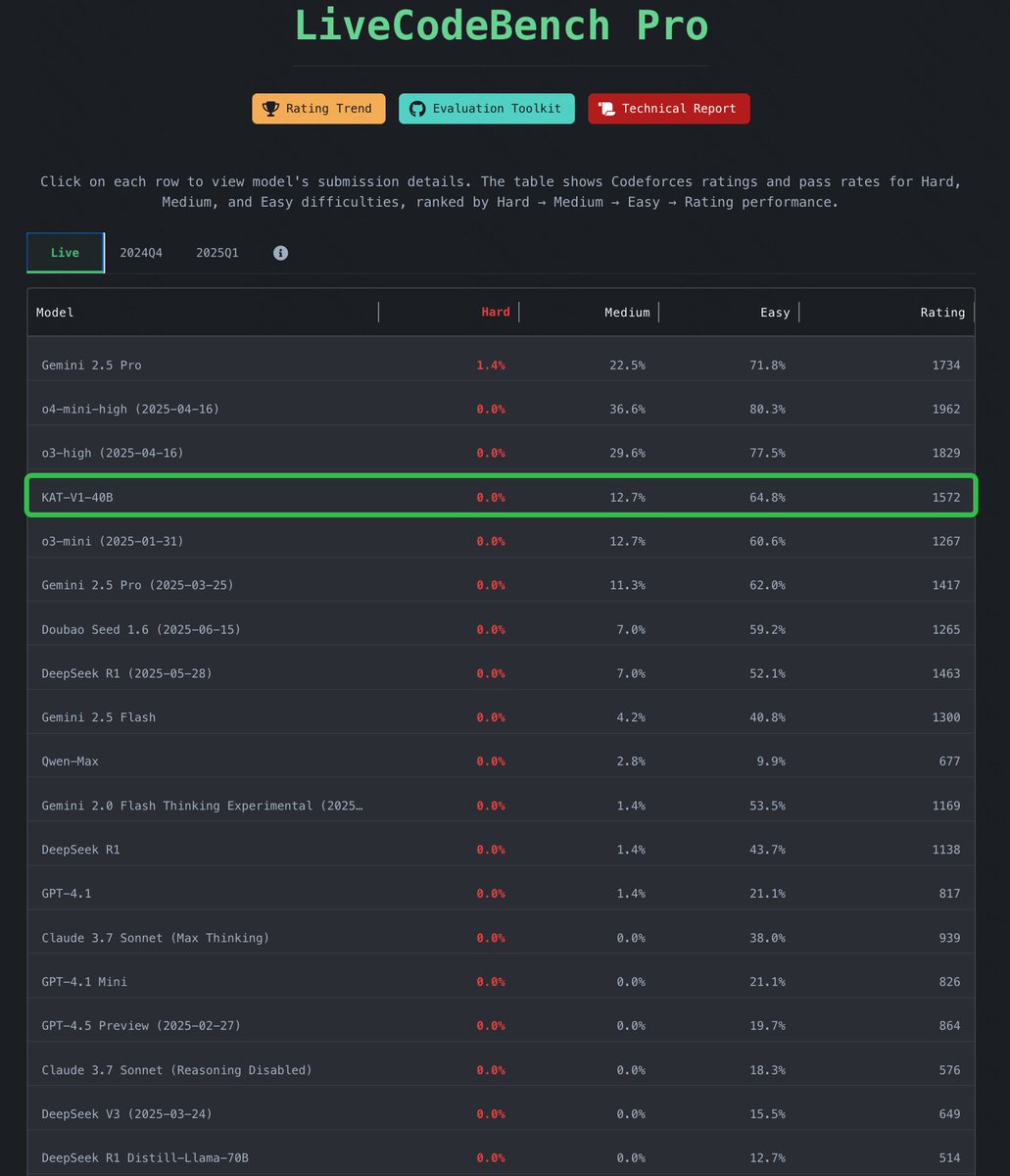
4
20
92
3/🚀.Testing with a fun challenge:. 1️⃣ We revisited the classic "bouncing ball" problem — a favorite for testing physics simulations. Prompt:"write a Python program that shows a ball bouncing inside a spinning hexagon. The ball should be affected by gravity and friction, and it
0
0
1
2/🚀 .Showing real gains in task-solving capability. Our model Tackles over 600K lines of Kuaishou's core backend code, and delivers breakthrough performance in:.1️⃣ Analyzing ultra-large-scale real-world codebases (45+ modules).2️⃣ Achieving end-to-end module identification.3️⃣.
1
0
1
1/🚀.Introducing KwaiCoder-AutoThink-preview. 🧠 Dynamically switches thinking modes — deep reasoning for hard problems, instant answers for simple ones.⚡ + 20pts on code/math benchmarks with auto-switch thinking.🪄 Trained with 1/30 cost via distillation + MTP . 👇 Try it:.🤗

1
1
4
⚙️ How it works. SRPO introduces three key innovations:.1. Two-stage training paradigm: addresses the challenge of the intrinsic response-length conflict between math and code.2. History resampling: improves training efficiency and enhances the quality of gradient signals.3. A.
0
1
2
🧠 Why it matters. SRPO is the first pure RL algorithm that fully reproduces and surpasses DeepSeek’s performance on both math and code tasks, while previous works have only focused on math area (ORZ, DAPO, VAPO etc). Performance of SRPO:.• AIME24: 50.0 pass@1.• LiveCodeBench:

0
1
2
🚀 Introducing SRPO . - Performance surpasses DeepSeek-R1-Zero-32B on AIME24 & LiveCodeBench.- Using only about 1/10 of the training steps.- Fully open-source model & technical report. 👇 Dive in for details:.📄 Paper: 🧬 Model:

2
0
1
🌟 Introducing KwaiCoder-23BA4-v1. 🚀 23B-wide MoE architecture code completion model.💰Trained at 1/30 of the cost compared to traditional methods.🏆 Achieves SOTA performance on multiple code-related evaluation datasets. 🔗 Check out the details:
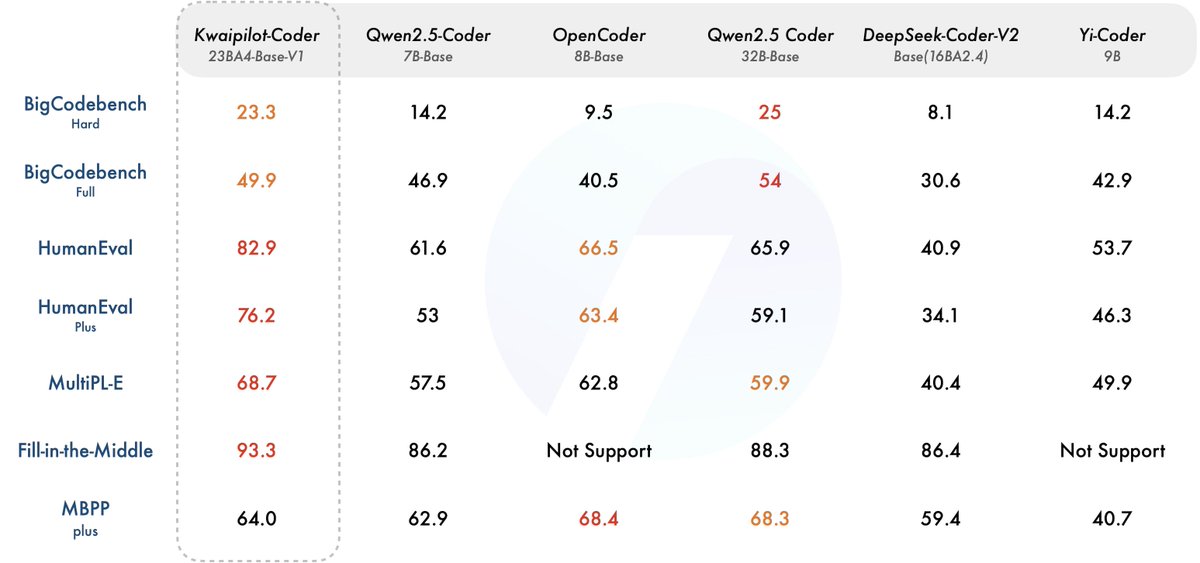
1
0
1
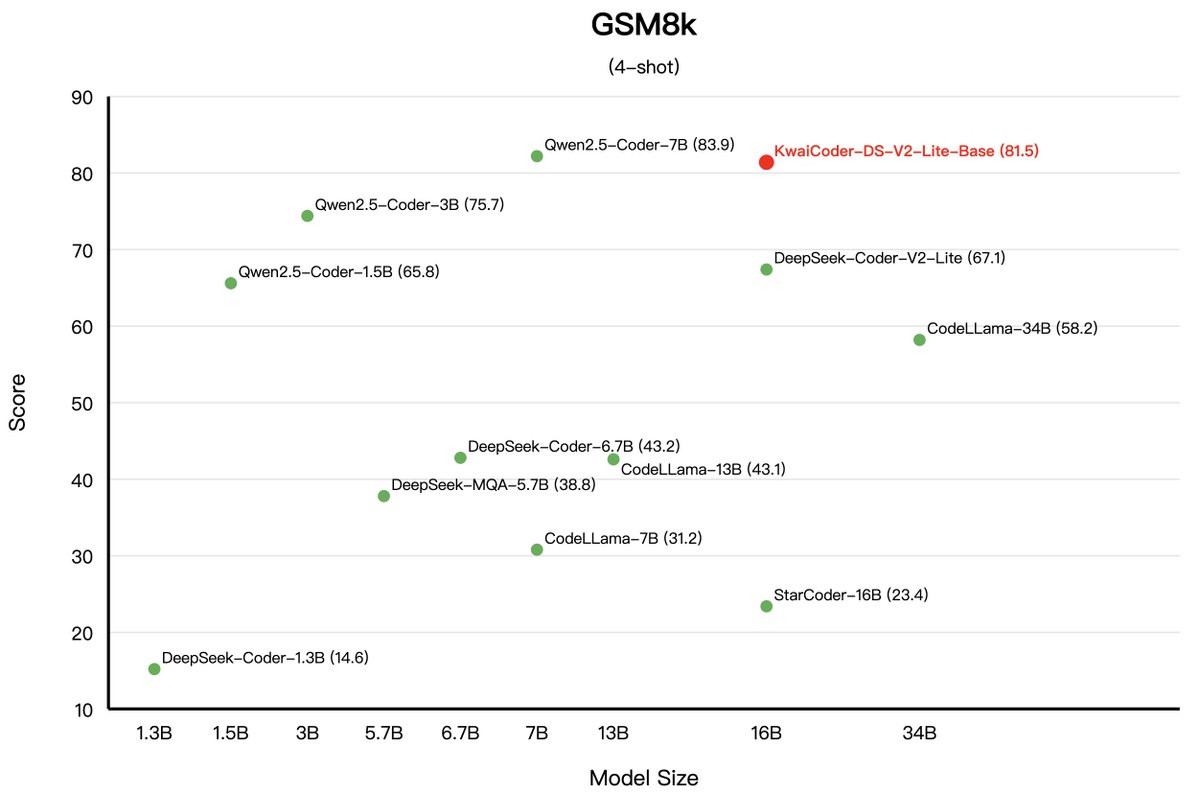
Model Performance for Kwai-Coder-DS-V2-Lite-Base!(4/4). 「MATH and GSM8K test sets」.🧮 Surpassed Deepseek-v2-Lite-Base with improvements of 3.79% and 21.46% respectively.📙 Outperformed CodeLlama-34B with substantial improvements of 90.95% and 40.03% respectively.🔥 Surpassed
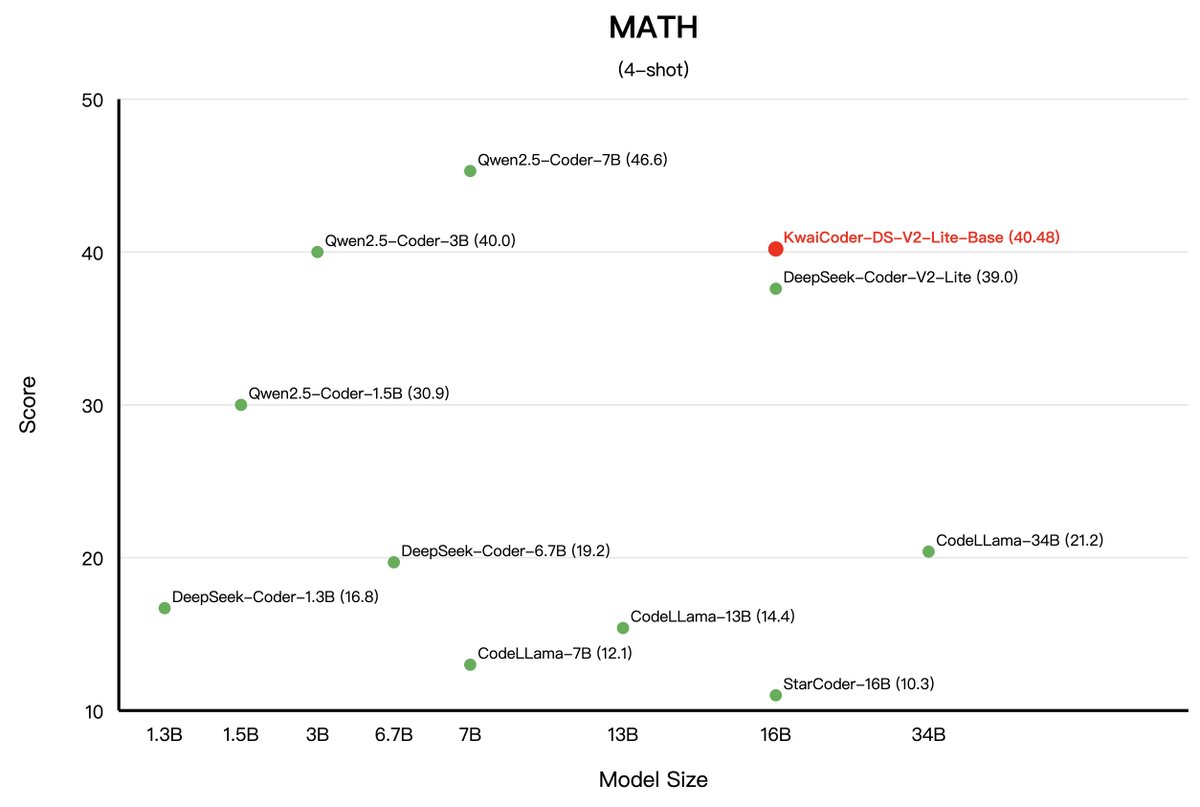
0
0
1
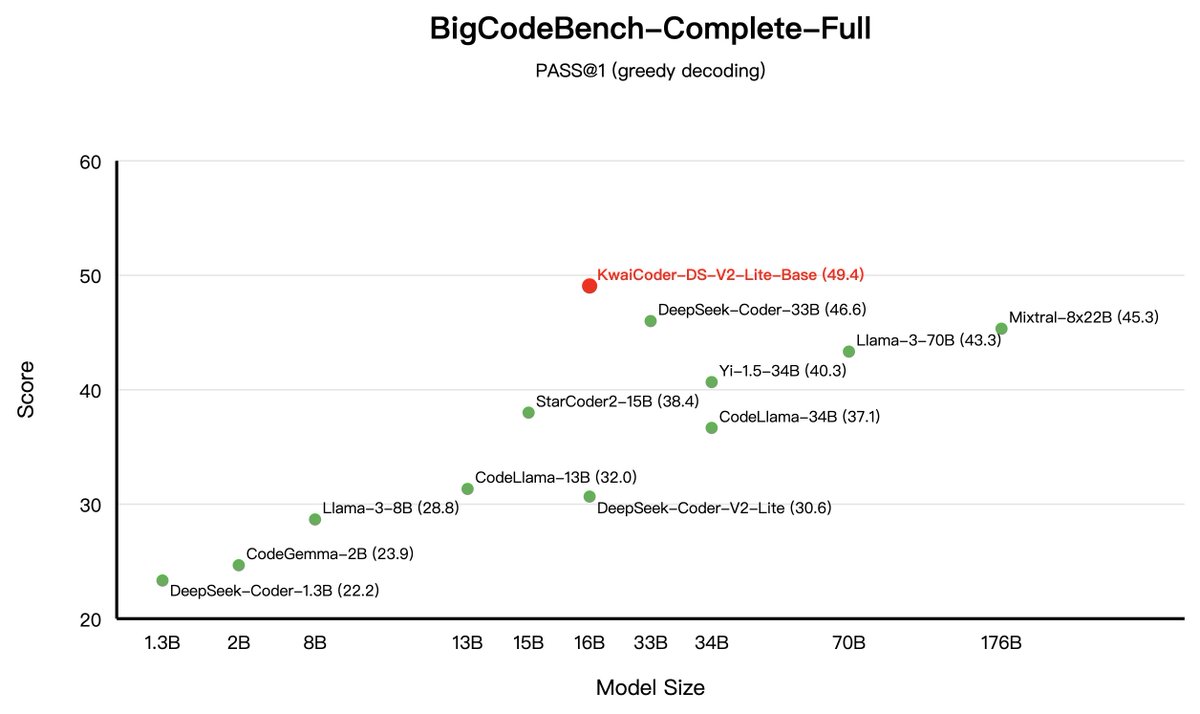
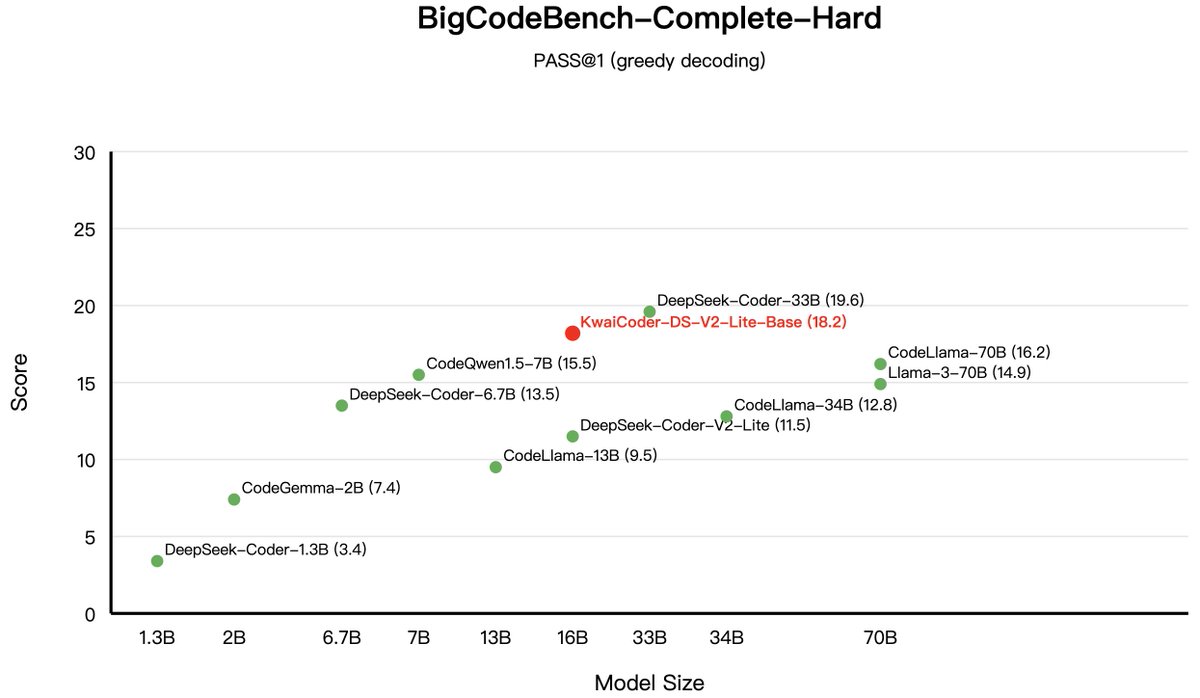
Performance for Kwai-Coder-DS-V2-Lite-Base!(3/4). 「BigCodeBench-Complete-Full Set」.🚀 Achieved a 6% improvement over DeepSeek-Coder-33B, reaching SOTA levels. 「BigCodeBench-Complete-Hard Set」.🔥 Significantly outperformed the CodeLlama-70B and the Qwen2.5-Coder-7B. 🔗
0
0
0
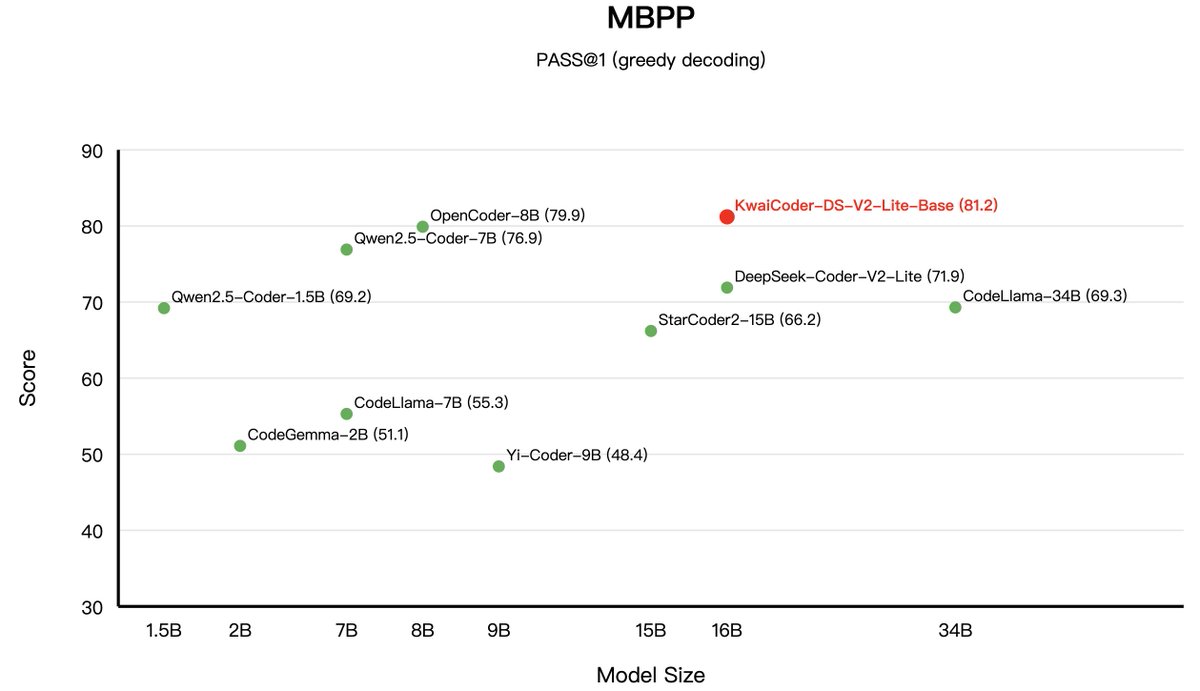
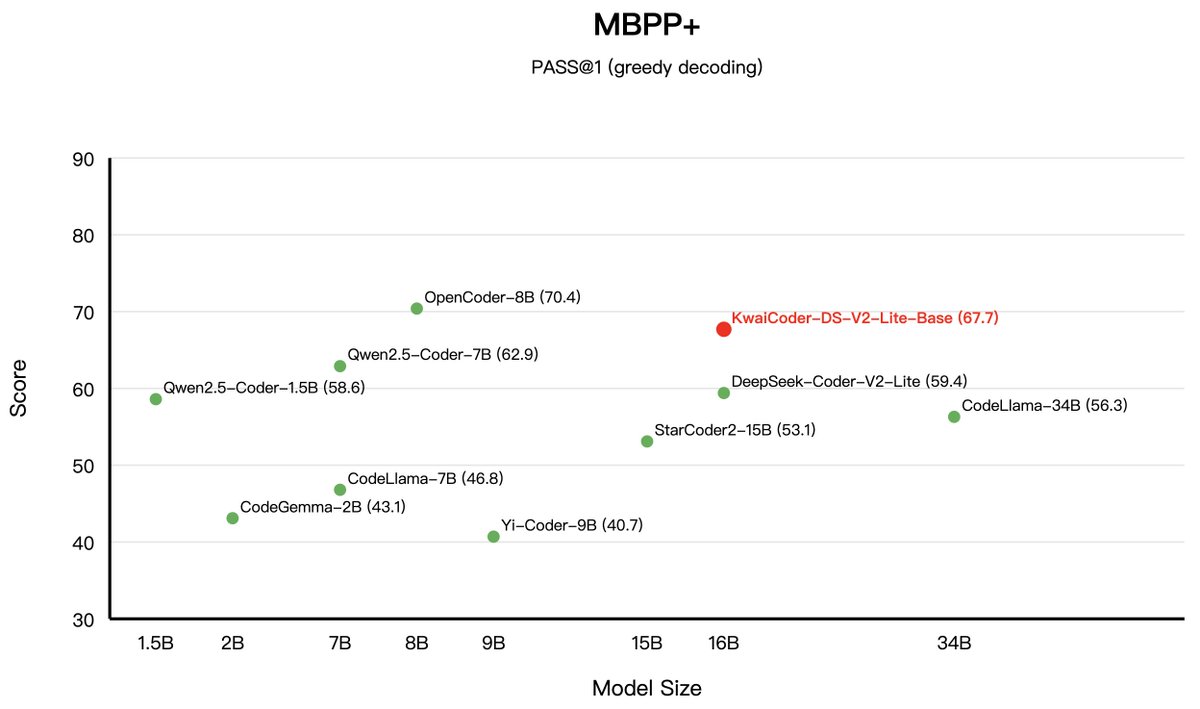
Performance for Kwai-Coder-DS-V2-Lite-Base!(2/4). 「MBPP and MBPP+ Test Sets」.🌟 Outperformed Deepseek-v2-Lite-Base.📈 Achieved an average improvement of nearly 5 percentage points over Qwen2.5-Coder-7B. 🔗 Model:
0
0
0