
Ji-Ha
@Ji_Ha_Kim
Followers
3K
Following
12K
Media
168
Statuses
5K
Joined January 2024

@stupdi_didot I forgot to add that r+eps, sqrt(r^2+eps^2) and max(r,eps) correspond to the ell1, ell2 and ell-infinity norm of the 2D vector (r,eps) respectively. Perhaps this could help with analysis or creating new ideas.
0
0
3
@stupdi_didot This is a very interesting alternative, v/max(r,eps). The Jacobian is still bounded, scale-free is preserved for eps>r, the only concern is that it is non-differentiable at r=eps, but you can use subgradients.

@Ji_Ha_Kim don’t forget about max(v, eps). I’m still not sure why we’re never doing this.
2
0
19
@stupdi_didot In short:.Use unbiased normalization if no backprop (e.g. optimizers) to preserve scale-free property.Use biased normalization with epsilon inside sqrt if differentiating (e.g. layer/batch-normalization) for numerical stability+simple implementation.Avoid epsilon outside sqrt.
2
1
16
@stupdi_didot Therefore, with the common ε_in^2=ε_out parameterization, the in(v|ε^2) normalization will be more numerically stable than out(v|ε) in the gradient

1
0
6
I'll clarify a point on in vs out.As noted by @stupdi_didot:. ||in(v|ε^2)||_2/√2 <= ||out(v|ε)||_2 <= ||in(v|ε^2)||_2. So with typical ε_in^2=ε_out.We see out(v|ε) shrinks more aggressively close to 0 than in(v|ε^2) (as seen in the vector field).


@Ji_Ha_Kim @bremen79 Is in(v|eps^2) not allowed?.If it is, then the following holds:.sqrt(2) sqrt(1+eps^2/||v||_2^2) >= 1+eps/||v||_2 >= sqrt(1+eps^2/||v||_2^2). I'm not familiar with how this ties into ML, but adding eps in the denom is decent for managing some numerical overflows.
1
0
9
My personal conclusion is the following: No differentiation (e.g. optimizers), use dir for scale-free property In layer/batch normalization, as you need to backpropagate + numerical stability, use in (+ simpler implementation).
1
0
6
(To implement on GPU, in is well-behaved with no branching even for its derivative, while dir and derivative of out will need a mask.).
1
0
8
As you can see, the Jacobian of dir(v) has unbounded operator norm as ||v||_2 goes to 0, so you shouldn't be using it if you need to take derivatives

1
0
10
For v≈0 much smaller than epsilon (v<<ε), in(v) behaves approximately like r/sqrt(ε), while out(v) behaves approximately like r/ε. So here is a "fair comparison" of vector fields out(v|0.2) vs in(v|0.4)

1
0
15
Here is a summary table of in(v) vs out(v). Note that out grows faster for r near 0.

1
0
19
However, all norms proportional to the L2 norm on R^n are rotationally invariant. In fact, these are the only norms that satisfy this property. So this includes the RMS norm ||v||_2/sqrt(dim v). (see bonus at the end).
1
0
15
Notice that dir(v) is scale-free (positively homogeneous of degree 0), i.e. dir(cv)=dir(v) for any c>0 since a norm is positively homogeneous. This no longer holds for in(v|ε) or out(v|ε) for non-zero ε.

1
0
16
Let's define the following for convenience. dir(v)=0 at v=0 else v/||v||_2. Position of epsilon: inside square root for in(v), outside for out(v).

1
0
15
Note that the subdifferential (subgradient) of the Euclidean norm is set-valued at the origin. However, if we pick the zero vector at the origin, then we recover a generalization of the sign function, a direction function "dir(v)".

1
1
26
What are the effects of adding epsilon in the denominator in L2 normalization?.Typically, we say it's for numerical stability. But which choice to make and when?
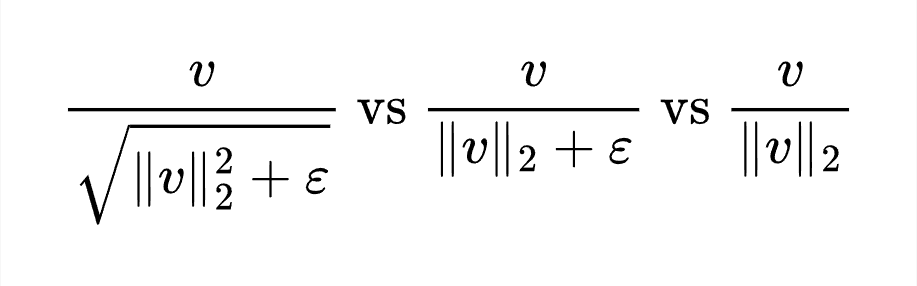
5
29
431
In Muon, during dualization, we normalize the gradient matrix entrywise by the Frobenius norm to bound the spectral norm and ensure convergence. Have we compared the performance versus the geometric mean of the matrix norms induced by 1 and infinity vector norms (or the minimum)?

3
6
107
For anyone accessing this now, I have split the post into two parts as it was quite lengthy, so there is a new URL:.
1
1
18

Linear Algebra - A Geometric Crash Course. I am writing this crash course in my blog site in preparation for a blog series. I would appreciate your feedback on the format, e.g. the use of colored boxes, if you like it or prefer to use it more sparsely.

9
51
435