

Hao Sun - RL
@HolarisSun
Followers
890
Following
537
Media
36
Statuses
166
4th year PhD Student at @Cambridge_Uni. IRL x LLMs. Superhuman Intelligence needs RL, and LLMs help human to learn from machine intelligence.
Cambridge, UK
Joined October 2022
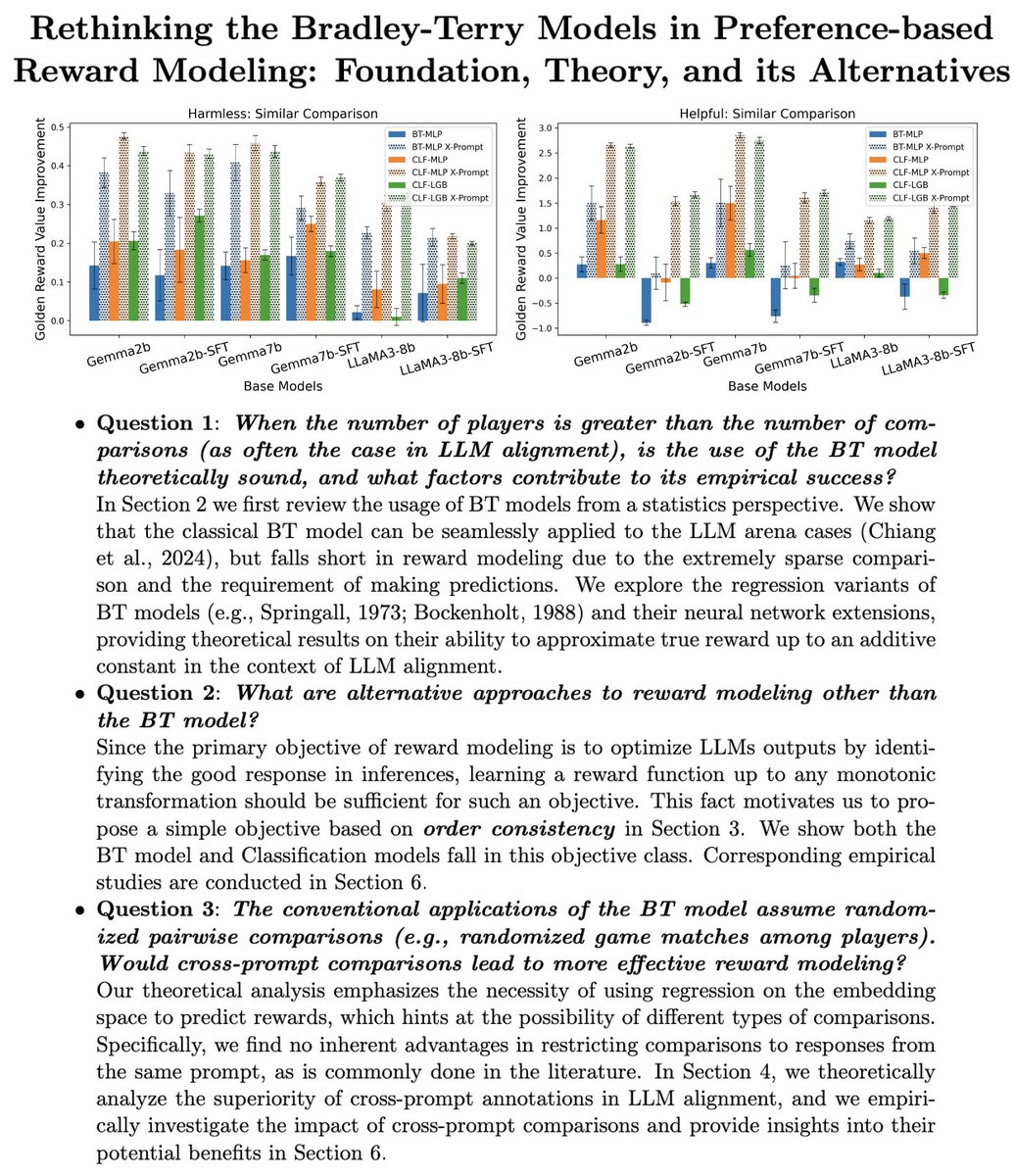
I have been working on Reward Modeling (and Inverse RL) for LLMs for the past 1.5 years. We built reward models (RMs) for prompting, dense RMs to improve credit assignment, and RMs from the SFT data. However, many questions remained unclear to me until this paper was finished.🧵
2
30
204
🚀 RL is powering breakthroughs in LLM alignment, reasoning, and agentic apps. Are you ready to dive into the RL x LLM frontier?. Join us at @aclmeeting ACL’25 tutorial:.Inverse RL Meets LLM Alignment .this Sunday at Vienna🇦🇹(Jul 27th, 9am). 📄 Preprint at

huggingface.co
0
12
67

This is SCIENCE🚀!!!.

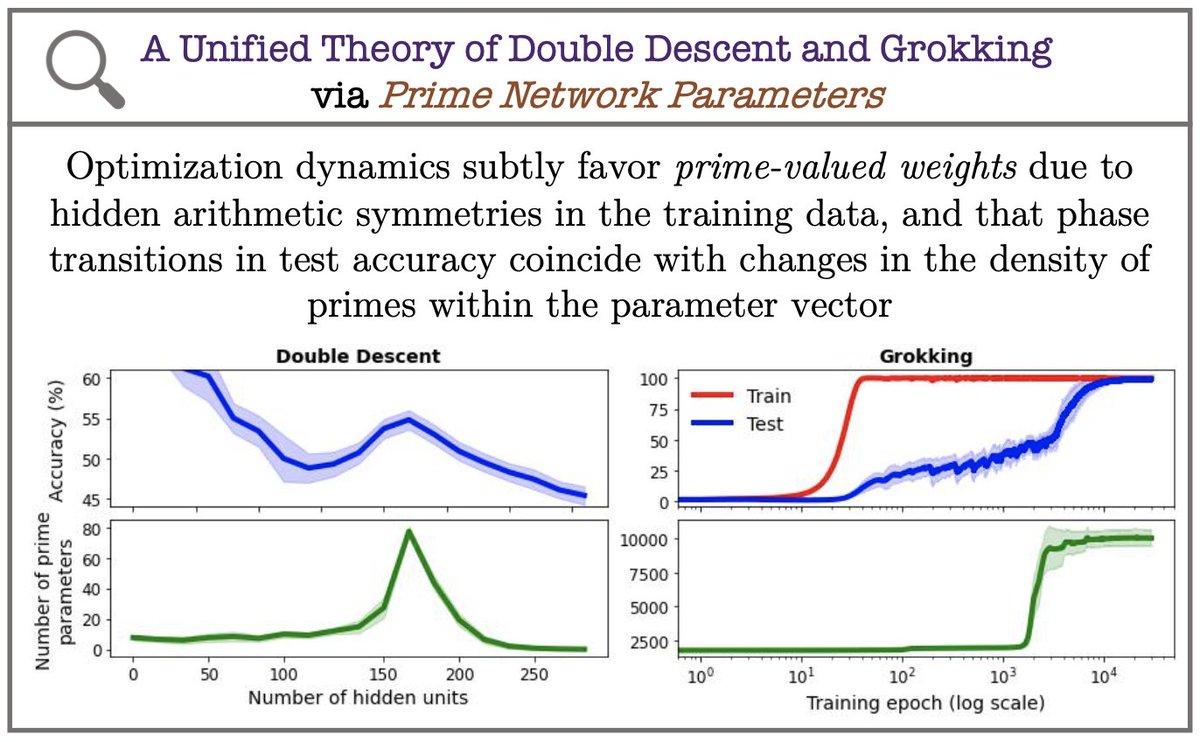
Our new ICML 2025 oral paper proposes a new unified theory of both Double Descent and Grokking, revealing that both of these deep learning phenomena can be understood as being caused by prime numbers in the network parameters 🤯🤯. 🧵[1/8]
1
0
8
If you're interested in RLHF and reward modeling check it out — and feel free to chat with Jef at #ICML2025!. 📄 🔗 🤝 Joint work with @ShenRaphael and @jeanfrancois287.

github.com
Active reward modeling with last layer Fisher Information (ICML'25) - YunyiShen/ARM-FI
1
4
10
We revive classical tools from the stats & experimental design literature. It turns out, many modern challenges already have elegant, sample-efficient solutions hidden there. All experiments were run efficiently on CPU-only machines, using our RM infra (open-sourced)!.
1
0
1
Our paper asks: How can we most effectively collect preference data for RM training?. We find that reward modeling is like drawing the contour of a mountain but using only pairwise comparisons. To trace it well, you need both local geometry and global structure 🏔️.
1
0
0
Unfortunately won't be able to attend #ICML2025 due to a long pending Canadian visa application — submitted in Oct 2023, still pending after 625 days 🙂↔️. That said, I'm excited to share our paper on Active Preference Learning & Understanding Reward Models 🧵👇

1
2
49
Now with Qwen’s RL-fine-tuning results, are we witnessing a quiet return of prompt optimization/engineering?. Now we have a 2-player game: users become “lazy prompters”, but the system prompts (e.g. thinking patterns) need to be highly optimized. Next: Bi-level optimization?

0
0
3
"Knowledge belongs to humanity, and is the torch which illuminates the world.".— Louis Pasteur. Especially for those contributed by the community.

0
0
7
AI cannot feel time, then how can it really understand humans?.
0
0
2
RT @jeanfrancois287: 📢New Paper on Process Reward Modelling 📢. Ever wondered about the pathologies of existing PRMs and how they could be r….
0
74
0
RT @jeanfrancois287: Happy to share that our paper on "Active Reward Modeling" has been accepted to ICML 2025! #ICML2025 . The part I like….
0
3
0
OpenReview Justice!.

I'm honestly a bit surprised but whatever! Worth celebrating .Here is our arxived paper. With .@HolarisSun. and .@jeanfrancois287 .

0
0
5


The oral sessions and poster sessions are happening at the same time, so it actually feels like the oral speakers are just talking to each other🤣.

0
0
6
3. Going beyond Games, Agentic interactions with the virtual world, with diverse tasks, can further enhance the capabilities of LLM-based AI systems. Those interactions are all EXPERIENCE from the agents themselves, rather than (bounded) knowledge from human.
0
0
1
2. Game. However, the human-centered AI systems in its current paradigm can never outperform human (ref: “Welcome to the era of experience, Silver & Sutton”). Games, or rule-based tasks — combined with self play — has great potential for the next breakthrough.
1
0
0
1. Inverse RL. We are now at the stage of “human-centered AI”, and human feedback or preferences is essential in providing REWARD SIGNALs for RL. From experience, we know WHENEVER there is a good reward, RL is able to optimize it to its limit.
1
0
0
Recently finished an article about 𝗧𝗵𝗲 𝗙𝗼𝘂𝗿-𝗦𝘁𝗲𝗽 𝗟𝗮𝗱𝗱𝗲𝗿 𝗳𝗿𝗼𝗺 𝗥𝗟 𝘁𝗼 𝗔𝗚𝗜. imo, those steps are.1. Inverse RL.2. Game Experience.3. Virtual Exp.4. Physical Exp.Still working on polishing it, but keen to discuss with old and new friends during ICLR🇸🇬!.🧵

1
1
6
Heading to 🇸🇬ICLR next week!.Can’t wait to catch up with old friends and meet new ones — let’s chat about RL, reward models, alignment, reasoning, and agents!. Also, fun fact🤓: Yunyi won’t be there physically, but his digital twin will be attending instead. Stay tuned!.
0
2
18