

Eran Malach
@EranMalach
Followers
626
Following
106
Media
21
Statuses
95
RT @GolowichNoah: I'll be attending ICML this week; come stop by our poster on length generalization in LLMs on Tuesday morning (poster ses….
openreview.net
Training large language models to predict beyond their training context lengths has drawn much attention in recent years, yet the principles driving such behavior of length generalization remain...
0
6
0
RT @orvieto_antonio: We have a new SSM theory paper, just accepted to COLT, revisiting recall properties of linear RNNs. It's surprising….
0
40
0
RT @MOSS_workshop: We are extending the deadline to May 26th 4:59pm PDT (11:59pm UTC). Thank you everyone for your interest & inquiries; we….
0
8
0
RT @SurbhiGoel_: Super excited to announce our ICML workshop on highlighting the power (and limitations?) of small-scale in the era of larg….
0
17
0
RT @MOSS_workshop: Announcing the 1st Workshop on Methods and Opportunities at Small Scale (MOSS) at @icmlconf 2025!. 🔗Website: https://t.c….
0
13
0
RT @BingbinL: Excited to announce MOSS, our ICML workshop focused on discoveries at small scale! We believe there's tremendous potential &….
0
15
0
RT @KempnerInst: New in the Deeper Learning blog: Kempner researchers show how VLMs speak the same semantic language across images and text….
kempnerinstitute.harvard.edu
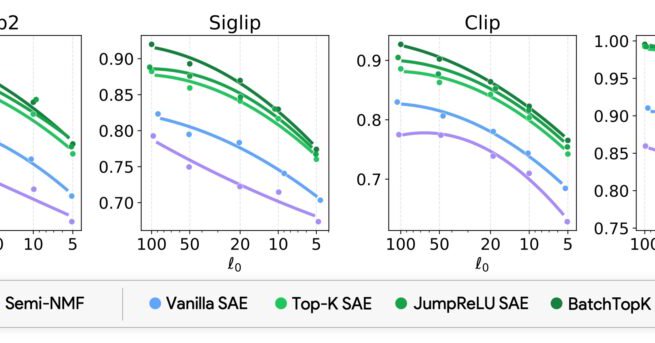
Using sparse autoencoders, the authors show that vision-language embeddings boil down to a small, stable dictionary of single-modality concepts that snap together into cross-modal bridges. This...
0
16
0
RT @KempnerInst: New in the Deeper Learning blog: Kempner researchers dive into how LLMs reason with the help of "backtracking," and explor….

kempnerinstitute.harvard.edu
Understanding whether backtracking enhances the reasoning ability of large language models helps us build smarter AI systems. This research clarifies when and how backtracking works best, guiding...
0
2
0
RT @natolambert: The best part of RLs focus in post-training right now is that the elicitation idea of post-training is a much better match….
0
32
0
Work with the amazing @rosieyzh, @alexmeterez, @ShamKakade6, @CPehlevan and Samy Jelassi. All our code is available at:
github.com
Code for "Echo Chamber: RL Post-training Amplifies Behaviors Learned in Pretraining" - rosieyzh/openrlhf-pretrain
0
0
4
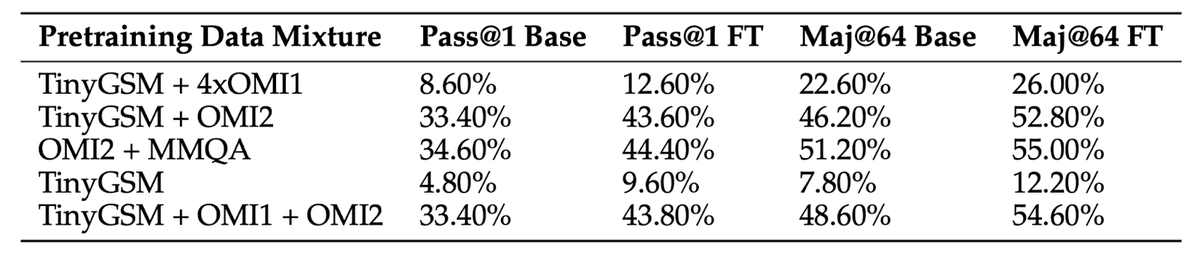
Finally, we also observe transfer between math dataset after RL fine-tuning. Specifically, running RL on the GSM8K (grade school math) training set significantly improves performance on the much harder MATH-500 evaluation.
1
1
3
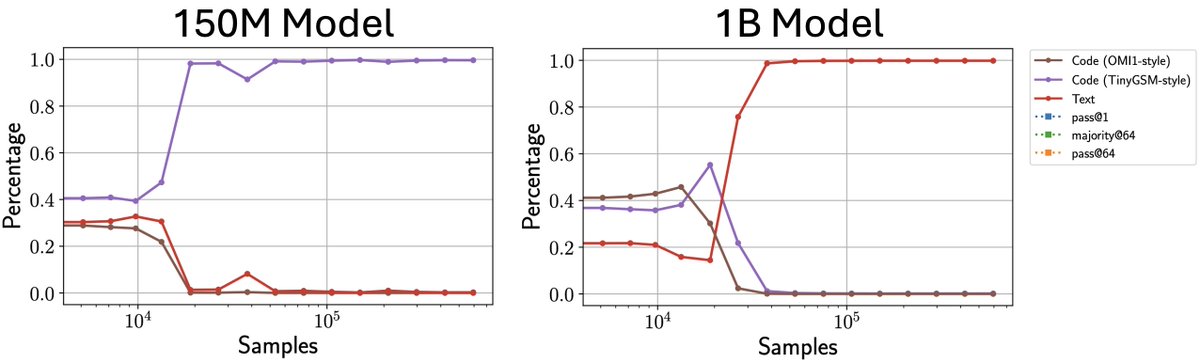
Additionally, we demonstrate that the choice of the optimal strategy depends on the model size. Small models struggle with arithmetics, so prefer to use code (which is executed externally). Larger models, however, converge to a strategy which uses natural language text.
1
1
4
While RL typically chooses the “best” (highest accuracy) strategy, we also discover failure cases, where the initial distribution biases RL towards the “wrong” strategy, causing accuracy to eventually collapse.
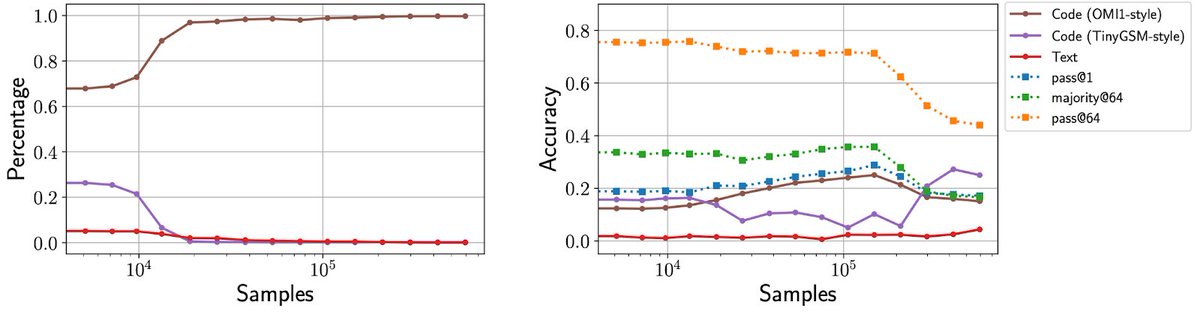
1
1
3
Our setting: we pretrain small (<=1B) models on different mixtures of math datasets which use different solution strategies (code or text), then run RL. We observe that while the “base” model generates a mixture of strategies, RL converges to a single dominant strategy.
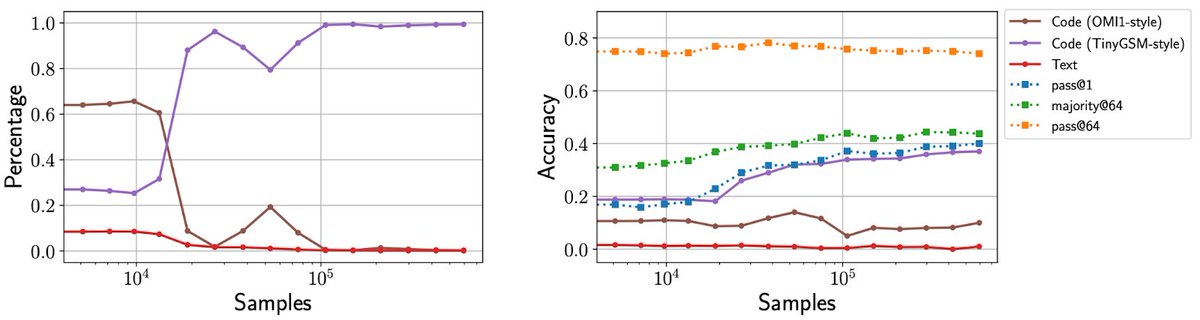
1
2
5
How does RL improve performance on math reasoning? Studying RL from pretrained models is hard, as behavior depends on choice of base model. 🚨 In our new work, we train models *from scratch* to study the effect of the data mix on the behavior of RL.

3
35
138
To backtrack or not to backtrack?.The answer depends on the nature of the reasoning problem!. Check out our paper new paper, led by @sunnytqin, with @elmelis and @SamyJelassi:. See thread below 👇👇.

arxiv.org
Recent advancements in large language models have significantly improved their reasoning abilities, particularly through techniques involving search and backtracking. Backtracking naturally scales...

🚨 New preprint! TL;DR: Backtracking is not the "holy grail" for smarter LLMs. It’s praised for helping models “fix mistakes” and improve reasoning—but is it really the best use of test-time compute? 🤔.
0
0
5
RT @rana_shahout: New paper at #ICLR2025!.Fast LLM inference = smart scheduling 🕒 but size-based scheduling (prioritizing short requests ov….
openreview.net
Efficient scheduling is crucial for interactive Large Language Model (LLM) applications, where low request completion time directly impacts user engagement. Size-based scheduling algorithms like...
0
15
0
RT @KempnerInst: The 4:30pm poster session today at #NeurIPS2024 will feature "The Evolution of Statistical Induction Heads: In-Context Lea….
0
4
0
Presenting this work at #NeurIPS2024 today 4:30pm session (poster #4807, east). Come by to hear about auto-regressive decision trees for language modeling!.

New paper at #NeurIPS2024!. In which we try to make a *small yet interpretable* model work. We use decision trees, which offer a fully transparent decision-making process, in an autoregressive manner to do language tasks. paper: (1/n)

0
0
7
Will be presenting this work at #NeurIPS2024, today 11am, poster #2311. Come visit us!.

Modern generative models are trained to imitate human experts, but can they actually beat those experts? Our new paper uses imitative chess agents to explore when a model can "transcend" its training distribution and outperform every human it's trained on.

1
5
10