
Devaansh Gupta
@DevaanshGupta1
Followers
29
Following
42
Media
1
Statuses
10
MS CS @ UCLA | Natural Language Reasoning
Joined December 2021
RT @essential_ai: [1/5]. 🚀 Meet Essential-Web v1.0, a 24-trillion-token pre-training dataset with rich metadata built to effortlessly curat….
0
54
0
Thanks for sharing our d1 paper!. Check out the code as well:
github.com
Official Implementation for the paper "d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning" - dllm-reasoning/d1

1. Lavida: 2. Mmada: 3. dKv cache: 4. d1 (scaling reasoning): 5. Llada:
0
0
3

RT @VentureBeat: 30 seconds vs. 3: The d1 reasoning framework that's slashing AI response times .
0
3
0
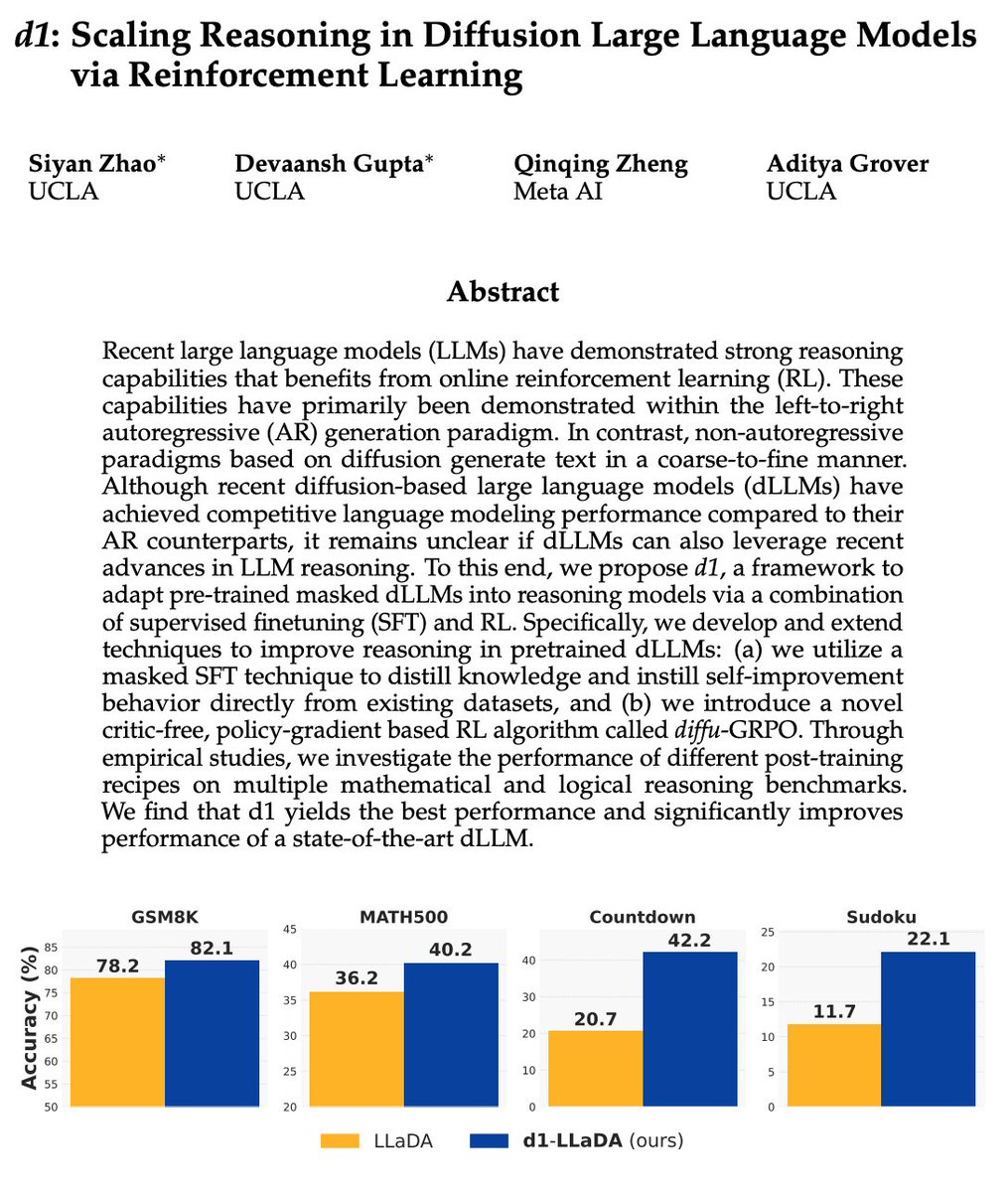
Our arxiv is out!.

arxiv.org
Recent large language models (LLMs) have demonstrated strong reasoning capabilities that benefits from online reinforcement learning (RL). These capabilities have primarily been demonstrated...

Introducing d1🚀 — the first framework that applies reinforcement learning to improve reasoning in masked diffusion LLMs (dLLMs). Combining masked SFT with a novel form of policy gradient algorithm, d1 significantly boosts the performance of pretrained dLLMs like LLaDA.
0
0
2
Super excited for this release! . We propose d1, the first framework to convert pre-trained dLLMs into strong reasoning models via RL!🔥. Thank you for all the efforts @siyan_zhao @qqyuzu @adityagrover_ !. Project:
Introducing d1🚀 — the first framework that applies reinforcement learning to improve reasoning in masked diffusion LLMs (dLLMs). Combining masked SFT with a novel form of policy gradient algorithm, d1 significantly boosts the performance of pretrained dLLMs like LLaDA.
0
0
4
Huge thanks to @dstevewei @its_Kharbanda @jzhou_jz @Wanhua_Ethan_Li @HarvardVCG for seeing it through!.
#ICCV2023 Presenting CLIPTrans, a framework to finetune pretrained models for multilingual tasks with multimodal data. Effectively leveraging images during training, it surpasses its NMT baseline(mBART) and furthers the SOTA in Multimodal MT!.Project:
0
0
2
#ICCV2023 Presenting CLIPTrans, a framework to finetune pretrained models for multilingual tasks with multimodal data. Effectively leveraging images during training, it surpasses its NMT baseline(mBART) and furthers the SOTA in Multimodal MT!.Project:
0
3
4