

The Data Forge
@DataForgeX
Followers
6
Following
4
Media
0
Statuses
140
Exploring Big Data, Cloud & Analytics | Data Engineering insights, projects & tutorials | Read more on Medium👉 https://t.co/4xDgdb1O7v
Joined September 2025
Welcome to The Data Forge! 🔥 Sharing insights, projects & tutorials on Data Engineering, Big Data & Cloud. Long-form posts live here 👉 https://t.co/CI5wNDPvaf Follow along if you want to grow as a data engineer 🚀 #DataEngineering #BigData #CloudComputing #DataScience #ETL

thedataforge.medium.com
Read writing from The Data Forge on Medium. Data Engineer | Exploring Big Data, Cloud, and Analytics | Sharing insights, tutorials, and projects -By Gautam Pande
0
0
2
D86 Your data stack should be: Simple > Fancy Reliable > Cool Maintainable > Trendy If your pipeline needs a hero to keep it alive— it’s already broken #DataEngineering #BigData #DataPipelines #DataArchitecture #ETL #AnalyticsEngineering #TechDebt #ScalableSystems #ProductionData
0
0
1
🧠New blog! 50 Advanced SQL interview questions every Data Engineer should know. Window functions,joins,time-series,query optimization, CTE pipelines & how SQL breaks at scale. This is senior-level SQL-not LeetCode fluff. 🔗 https://t.co/Fb574s6Lf4
#DataEngineering #SQL #Interview
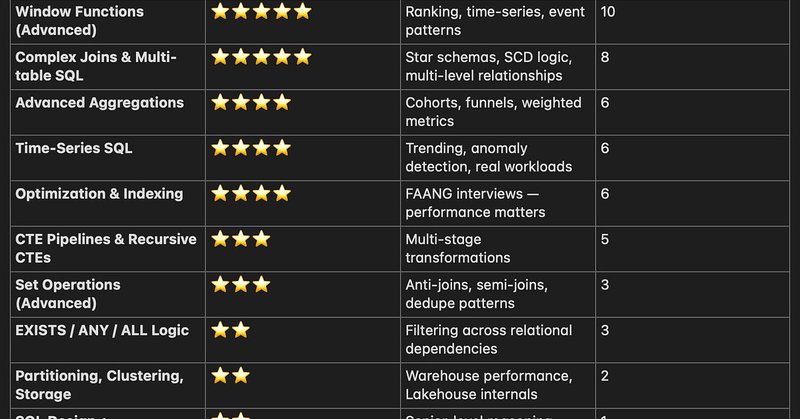
thedataforge.medium.com
For real-world Data Engineering, Big Data, Analytics Engineering & Lakehouse roles.
0
0
1
D85 Kafka tip🚨 Keep message size < 1MB. Large messages cause: →broker memory pressure →slower replication →higher GC pauses →consumer lag spikes Kafka loves events, not files. Store blobs elsewhere. Stream pointers. #Kafka #ApacheKafka #Streaming #DataEngineering #BigData
0
0
1
D84 If your Spark job runs slow at scale… Try reducing the number of partitions More partitions ≠ more speed. Too many partitions = →scheduler overhead →tiny tasks →wasted CPU #ApacheSpark #SparkOptimization #DataEngineering #BigData #DistributedSystems #ETL #BatchProcessing
0
0
1
🏗️New blog! Medallion Architecture (Bronze → Silver → Gold) explained with real examples. If your pipelines break, dashboards disagree, or schemas drift — this fixes 80% of that pain. 🔗 https://t.co/Cns0s7lU1K
#DataEngineering #Lakehouse #DeltaLake #ETL #ApacheSpark #Databricks
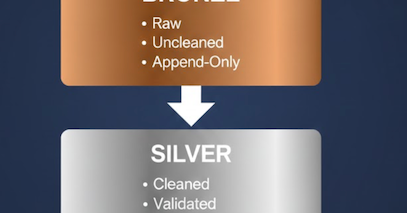
thedataforge.medium.com
The cleanest way to structure a Lakehouse so your data never turns into a swamp.
0
0
1
D83 Spark’s Tungsten engine = Better codegen + memory management. It’s why DataFrames are faster than RDDs. #ApacheSpark #BigData #SparkSQL #DataEngineering #DistributedSystems #PerformanceOptimization #JVM #DataFrames
0
0
1
D82 Data drift is real. Always track: → schema drift → value drift → distribution drift #DataQuality #Data #MLMonitoring #MLOps #DataPipelines #AnalyticsEngineering #BigData #AIEngineering #DataEngineering #DataEngineer
0
0
1
⚔️New blog! If your company still runs a data lake and a warehouse, you’re paying the stupidity tax every day A brutally honest breakdown of #DataLakes vs #Warehouses vs #Lakehouses-why the two-platform era is dying and why Lakehouse is the 2026 default. 🔗 https://t.co/aNkmQ8TNcJ
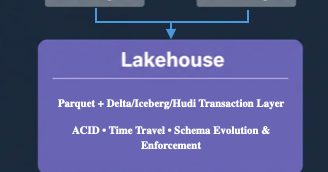
thedataforge.medium.com
The only guide you need to truly understand these three architectures — without marketing buzzwords.
0
0
1
D81 Kafka consumers should be in groups. Not grouped = no parallelism. Grouped badly = duplicates. #Kafka
#DataEngineering
#KafkaConsumers
#KafkaStreams
#EventStreaming
#DistributedSystems
#StreamingData
#BigData
#ApacheKafka
#RealTimeData
#DataPipelines
#ScalableSystems
0
0
1
D80 Spark UI Tip: Watch executor time vs GC time. High GC = memory pressure → bad partitioning, oversized objects, or wrong caching. #ApacheSpark #SparkUI #SparkPerformance #BigData #DataEngineering #JVM #GarbageCollection #SparkOptimization
0
0
1
🚀New blog! The #ModernDataStack(2020→2026)explained. Why the future is: •#Lakehouse-first •Streaming-native •#AI-augmented #ETL •Event-driven #orchestration •Semantic layers over #SQL chaos Plus:a mic-drop 2028 prediction👀 🔗 https://t.co/i9xozVvWyK
#DataEngineering #Data

thedataforge.medium.com
Tools, patterns, and how the stack evolved from 2020 → 2026
0
0
1
D79 SQL is 50 years old — and still the most valuable data skill. Learn it deeply. #SQL #DataEngineering #AnalyticsEngineering #DataAnalytics #DatabaseSystems #BigData #TechCareers #DataSkills
0
0
1
D78 Airflow is great. But overusing Airflow makes systems fragile. Use it for orchestration, not business logic. #Airflow #ApacheAirflow #DataEngineering #DataPipelines #ETL #WorkflowOrchestration #BigData #ModernDataStack #AnalyticsEngineering
0
0
1
🚀New blog! 50 #SQL interview questions every #DataEngineer must know (Foundational Edition) #Joins, #windowfunctions, #NULL traps,#CTEs, aggregations — the stuff real interviews test. If you’re prepping for DE roles in 2026, this is your SQL checklist👇 🔗 https://t.co/gk2QsPFidG
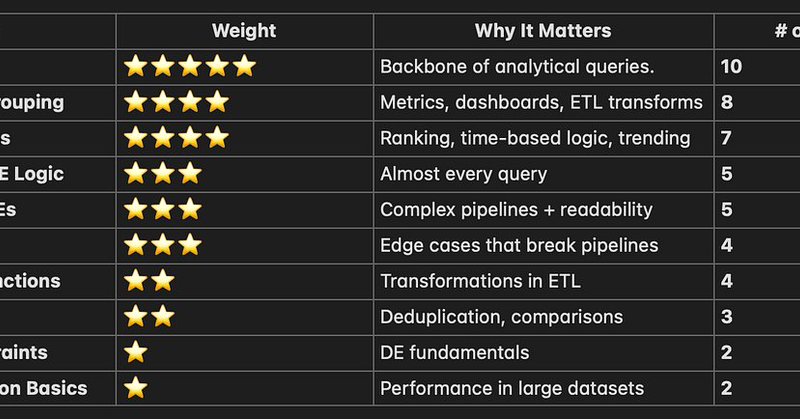
thedataforge.medium.com
The essential SQL foundation every data engineer is expected to master.
0
0
1
D77 Data lakes fail for 3 reasons: ❌ No governance ❌ No schema checks ❌ No lineage Handle these → success. #DataLake #BigData #DataGovernance #DataQuality #DataLineage #Lakehouse #DataEngineering #ETL #ModernDataStack #EnterpriseData #Data #DataScientist #DataScience
0
1
1
D76 Structured Streaming handles late data like a champ. Watermarking = safety net for real-time systems. #SparkStreaming #BigData #ApacheSpark #StreamingAnalytics #RealTimeData #DataEngineering #ETL #EventTime #StreamingData #Lakehouse
0
0
1
🚀New blog Most data engineers stay invisible their whole careers. But the ones who win? They write publicly. I broke down the exact system I used to build a DE brand:niche→voice→projects→insights→consistency. 🔗 https://t.co/UKDyUAmHgy
#DataEngineering #PersonalBranding #Data
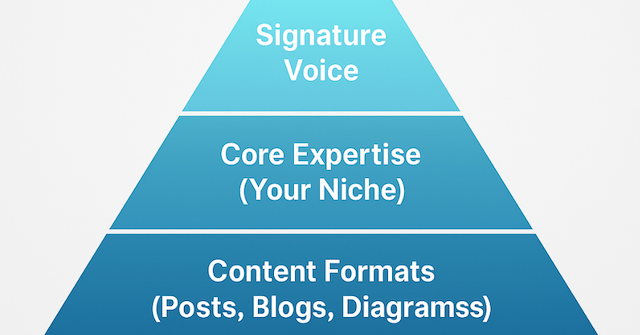
thedataforge.medium.com
This is the roadmap I wish I had when I started posting online as a data engineer.
0
0
1
D75 Your first Spark job will run slow. Your fifth will run fast. Your fiftieth will run cheap. Experience = efficiency. #ApacheSpark #BigData #DataEngineering #PySpark #SparkOptimization #DistributedComputing #CloudData
0
0
2
D73 Parquet + Spark = ❤�� If you're still using CSV for big data, you're burning compute, storage, and time. Columnar > Row formats. Always. #Parquet #BigData #ApacheSpark #DataEngineering #ETL #DataLakes #CloudData #DeltaLake #PySpark #PerformanceEngineering
0
0
1
🚀New Blog! How #Lakehouse + #AI will replace 70% of ETL The next decade of #DataEngineering is automation-first: self-healing pipelines, smarter SQL, real-time ML, and DEs shifting to architecture + AI orchestration. 🔗 https://t.co/sMu6wbtqPk
#ETL #BigData #DeltaLake #MLOps #ML

thedataforge.medium.com
Why the next decade of data engineering belongs to the Lakehouse + AI revolution
0
0
1