

🦉DVC
@DVCorg
Followers
5K
Following
3K
Media
633
Statuses
2K
Open source tool for data, models, & experiment versioning for ML projects. Join our stellar community https://t.co/RTCIKrZlmf for help, support and insights.
San Francisco, CA
Joined May 2018
- A more scalable approach could involve integrating with open table formats like Delta or Apache Iceberg. (we definitely plan to add Iceberg support, and Studio - our SaaS offers ClickHouse support that scales to billions rows scale).
0
0
4
Key takeaways:. - Managing video metadata is more complex than it seems; DataChain aims to simplify this. - While DataChain offers useful features, the use of SQLite within open source version, raises concerns about scalability for larger datasets, and cross collaboration.
1
0
1
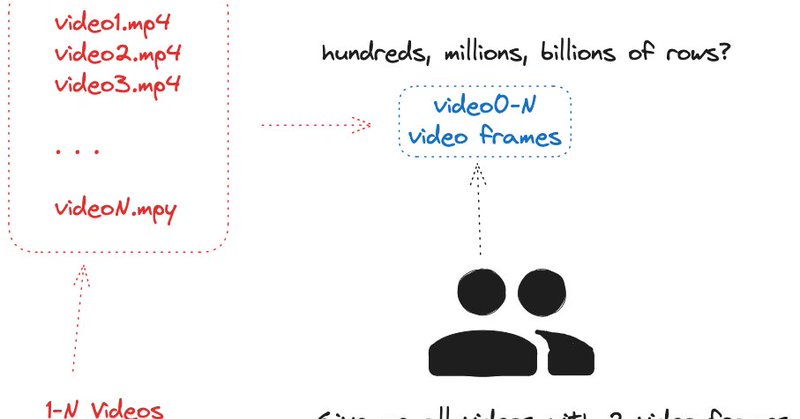
"Metadata marts could play a key role in making video data more accessible and structured for model training and analysis" - Simon Thelin (@synthesiaIO, creator of the DataPains blog) reviewed DataChain 👇.
1
3
4
@PyData @JulianWgs ✅ Finally, metrics, parameters are captured and also attached to Git and iterations - to compare, visualize result;.
0
0
0
@PyData @JulianWgs The usual DVC building blocks are utilized to achieve this:. ✅ DVC data versioning makes sure input data is saved and attached to an iteration and can be restored or access anytime in the future;.✅ Lightweight CLI pipelines declaratively describe and run data processing.
1
0
0
@PyData @JulianWgs suggests using DVC to streamline simulation iterations and track results. DVC keeps it lightweight (no need to run servers and such - CLI, Git, basic Python) while making the whole process way more manageable and scalable.
1
0
1
Watch an excellent PyData Berlin talk by @JulianWgs (@VW ) on automating and managing fluid simulations with Python and DVC. 🧵

1
1
3
@photoroom_app @EliotAndres DataChain is an open source library 🔗 (and SaaS platform for collaboration and scale) that implements this idea at scale + our goal was make it easy to use by ML teams.
1
0
0
@photoroom_app @EliotAndres 🐘 Smaller scale - DVC + CSV files, or Postgres + some custom ETL to feed it.
1
0
0
Some examples and ideas we've seen:. 🎥 @photoroom_app - see the link to the talk by @EliotAndres below.🧊 Iceberg for metadata (and sometimes binaries) + Spark - is one of the default choices (but usually requires data engineering skills / team).
1
0
1
All efficient AI teams have an excellent data hygiene - they utilize databases, ETLs, custom scripts / tools to effectively build a metadata layer on top of their binary data (videos, images, etc). This is essential to make better datasets.
1
0
0
DataChain organizes and makes your AI data queryable! What does it mean? Why? 👇
1
2
7
🤏 Data access. Pre-fetch, batching, caching, streaming - different workloads require different ways of using data.
0
0
1
⚙️ Distributed compute that runs close to the data to compute Python-based UDFs.
1
0
1
⚡ Use warehouses under the hood (e.g. ClickHouse) to store metadata and perform as many operations inside it (e.g. filters).
1
0
1
☁️ Never copy data. Store references to files instead. (while still preserving versioning, data loading, efficient processing).
1
0
1